 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Assisted Pseudo-Relevance Feedback
Jan 16, 2026Query expansion is a long-standing technique to mitigate vocabulary mismatch in ad hoc Information Retrieval. Pseudo-relevance feedback methods, such as RM3, estimate an expanded query model from the top-ranked documents, but remain vulnerable to topic drift when early results include noisy or tangential content. Recent approaches instead prompt Large Language Models to generate synthetic expansions or query variants. While effective, these methods risk hallucinations and misalignment with collection-specific terminology. We propose a hybrid alternative that preserves the robustness and interpretability of classical PRF while leveraging LLM semantic judgement. Our method inserts an LLM-based filtering stage prior to RM3 estimation: the LLM judges the documents in the initial top-$k$ ranking, and RM3 is computed only over those accepted as relevant. This simple intervention improves over blind PRF and a strong baseline across several datasets and metrics.
Can LLMs Evaluate What They Cannot Annotate? Revisiting LLM Reliability in Hate Speech Detection
Dec 10, 2025Hate speech spreads widely online, harming individuals and communities, making automatic detection essential for large-scale moderation, yet detecting it remains difficult. Part of the challenge lies in subjectivity: what one person flags as hate speech, another may see as benign. Traditional annotation agreement metrics, such as Cohen's $κ$, oversimplify this disagreement, treating it as an error rather than meaningful diversity. Meanwhile, Large Language Models (LLMs) promise scalable annotation, but prior studies demonstrate that they cannot fully replace human judgement, especially in subjective tasks. In this work, we reexamine LLM reliability using a subjectivity-aware framework, cross-Rater Reliability (xRR), revealing that even under fairer lens, LLMs still diverge from humans. Yet this limitation opens an opportunity: we find that LLM-generated annotations can reliably reflect performance trends across classification models, correlating with human evaluations. We test this by examining whether LLM-generated annotations preserve the relative ordering of model performance derived from human evaluation (i.e. whether models ranked as more reliable by human annotators preserve the same order when evaluated with LLM-generated labels). Our results show that, although LLMs differ from humans at the instance level, they reproduce similar ranking and classification patterns, suggesting their potential as proxy evaluators. While not a substitute for human annotators, they might serve as a scalable proxy for evaluation in subjective NLP tasks.
Towards Reliable Testing for Multiple Information Retrieval System Comparisons
Jan 07, 2025

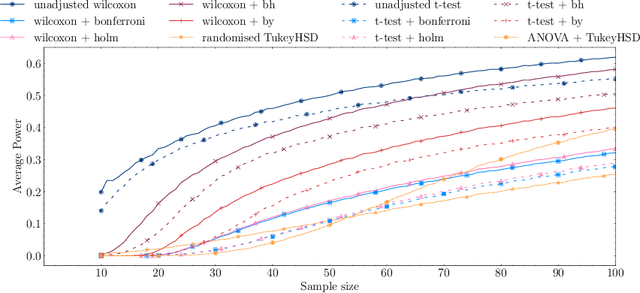
Null Hypothesis Significance Testing is the \textit{de facto} tool for assessing effectiveness differences between Information Retrieval systems. Researchers use statistical tests to check whether those differences will generalise to online settings or are just due to the samples observed in the laboratory. Much work has been devoted to studying which test is the most reliable when comparing a pair of systems, but most of the IR real-world experiments involve more than two. In the multiple comparisons scenario, testing several systems simultaneously may inflate the errors committed by the tests. In this paper, we use a new approach to assess the reliability of multiple comparison procedures using simulated and real TREC data. Experiments show that Wilcoxon plus the Benjamini-Hochberg correction yields Type I error rates according to the significance level for typical sample sizes while being the best test in terms of statistical power.
On the Statistical Significance with Relevance Assessments of Large Language Models
Nov 20, 2024



Test collections are an integral part of Information Retrieval (IR) research. They allow researchers to evaluate and compare ranking algorithms in a quick, easy and reproducible way. However, constructing these datasets requires great efforts in manual labelling and logistics, and having only few human relevance judgements can introduce biases in the comparison. Recent research has explored the use of Large Language Models (LLMs) for labelling the relevance of documents for building new retrieval test collections. Their strong text-understanding capabilities and low cost compared to human-made judgements makes them an appealing tool for gathering relevance judgements. Results suggest that LLM-generated labels are promising for IR evaluation in terms of ranking correlation, but nothing is said about the implications in terms of statistical significance. In this work, we look at how LLM-generated judgements preserve the same pairwise significance evaluation as human judgements. Our results show that LLM judgements detect most of the significant differences while maintaining acceptable numbers of false positives. However, we also show that some systems are treated differently under LLM-generated labels, suggesting that evaluation with LLM judgements might not be entirely fair. Our work represents a step forward in the evaluation of statistical testing results provided by LLM judgements. We hope that this will serve as a basis for other researchers to develop reliable models for automatic relevance assessments.
