 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipeline Inspection, Visualization, and Interoperability in PyTerrier
Jan 24, 2026PyTerrier provides a declarative framework for building and experimenting with Information Retrieval (IR) pipelines. In this demonstration, we highlight several recent pipeline operations that improve their ability to be programmatically inspected, visualized, and integrated with other tools (via the Model Context Protocol, MCP). These capabilities aim to make it easier for researchers, students, and AI agents to understand and use a wide array of IR pipelines.
Predicting Retrieval Utility and Answer Quality in Retrieval-Augmented Generation
Jan 20, 2026The quality of answers generated by large language models (LLMs) in retrieval-augmented generation (RAG) is largely influenced by the contextual information contained in the retrieved documents. A key challenge for improving RAG is to predict both the utility of retrieved documents -- quantified as the performance gain from using context over generation without context -- and the quality of the final answers in terms of correctness and relevance. In this paper, we define two prediction tasks within RAG. The first is retrieval performance prediction (RPP), which estimates the utility of retrieved documents. The second is generation performance prediction (GPP), which estimates the final answer quality. We hypothesise that in RAG, the topical relevance of retrieved documents correlates with their utility, suggesting that query performance prediction (QPP) approaches can be adapted for RPP and GPP. Beyond these retriever-centric signals, we argue that reader-centric features, such as the LLM's perplexity of the retrieved context conditioned on the input query, can further enhance prediction accuracy for both RPP and GPP. Finally, we propose that features reflecting query-agnostic document quality and readability can also provide useful signals to the predictions. We train linear regression models with the above categories of predictors for both RPP and GPP. Experiments on the Natural Questions (NQ) dataset show that combining predictors from multiple feature categories yields the most accurate estimates of RAG performance.
Balancing Accuracy and Novelty with Sub-Item Popularity
Aug 07, 2025In the realm of music recommendation, sequential recommenders have shown promise in capturing the dynamic nature of music consumption. A key characteristic of this domain is repetitive listening, where users frequently replay familiar tracks. To capture these repetition patterns, recent research has introduced Personalised Popularity Scores (PPS), which quantify user-specific preferences based on historical frequency. While PPS enhances relevance in recommendation, it often reinforces already-known content, limiting the system's ability to surface novel or serendipitous items - key elements for fostering long-term user engagement and satisfaction. To address this limitation, we build upon RecJPQ, a Transformer-based framework initially developed to improve scalability in large-item catalogues through sub-item decomposition. We repurpose RecJPQ's sub-item architecture to model personalised popularity at a finer granularity. This allows us to capture shared repetition patterns across sub-embeddings - latent structures not accessible through item-level popularity alone. We propose a novel integration of sub-ID-level personalised popularity within the RecJPQ framework, enabling explicit control over the trade-off between accuracy and personalised novelty. Our sub-ID-level PPS method (sPPS) consistently outperforms item-level PPS by achieving significantly higher personalised novelty without compromising recommendation accuracy. Code and experiments are publicly available at https://github.com/sisinflab/Sub-id-Popularity.
