 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs for estimating positional bias in logged interaction data
Sep 03, 2025



Recommender and search systems commonly rely on Learning To Rank models trained on logged user interactions to order items by predicted relevance. However, such interaction data is often subject to position bias, as users are more likely to click on items that appear higher in the ranking, regardless of their actual relevance. As a result, newly trained models may inherit and reinforce the biases of prior ranking models rather than genuinely improving relevance. A standard approach to mitigate position bias is Inverse Propensity Scoring (IPS), where the model's loss is weighted by the inverse of a propensity function, an estimate of the probability that an item at a given position is examined. However, accurate propensity estimation is challenging, especially in interfaces with complex non-linear layouts. In this paper, we propose a novel method for estimating position bias using Large Language Models (LLMs) applied to logged user interaction data. This approach offers a cost-effective alternative to online experimentation. Our experiments show that propensities estimated with our LLM-as-a-judge approach are stable across score buckets and reveal the row-column effects of Viator's grid layout that simpler heuristics overlook. An IPS-weighted reranker trained with these propensities matches the production model on standard NDCG@10 while improving weighted NDCG@10 by roughly 2%. We will verify these offline gains in forthcoming live-traffic experiments.
eSASRec: Enhancing Transformer-based Recommendations in a Modular Fashion
Aug 08, 2025Since their introduction, Transformer-based models, such as SASRec and BERT4Rec, have become common baselines for sequential recommendations, surpassing earlier neural and non-neural methods. A number of following publications have shown that the effectiveness of these models can be improved by, for example, slightly updating the architecture of the Transformer layers, using better training objectives, and employing improved loss functions. However, the additivity of these modular improvements has not been systematically benchmarked - this is the gap we aim to close in this paper. Through our experiments, we identify a very strong model that uses SASRec's training objective, LiGR Transformer layers, and Sampled Softmax Loss. We call this combination eSASRec (Enhanced SASRec). While we primarily focus on realistic, production-like evaluation, in our preliminarily study we find that common academic benchmarks show eSASRec to be 23% more effective compared to the most recent state-of-the-art models, such as ActionPiece. In our main production-like benchmark, eSASRec resides on the Pareto frontier in terms of the accuracy-coverage tradeoff (alongside the recent industrial models HSTU and FuXi. As the modifications compared to the original SASRec are relatively straightforward and no extra features are needed (such as timestamps in HSTU), we believe that eSASRec can be easily integrated into existing recommendation pipelines and can can serve as a strong yet very simple baseline for emerging complicated algorithms. To facilitate this, we provide the open-source implementations for our models and benchmarks in repository https://github.com/blondered/transformer_benchmark
Efficient Recommendation with Millions of Items by Dynamic Pruning of Sub-Item Embeddings
May 01, 2025A large item catalogue is a major challenge for deploying modern sequential recommender models, since it makes the memory footprint of the model large and increases inference latency. One promising approach to address this is RecJPQ, which replaces item embeddings with sub-item embeddings. However, slow inference remains problematic because finding the top highest-scored items usually requires scoring all items in the catalogue, which may not be feasible for large catalogues. By adapting dynamic pruning concepts from document retrieval, we propose the RecJPQPrune dynamic pruning algorithm to efficiently find the top highest-scored items without computing the scores of all items in the catalogue. Our RecJPQPrune algorithm is safe-up-to-rank K since it theoretically guarantees that no potentially high-scored item is excluded from the final top K recommendation list, thereby ensuring no impact on effectiveness. Our experiments on two large datasets and three recommendation models demonstrate the efficiency achievable using RecJPQPrune: for instance, on the Tmall dataset with 2.2M items, we can reduce the median model scoring time by 64 times compared to the Transformer Default baseline, and 5.3 times compared to a recent scoring approach called PQTopK. Overall, this paper demonstrates the effective and efficient inference of Transformer-based recommendation models at catalogue scales not previously reported in the literature. Indeed, our RecJPQPrune algorithm can score 2 million items in under 10 milliseconds without GPUs, and without relying on Approximate Nearest Neighbour (ANN) techniques.
Efficient Inference of Sub-Item Id-based Sequential Recommendation Models with Millions of Items
Aug 19, 2024Transformer-based recommender systems, such as BERT4Rec or SASRec, achieve state-of-the-art results in sequential recommendation. However, it is challenging to use these models in production environments with catalogues of millions of items: scaling Transformers beyond a few thousand items is problematic for several reasons, including high model memory consumption and slow inference. In this respect, RecJPQ is a state-of-the-art method of reducing the models' memory consumption; RecJPQ compresses item catalogues by decomposing item IDs into a small number of shared sub-item IDs. Despite reporting the reduction of memory consumption by a factor of up to 50x, the original RecJPQ paper did not report inference efficiency improvements over the baseline Transformer-based models. Upon analysing RecJPQ's scoring algorithm, we find that its efficiency is limited by its use of score accumulators for each item, which prevents parallelisation. In contrast, LightRec (a non-sequential method that uses a similar idea of sub-ids) reported large inference efficiency improvements using an algorithm we call PQTopK. We show that it is also possible to improve RecJPQ-based models' inference efficiency using the PQTopK algorithm. In particular, we speed up RecJPQ-enhanced SASRec by a factor of 4.5 x compared to the original SASRec's inference method and by a factor of 1.56 x compared to the method implemented in RecJPQ code on a large-scale Gowalla dataset with more than a million items. Further, using simulated data, we show that PQTopK remains efficient with catalogues of up to tens of millions of items, removing one of the last obstacles to using Transformer-based models in production environments with large catalogues.
