 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Assisted Pseudo-Relevance Feedback
Jan 16, 2026Query expansion is a long-standing technique to mitigate vocabulary mismatch in ad hoc Information Retrieval. Pseudo-relevance feedback methods, such as RM3, estimate an expanded query model from the top-ranked documents, but remain vulnerable to topic drift when early results include noisy or tangential content. Recent approaches instead prompt Large Language Models to generate synthetic expansions or query variants. While effective, these methods risk hallucinations and misalignment with collection-specific terminology. We propose a hybrid alternative that preserves the robustness and interpretability of classical PRF while leveraging LLM semantic judgement. Our method inserts an LLM-based filtering stage prior to RM3 estimation: the LLM judges the documents in the initial top-$k$ ranking, and RM3 is computed only over those accepted as relevant. This simple intervention improves over blind PRF and a strong baseline across several datasets and metrics.
PartisanLens: A Multilingual Dataset of Hyperpartisan and Conspiratorial Immigration Narratives in European Media
Jan 07, 2026Detecting hyperpartisan narratives and Population Replacement Conspiracy Theories (PRCT) is essential to addressing the spread of misinformation. These complex narratives pose a significant threat, as hyperpartisanship drives political polarisation and institutional distrust, while PRCTs directly motivate real-world extremist violence, making their identification critical for social cohesion and public safety. However, existing resources are scarce, predominantly English-centric, and often analyse hyperpartisanship, stance, and rhetorical bias in isolation rather than as interrelated aspects of political discourse. To bridge this gap, we introduce \textsc{PartisanLens}, the first multilingual dataset of \num{1617} hyperpartisan news headlines in Spanish, Italian, and Portuguese, annotated in multiple political discourse aspects. We first evaluate the classification performance of widely used Large Language Models (LLMs) on this dataset, establishing robust baselines for the classification of hyperpartisan and PRCT narratives. In addition, we assess the viability of using LLMs as automatic annotators for this task, analysing their ability to approximate human annotation. Results highlight both their potential and current limitations. Next, moving beyond standard judgments, we explore whether LLMs can emulate human annotation patterns by conditioning them on socio-economic and ideological profiles that simulate annotator perspectives. At last, we provide our resources and evaluation, \textsc{PartisanLens} supports future research on detecting partisan and conspiratorial narratives in European contexts.
Can LLMs Evaluate What They Cannot Annotate? Revisiting LLM Reliability in Hate Speech Detection
Dec 10, 2025Hate speech spreads widely online, harming individuals and communities, making automatic detection essential for large-scale moderation, yet detecting it remains difficult. Part of the challenge lies in subjectivity: what one person flags as hate speech, another may see as benign. Traditional annotation agreement metrics, such as Cohen's $κ$, oversimplify this disagreement, treating it as an error rather than meaningful diversity. Meanwhile, Large Language Models (LLMs) promise scalable annotation, but prior studies demonstrate that they cannot fully replace human judgement, especially in subjective tasks. In this work, we reexamine LLM reliability using a subjectivity-aware framework, cross-Rater Reliability (xRR), revealing that even under fairer lens, LLMs still diverge from humans. Yet this limitation opens an opportunity: we find that LLM-generated annotations can reliably reflect performance trends across classification models, correlating with human evaluations. We test this by examining whether LLM-generated annotations preserve the relative ordering of model performance derived from human evaluation (i.e. whether models ranked as more reliable by human annotators preserve the same order when evaluated with LLM-generated labels). Our results show that, although LLMs differ from humans at the instance level, they reproduce similar ranking and classification patterns, suggesting their potential as proxy evaluators. While not a substitute for human annotators, they might serve as a scalable proxy for evaluation in subjective NLP tasks.