Measuring Hypothesis Testing Errors in the Evaluation of Retrieval Systems
Jul 10, 2025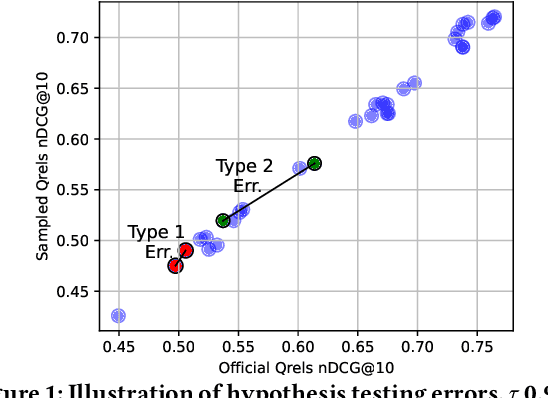

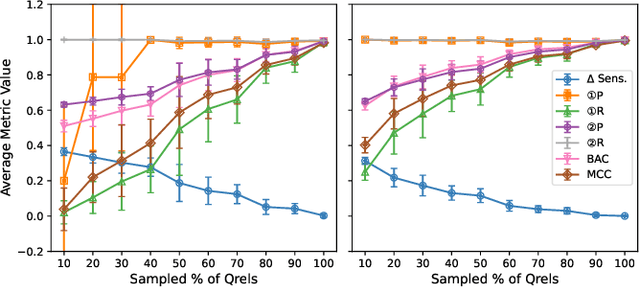

The evaluation of Information Retrieval (IR) systems typically uses query-document pairs with corresponding human-labelled relevance assessments (qrels). These qrels are used to determine if one system is better than another based on average retrieval performance. Acquiring large volumes of human relevance assessments is expensive. Therefore, more efficient relevance assessment approaches have been proposed, necessitating comparisons between qrels to ascertain their efficacy. Discriminative power, i.e. the ability to correctly identify significant differences between systems, is important for drawing accurate conclusions on the robustness of qrels. Previous work has measured the proportion of pairs of systems that are identified as significantly different and has quantified Type I statistical errors. Type I errors lead to incorrect conclusions due to false positive significance tests. We argue that also identifying Type II errors (false negatives) is important as they lead science in the wrong direction. We quantify Type II errors and propose that balanced classification metrics, such as balanced accuracy, can be used to portray the discriminative power of qrels. We perform experiments using qrels generated using alternative relevance assessment methods to investigate measuring hypothesis testing errors in IR evaluation. We find that additional insights into the discriminative power of qrels can be gained by quantifying Type II errors, and that balanced classification metrics can be used to give an overall summary of discriminative power in one, easily comparable, number.
Constructing and Evaluating Declarative RAG Pipelines in PyTerrier
Jun 12, 2025


Search engines often follow a pipeline architecture, where complex but effective reranking components are used to refine the results of an initial retrieval. Retrieval augmented generation (RAG) is an exciting application of the pipeline architecture, where the final component generates a coherent answer for the users from the retrieved documents. In this demo paper, we describe how such RAG pipelines can be formulated in the declarative PyTerrier architecture, and the advantages of doing so. Our PyTerrier-RAG extension for PyTerrier provides easy access to standard RAG datasets and evaluation measures, state-of-the-art LLM readers, and using PyTerrier's unique operator notation, easy-to-build pipelines. We demonstrate the succinctness of indexing and RAG pipelines on standard datasets (including Natural Questions) and how to build on the larger PyTerrier ecosystem with state-of-the-art sparse, learned-sparse, and dense retrievers, and other neural rankers.
Efficient Recommendation with Millions of Items by Dynamic Pruning of Sub-Item Embeddings
May 01, 2025A large item catalogue is a major challenge for deploying modern sequential recommender models, since it makes the memory footprint of the model large and increases inference latency. One promising approach to address this is RecJPQ, which replaces item embeddings with sub-item embeddings. However, slow inference remains problematic because finding the top highest-scored items usually requires scoring all items in the catalogue, which may not be feasible for large catalogues. By adapting dynamic pruning concepts from document retrieval, we propose the RecJPQPrune dynamic pruning algorithm to efficiently find the top highest-scored items without computing the scores of all items in the catalogue. Our RecJPQPrune algorithm is safe-up-to-rank K since it theoretically guarantees that no potentially high-scored item is excluded from the final top K recommendation list, thereby ensuring no impact on effectiveness. Our experiments on two large datasets and three recommendation models demonstrate the efficiency achievable using RecJPQPrune: for instance, on the Tmall dataset with 2.2M items, we can reduce the median model scoring time by 64 times compared to the Transformer Default baseline, and 5.3 times compared to a recent scoring approach called PQTopK. Overall, this paper demonstrates the effective and efficient inference of Transformer-based recommendation models at catalogue scales not previously reported in the literature. Indeed, our RecJPQPrune algorithm can score 2 million items in under 10 milliseconds without GPUs, and without relying on Approximate Nearest Neighbour (ANN) techniques.
On Precomputation and Caching in Information Retrieval Experiments with Pipeline Architectures
Apr 14, 2025Modern information retrieval systems often rely on multiple components executed in a pipeline. In a research setting, this can lead to substantial redundant computations (e.g., retrieving the same query multiple times for evaluating different downstream rerankers). To overcome this, researchers take cached "result" files as inputs, which represent the output of another pipeline. However, these result files can be brittle and can cause a disconnect between the conceptual design of the pipeline and its logical implementation. To overcome both the redundancy problem (when executing complete pipelines) and the disconnect problem (when relying on intermediate result files), we describe our recent efforts to improve the caching capabilities in the open-source PyTerrier IR platform. We focus on two main directions: (1) automatic implicit caching of common pipeline prefixes when comparing systems and (2) explicit caching of operations through a new extension package, pyterrier-caching. These approaches allow for the best of both worlds: pipelines can be fully expressed end-to-end, while also avoiding redundant computations between pipelines.
