 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecJPQ: Training Large-Catalogue Sequential Recommenders
Paper and Code
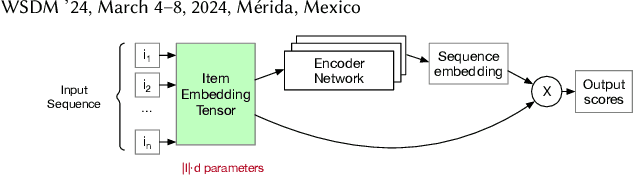

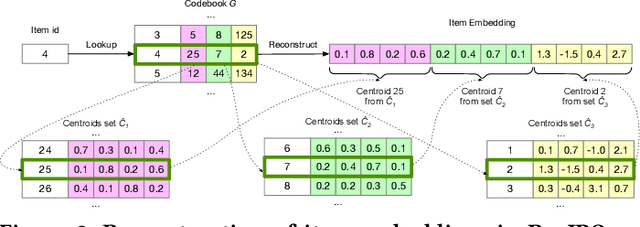
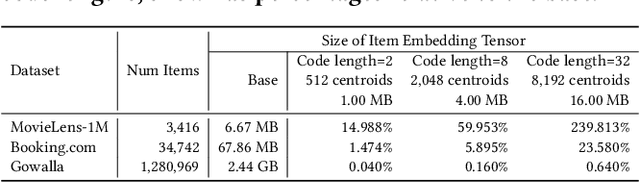
Sequential Recommendation is a popular recommendation task that uses the order of user-item interaction to model evolving users' interests and sequential patterns in their behaviour. Current state-of-the-art Transformer-based models for sequential recommendation, such as BERT4Rec and SASRec, generate sequence embeddings and compute scores for catalogue items, but the increasing catalogue size makes training these models costly. The Joint Product Quantisation (JPQ) method, originally proposed for passage retrieval, markedly reduces the size of the retrieval index with minimal effect on model effectiveness, by replacing passage embeddings with a limited number of shared sub-embeddings. This paper introduces RecJPQ, a novel adaptation of JPQ for sequential recommendations, which takes the place of item embeddings tensor and replaces item embeddings with a concatenation of a limited number of shared sub-embeddings and, therefore, limits the number of learnable model parameters. The main idea of RecJPQ is to split items into sub-item entities before training the main recommendation model, which is inspired by splitting words into tokens and training tokenisers in language models. We apply RecJPQ to SASRec, BERT4Rec, and GRU4rec models on three large-scale sequential datasets. Our results showed that RecJPQ could notably reduce the model size (e.g., 48% reduction for the Gowalla dataset with no effectiveness degradation). RecJPQ can also improve model performance through a regularisation effect (e.g. +0.96% NDCG@10 improvement on the Booking.com dataset). Overall, RecJPQ allows the training of state-of-the-art transformer recommenders in industrial applications, where datasets with millions of items are common.