Who Is the Story About? Protagonist Entity Recognition in News
Nov 10, 2025News articles often reference numerous organizations, but traditional Named Entity Recognition (NER) treats all mentions equally, obscuring which entities genuinely drive the narrative. This limits downstream tasks that rely on understanding event salience, influence, or narrative focus. We introduce Protagonist Entity Recognition (PER), a task that identifies the organizations that anchor a news story and shape its main developments. To validate PER, we compare he predictions of Large Language Models (LLMs) against annotations from four expert annotators over a gold corpus, establishing both inter-annotator consistency and human-LLM agreement. Leveraging these findings, we use state-of-the-art LLMs to automatically label large-scale news collections through NER-guided prompting, generating scalable, high-quality supervision. We then evaluate whether other LLMs, given reduced context and without explicit candidate guidance, can still infer the correct protagonists. Our results demonstrate that PER is a feasible and meaningful extension to narrative-centered information extraction, and that guided LLMs can approximate human judgments of narrative importance at scale.
TalkDep: Clinically Grounded LLM Personas for Conversation-Centric Depression Screening
Aug 06, 2025The increasing demand for mental health services has outpaced the availability of real training data to develop clinical professionals, leading to limited support for the diagnosis of depression. This shortage has motivated the development of simulated or virtual patients to assist in training and evaluation, but existing approaches often fail to generate clinically valid, natural, and diverse symptom presentations. In this work, we embrace the recent advanced language models as the backbone and propose a novel clinician-in-the-loop patient simulation pipeline, TalkDep, with access to diversified patient profiles to develop simulated patients. By conditioning the model on psychiatric diagnostic criteria, symptom severity scales, and contextual factors, our goal is to create authentic patient responses that can better support diagnostic model training and evaluation. We verify the reliability of these simulated patients with thorough assessments conducted by clinical professionals. The availability of validated simulated patients offers a scalable and adaptable resource for improving the robustness and generalisability of automatic depression diagnosis systems.
Personalisation or Prejudice? Addressing Geographic Bias in Hate Speech Detection using Debias Tuning in Large Language Models
May 04, 2025Commercial Large Language Models (LLMs) have recently incorporated memory features to deliver personalised responses. This memory retains details such as user demographics and individual characteristics, allowing LLMs to adjust their behaviour based on personal information. However, the impact of integrating personalised information into the context has not been thoroughly assessed, leading to questions about its influence on LLM behaviour. Personalisation can be challenging, particularly with sensitive topics. In this paper, we examine various state-of-the-art LLMs to understand their behaviour in different personalisation scenarios, specifically focusing on hate speech. We prompt the models to assume country-specific personas and use different languages for hate speech detection. Our findings reveal that context personalisation significantly influences LLMs' responses in this sensitive area. To mitigate these unwanted biases, we fine-tune the LLMs by penalising inconsistent hate speech classifications made with and without country or language-specific context. The refined models demonstrate improved performance in both personalised contexts and when no context is provided.
Towards Reliable Testing for Multiple Information Retrieval System Comparisons
Jan 07, 2025

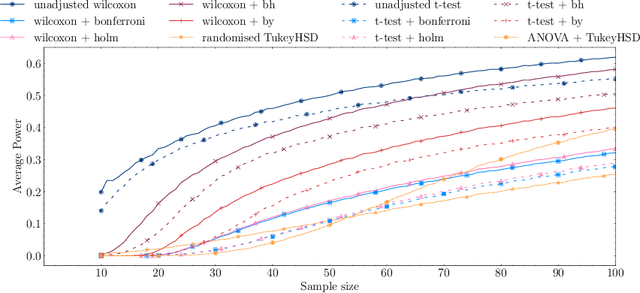
Null Hypothesis Significance Testing is the \textit{de facto} tool for assessing effectiveness differences between Information Retrieval systems. Researchers use statistical tests to check whether those differences will generalise to online settings or are just due to the samples observed in the laboratory. Much work has been devoted to studying which test is the most reliable when comparing a pair of systems, but most of the IR real-world experiments involve more than two. In the multiple comparisons scenario, testing several systems simultaneously may inflate the errors committed by the tests. In this paper, we use a new approach to assess the reliability of multiple comparison procedures using simulated and real TREC data. Experiments show that Wilcoxon plus the Benjamini-Hochberg correction yields Type I error rates according to the significance level for typical sample sizes while being the best test in terms of statistical power.