KiRAG: Knowledge-Driven Iterative Retriever for Enhancing Retrieval-Augmented Generation
Feb 25, 2025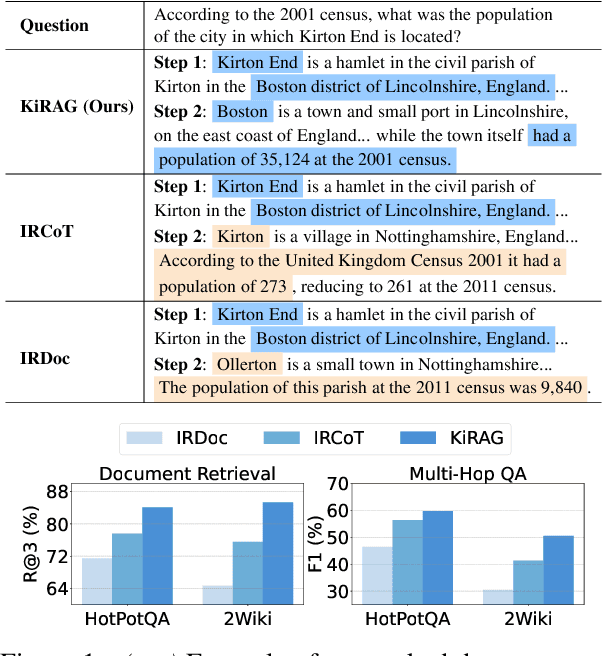
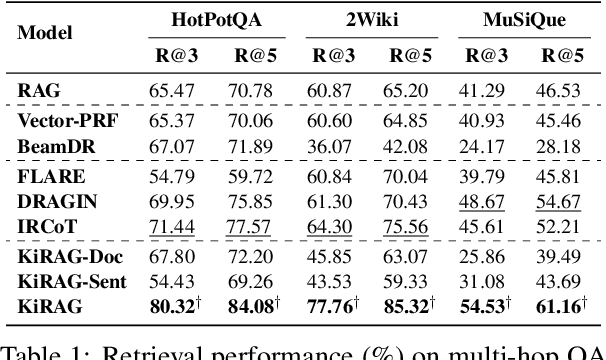
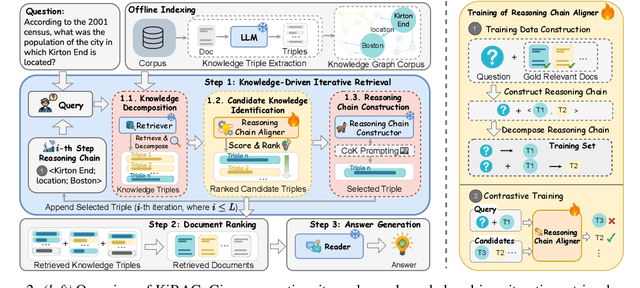
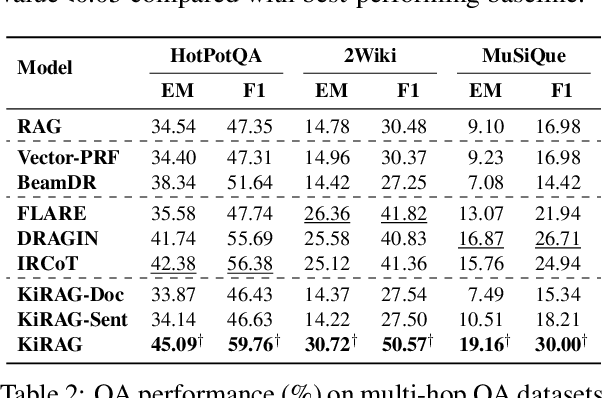
Iterative retrieval-augmented generation (iRAG) models offer an effective approach for multi-hop question answering (QA). However, their retrieval process faces two key challenges: (1) it can be disrupted by irrelevant documents or factually inaccurate chain-of-thoughts; (2) their retrievers are not designed to dynamically adapt to the evolving information needs in multi-step reasoning, making it difficult to identify and retrieve the missing information required at each iterative step. Therefore, we propose KiRAG, which uses a knowledge-driven iterative retriever model to enhance the retrieval process of iRAG. Specifically, KiRAG decomposes documents into knowledge triples and performs iterative retrieval with these triples to enable a factually reliable retrieval process. Moreover, KiRAG integrates reasoning into the retrieval process to dynamically identify and retrieve knowledge that bridges information gaps, effectively adapting to the evolving information needs. Empirical results show that KiRAG significantly outperforms existing iRAG models, with an average improvement of 9.40% in R@3 and 5.14% in F1 on multi-hop QA.
