 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Evaluate What They Cannot Annotate? Revisiting LLM Reliability in Hate Speech Detection
Dec 10, 2025Hate speech spreads widely online, harming individuals and communities, making automatic detection essential for large-scale moderation, yet detecting it remains difficult. Part of the challenge lies in subjectivity: what one person flags as hate speech, another may see as benign. Traditional annotation agreement metrics, such as Cohen's $κ$, oversimplify this disagreement, treating it as an error rather than meaningful diversity. Meanwhile, Large Language Models (LLMs) promise scalable annotation, but prior studies demonstrate that they cannot fully replace human judgement, especially in subjective tasks. In this work, we reexamine LLM reliability using a subjectivity-aware framework, cross-Rater Reliability (xRR), revealing that even under fairer lens, LLMs still diverge from humans. Yet this limitation opens an opportunity: we find that LLM-generated annotations can reliably reflect performance trends across classification models, correlating with human evaluations. We test this by examining whether LLM-generated annotations preserve the relative ordering of model performance derived from human evaluation (i.e. whether models ranked as more reliable by human annotators preserve the same order when evaluated with LLM-generated labels). Our results show that, although LLMs differ from humans at the instance level, they reproduce similar ranking and classification patterns, suggesting their potential as proxy evaluators. While not a substitute for human annotators, they might serve as a scalable proxy for evaluation in subjective NLP tasks.
Personalisation or Prejudice? Addressing Geographic Bias in Hate Speech Detection using Debias Tuning in Large Language Models
May 04, 2025Commercial Large Language Models (LLMs) have recently incorporated memory features to deliver personalised responses. This memory retains details such as user demographics and individual characteristics, allowing LLMs to adjust their behaviour based on personal information. However, the impact of integrating personalised information into the context has not been thoroughly assessed, leading to questions about its influence on LLM behaviour. Personalisation can be challenging, particularly with sensitive topics. In this paper, we examine various state-of-the-art LLMs to understand their behaviour in different personalisation scenarios, specifically focusing on hate speech. We prompt the models to assume country-specific personas and use different languages for hate speech detection. Our findings reveal that context personalisation significantly influences LLMs' responses in this sensitive area. To mitigate these unwanted biases, we fine-tune the LLMs by penalising inconsistent hate speech classifications made with and without country or language-specific context. The refined models demonstrate improved performance in both personalised contexts and when no context is provided.
MetaHate: A Dataset for Unifying Efforts on Hate Speech Detection
Jan 12, 2024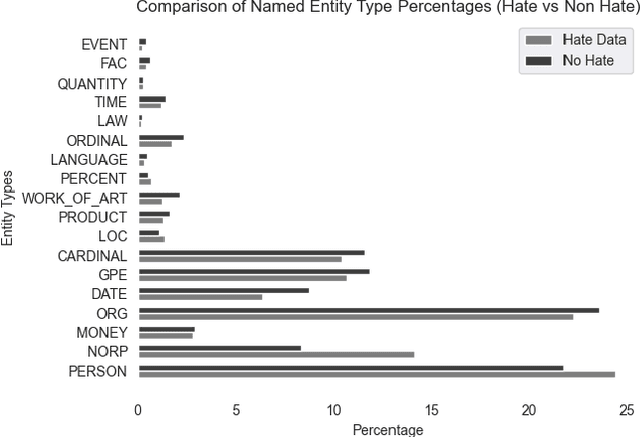
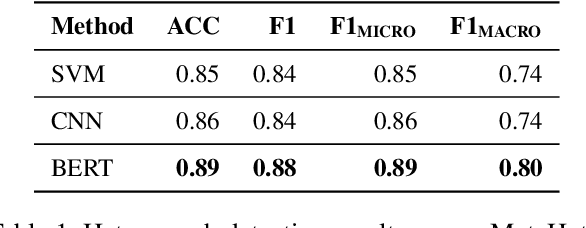

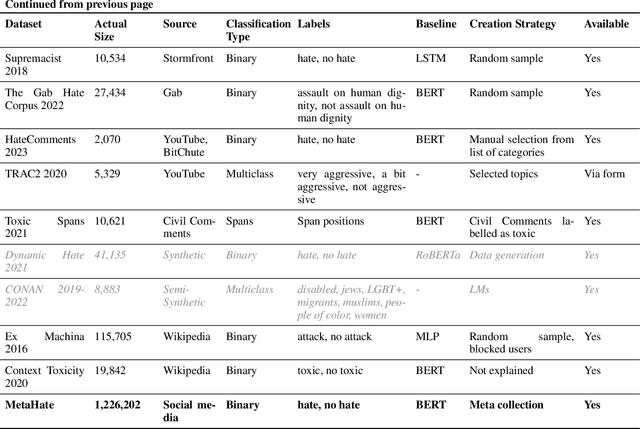
Hate speech represents a pervasive and detrimental form of online discourse, often manifested through an array of slurs, from hateful tweets to defamatory posts. As such speech proliferates, it connects people globally and poses significant social, psychological, and occasionally physical threats to targeted individuals and communities. Current computational linguistic approaches for tackling this phenomenon rely on labelled social media datasets for training. For unifying efforts, our study advances in the critical need for a comprehensive meta-collection, advocating for an extensive dataset to help counteract this problem effectively. We scrutinized over 60 datasets, selectively integrating those pertinent into MetaHate. This paper offers a detailed examination of existing collections, highlighting their strengths and limitations. Our findings contribute to a deeper understanding of the existing datasets, paving the way for training more robust and adaptable models. These enhanced models are essential for effectively combating the dynamic and complex nature of hate speech in the digital realm.