Towards Efficient and Explainable Hate Speech Detection via Model Distillation
Dec 18, 2024
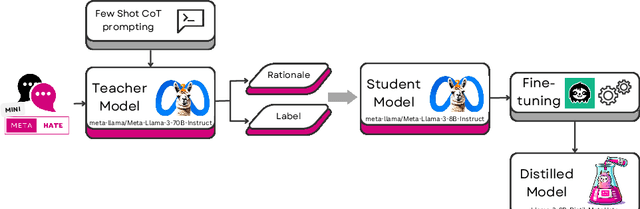
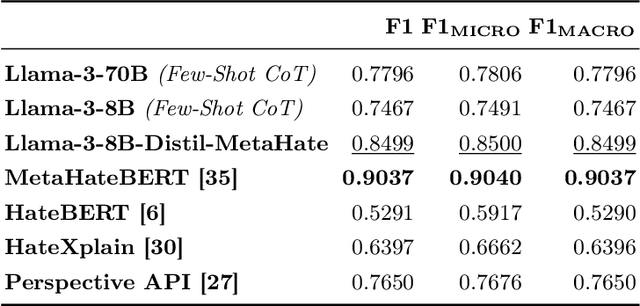
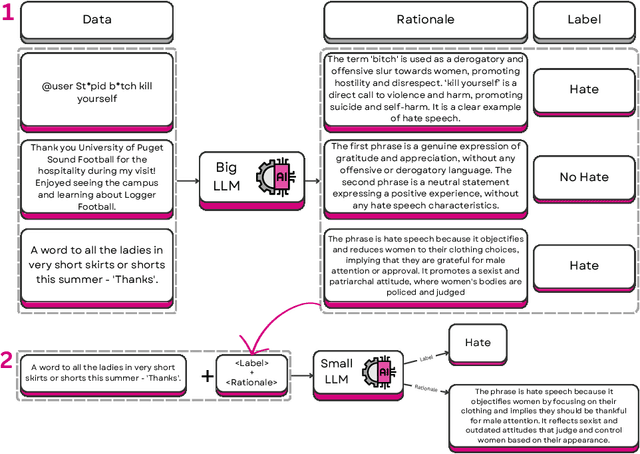
Automatic detection of hate and abusive language is essential to combat its online spread. Moreover, recognising and explaining hate speech serves to educate people about its negative effects. However, most current detection models operate as black boxes, lacking interpretability and explainability. In this context, Large Language Models (LLMs) have proven effective for hate speech detection and to promote interpretability. Nevertheless, they are computationally costly to run. In this work, we propose distilling big language models by using Chain-of-Thought to extract explanations that support the hate speech classification task. Having small language models for these tasks will contribute to their use in operational settings. In this paper, we demonstrate that distilled models deliver explanations of the same quality as larger models while surpassing them in classification performance. This dual capability, classifying and explaining, advances hate speech detection making it more affordable, understandable and actionable.