Is Relevance Propagated from Retriever to Generator in RAG?
Feb 20, 2025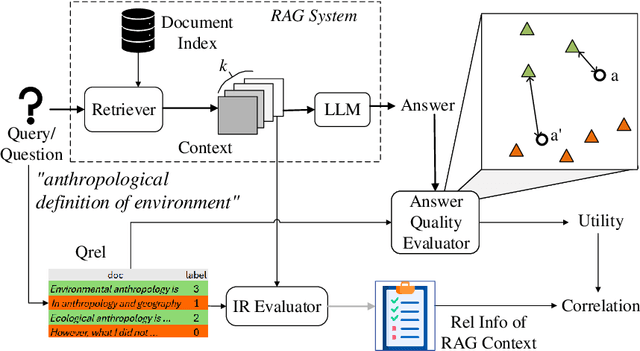
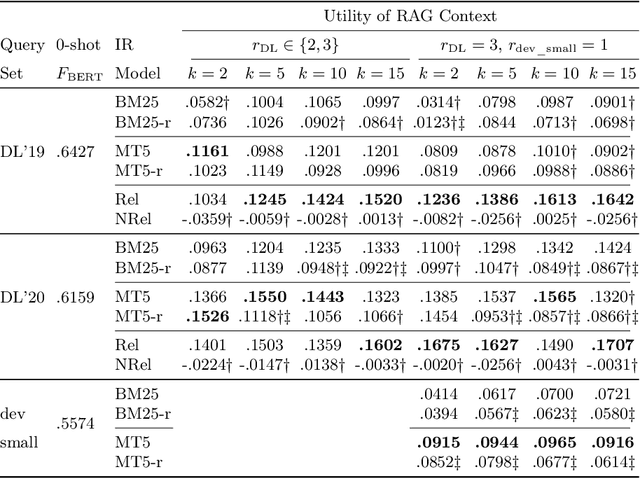
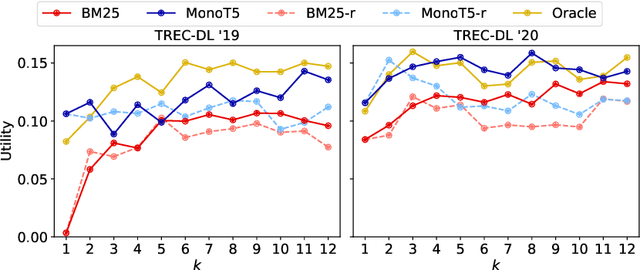
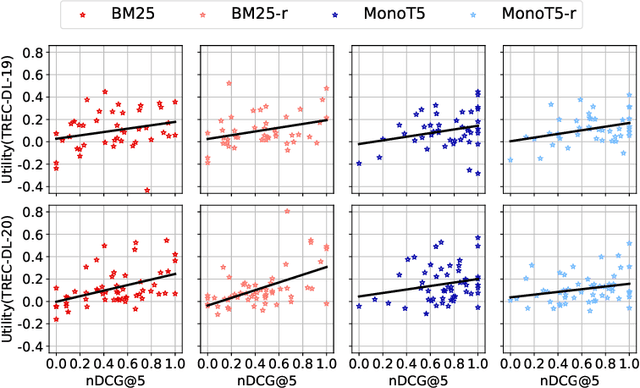
Retrieval Augmented Generation (RAG) is a framework for incorporating external knowledge, usually in the form of a set of documents retrieved from a collection, as a part of a prompt to a large language model (LLM) to potentially improve the performance of a downstream task, such as question answering. Different from a standard retrieval task's objective of maximising the relevance of a set of top-ranked documents, a RAG system's objective is rather to maximise their total utility, where the utility of a document indicates whether including it as a part of the additional contextual information in an LLM prompt improves a downstream task. Existing studies investigate the role of the relevance of a RAG context for knowledge-intensive language tasks (KILT), where relevance essentially takes the form of answer containment. In contrast, in our work, relevance corresponds to that of topical overlap between a query and a document for an information seeking task. Specifically, we make use of an IR test collection to empirically investigate whether a RAG context comprised of topically relevant documents leads to improved downstream performance. Our experiments lead to the following findings: (a) there is a small positive correlation between relevance and utility; (b) this correlation decreases with increasing context sizes (higher values of k in k-shot); and (c) a more effective retrieval model generally leads to better downstream RAG performance.