Shallow Cross-Encoders for Low-Latency Retrieval
Mar 29, 2024Transformer-based Cross-Encoders achieve state-of-the-art effectiveness in text retrieval. However, Cross-Encoders based on large transformer models (such as BERT or T5) are computationally expensive and allow for scoring only a small number of documents within a reasonably small latency window. However, keeping search latencies low is important for user satisfaction and energy usage. In this paper, we show that weaker shallow transformer models (i.e., transformers with a limited number of layers) actually perform better than full-scale models when constrained to these practical low-latency settings since they can estimate the relevance of more documents in the same time budget. We further show that shallow transformers may benefit from the generalized Binary Cross-Entropy (gBCE) training scheme, which has recently demonstrated success for recommendation tasks. Our experiments with TREC Deep Learning passage ranking query sets demonstrate significant improvements in shallow and full-scale models in low-latency scenarios. For example, when the latency limit is 25ms per query, MonoBERT-Large (a cross-encoder based on a full-scale BERT model) is only able to achieve NDCG@10 of 0.431 on TREC DL 2019, while TinyBERT-gBCE (a cross-encoder based on TinyBERT trained with gBCE) reaches NDCG@10 of 0.652, a +51% gain over MonoBERT-Large. We also show that shallow Cross-Encoders are effective even when used without a GPU (e.g., with CPU inference, NDCG@10 decreases only by 3% compared to GPU inference with 50ms latency), which makes Cross-Encoders practical to run even without specialized hardware acceleration.
RecJPQ: Training Large-Catalogue Sequential Recommenders
Dec 18, 2023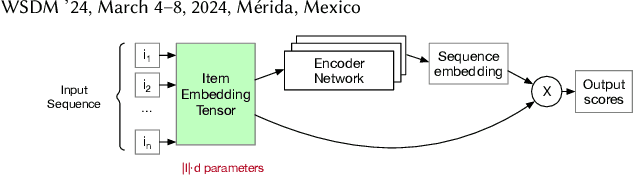

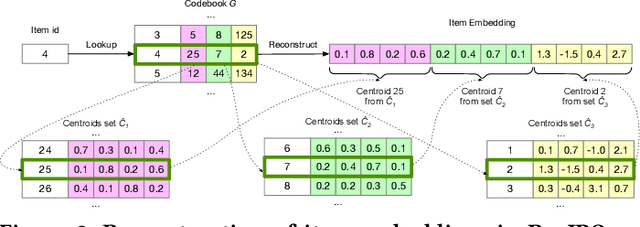
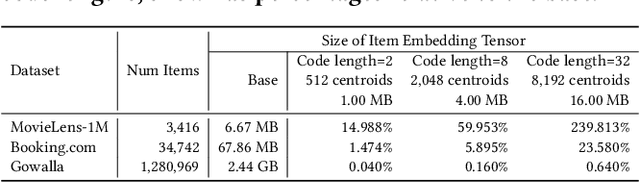
Sequential Recommendation is a popular recommendation task that uses the order of user-item interaction to model evolving users' interests and sequential patterns in their behaviour. Current state-of-the-art Transformer-based models for sequential recommendation, such as BERT4Rec and SASRec, generate sequence embeddings and compute scores for catalogue items, but the increasing catalogue size makes training these models costly. The Joint Product Quantisation (JPQ) method, originally proposed for passage retrieval, markedly reduces the size of the retrieval index with minimal effect on model effectiveness, by replacing passage embeddings with a limited number of shared sub-embeddings. This paper introduces RecJPQ, a novel adaptation of JPQ for sequential recommendations, which takes the place of item embeddings tensor and replaces item embeddings with a concatenation of a limited number of shared sub-embeddings and, therefore, limits the number of learnable model parameters. The main idea of RecJPQ is to split items into sub-item entities before training the main recommendation model, which is inspired by splitting words into tokens and training tokenisers in language models. We apply RecJPQ to SASRec, BERT4Rec, and GRU4rec models on three large-scale sequential datasets. Our results showed that RecJPQ could notably reduce the model size (e.g., 48% reduction for the Gowalla dataset with no effectiveness degradation). RecJPQ can also improve model performance through a regularisation effect (e.g. +0.96% NDCG@10 improvement on the Booking.com dataset). Overall, RecJPQ allows the training of state-of-the-art transformer recommenders in industrial applications, where datasets with millions of items are common.
Generative Sequential Recommendation with GPTRec
Jun 19, 2023Sequential recommendation is an important recommendation task that aims to predict the next item in a sequence. Recently, adaptations of language models, particularly Transformer-based models such as SASRec and BERT4Rec, have achieved state-of-the-art results in sequential recommendation. In these models, item ids replace tokens in the original language models. However, this approach has limitations. First, the vocabulary of item ids may be many times larger than in language models. Second, the classical Top-K recommendation approach used by these models may not be optimal for complex recommendation objectives, including auxiliary objectives such as diversity, coverage or coherence. Recent progress in generative language models inspires us to revisit generative approaches to address these challenges. This paper presents the GPTRec sequential recommendation model, which is based on the GPT-2 architecture. GPTRec can address large vocabulary issues by splitting item ids into sub-id tokens using a novel SVD Tokenisation algorithm based on quantised item embeddings from an SVD decomposition of the user-item interaction matrix. The paper also presents a novel Next-K recommendation strategy, which generates recommendations item-by-item, considering already recommended items. The Next-K strategy can be used for producing complex interdependent recommendation lists. We experiment with GPTRec on the MovieLens-1M dataset and show that using sub-item tokenisation GPTRec can match the quality of SASRec while reducing the embedding table by 40%. We also show that the recommendations generated by GPTRec on MovieLens-1M using the Next-K recommendation strategy match the quality of SASRec in terms of NDCG@10, meaning that the model can serve as a strong starting point for future research.