Beyond Questions: Leveraging ColBERT for Keyphrase Search
Dec 04, 2024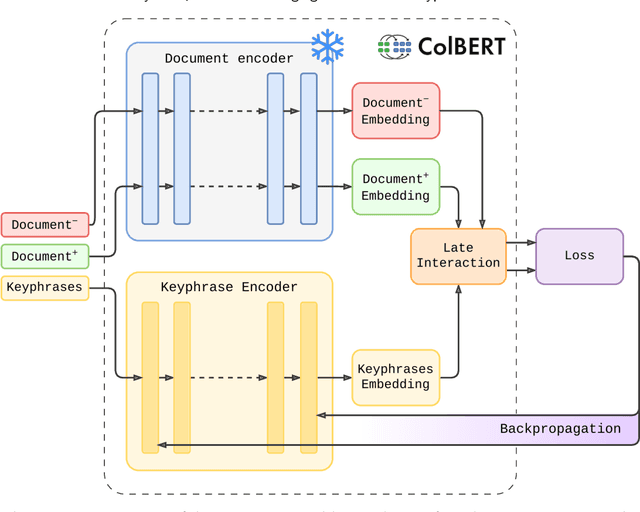
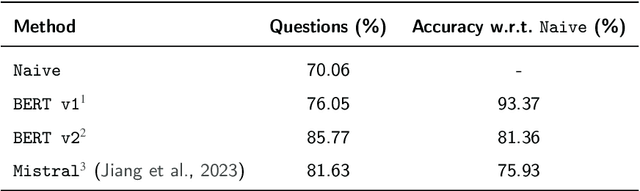
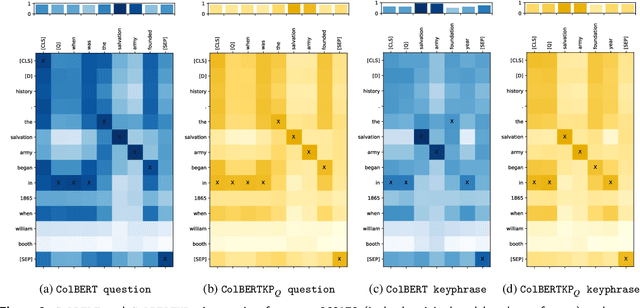
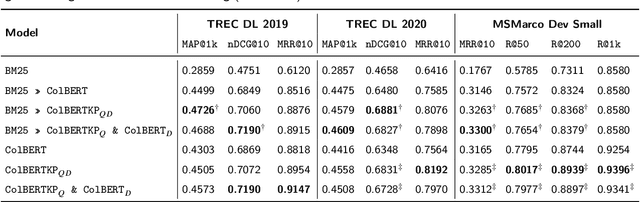
While question-like queries are gaining popularity and search engines' users increasingly adopt them, keyphrase search has traditionally been the cornerstone of web search. This query type is also prevalent in specialised search tasks such as academic or professional search, where experts rely on keyphrases to articulate their information needs. However, current dense retrieval models often fail with keyphrase-like queries, primarily because they are mostly trained on question-like ones. This paper introduces a novel model that employs the ColBERT architecture to enhance document ranking for keyphrase queries. For that, given the lack of large keyphrase-based retrieval datasets, we first explore how Large Language Models can convert question-like queries into keyphrase format. Then, using those keyphrases, we train a keyphrase-based ColBERT ranker (ColBERTKP_QD) to improve the performance when working with keyphrase queries. Furthermore, to reduce the training costs associated with training the full ColBERT model, we investigate the feasibility of training only a keyphrase query encoder while keeping the document encoder weights static (ColBERTKP_Q). We assess our proposals' ranking performance using both automatically generated and manually annotated keyphrases. Our results reveal the potential of the late interaction architecture when working under the keyphrase search scenario.
On the Statistical Significance with Relevance Assessments of Large Language Models
Nov 20, 2024



Test collections are an integral part of Information Retrieval (IR) research. They allow researchers to evaluate and compare ranking algorithms in a quick, easy and reproducible way. However, constructing these datasets requires great efforts in manual labelling and logistics, and having only few human relevance judgements can introduce biases in the comparison. Recent research has explored the use of Large Language Models (LLMs) for labelling the relevance of documents for building new retrieval test collections. Their strong text-understanding capabilities and low cost compared to human-made judgements makes them an appealing tool for gathering relevance judgements. Results suggest that LLM-generated labels are promising for IR evaluation in terms of ranking correlation, but nothing is said about the implications in terms of statistical significance. In this work, we look at how LLM-generated judgements preserve the same pairwise significance evaluation as human judgements. Our results show that LLM judgements detect most of the significant differences while maintaining acceptable numbers of false positives. However, we also show that some systems are treated differently under LLM-generated labels, suggesting that evaluation with LLM judgements might not be entirely fair. Our work represents a step forward in the evaluation of statistical testing results provided by LLM judgements. We hope that this will serve as a basis for other researchers to develop reliable models for automatic relevance assessments.