Beyond Questions: Leveraging ColBERT for Keyphrase Search
Dec 04, 2024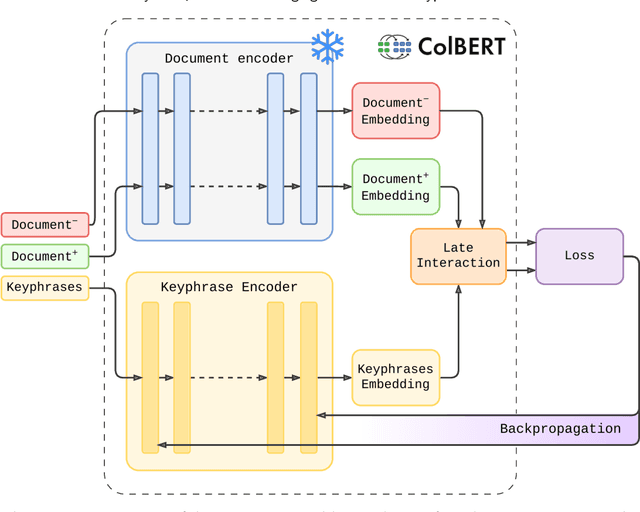
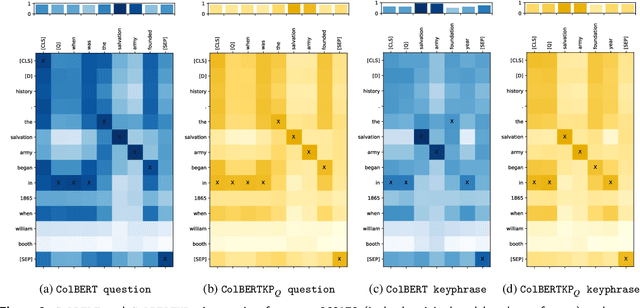
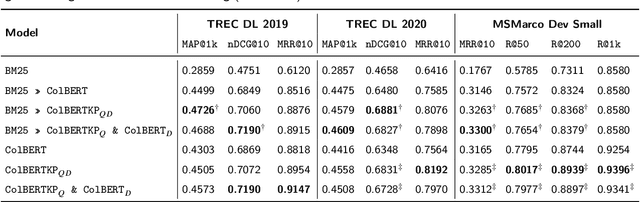
While question-like queries are gaining popularity and search engines' users increasingly adopt them, keyphrase search has traditionally been the cornerstone of web search. This query type is also prevalent in specialised search tasks such as academic or professional search, where experts rely on keyphrases to articulate their information needs. However, current dense retrieval models often fail with keyphrase-like queries, primarily because they are mostly trained on question-like ones. This paper introduces a novel model that employs the ColBERT architecture to enhance document ranking for keyphrase queries. For that, given the lack of large keyphrase-based retrieval datasets, we first explore how Large Language Models can convert question-like queries into keyphrase format. Then, using those keyphrases, we train a keyphrase-based ColBERT ranker (ColBERTKP_QD) to improve the performance when working with keyphrase queries. Furthermore, to reduce the training costs associated with training the full ColBERT model, we investigate the feasibility of training only a keyphrase query encoder while keeping the document encoder weights static (ColBERTKP_Q). We assess our proposals' ranking performance using both automatically generated and manually annotated keyphrases. Our results reveal the potential of the late interaction architecture when working under the keyphrase search scenario.