How Discriminative Are Your Qrels? How To Study the Statistical Significance of Document Adjudication Methods
Aug 28, 2023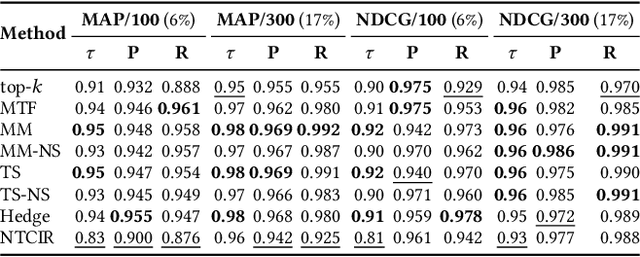
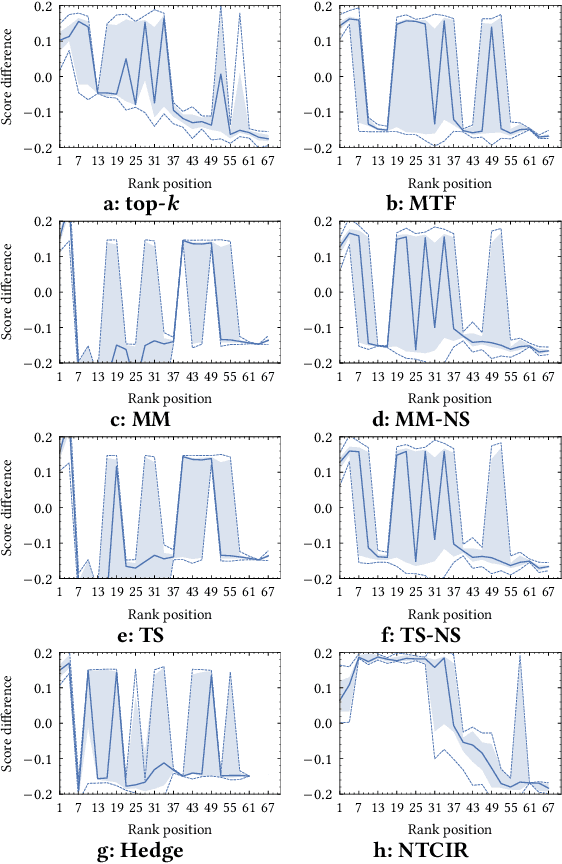
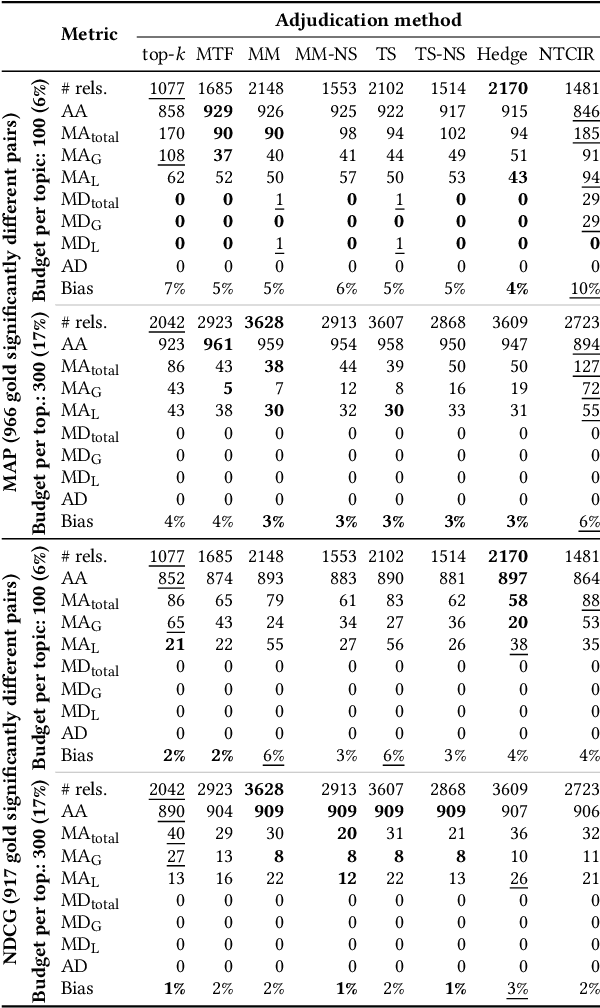
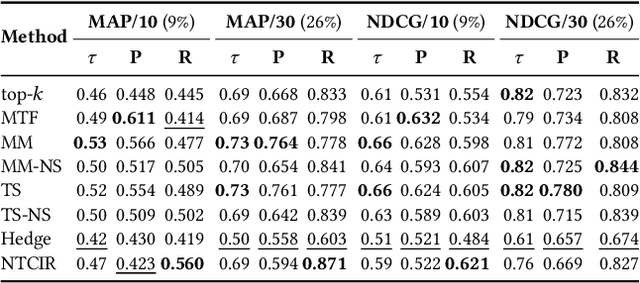
Creating test collections for offline retrieval evaluation requires human effort to judge documents' relevance. This expensive activity motivated much work in developing methods for constructing benchmarks with fewer assessment costs. In this respect, adjudication methods actively decide both which documents and the order in which experts review them, in order to better exploit the assessment budget or to lower it. Researchers evaluate the quality of those methods by measuring the correlation between the known gold ranking of systems under the full collection and the observed ranking of systems under the lower-cost one. This traditional analysis ignores whether and how the low-cost judgements impact on the statistically significant differences among systems with respect to the full collection. We fill this void by proposing a novel methodology to evaluate how the low-cost adjudication methods preserve the pairwise significant differences between systems as the full collection. In other terms, while traditional approaches look for stability in answering the question "is system A better than system B?", our proposed approach looks for stability in answering the question "is system A significantly better than system B?", which is the ultimate questions researchers need to answer to guarantee the generalisability of their results. Among other results, we found that the best methods in terms of ranking of systems correlation do not always match those preserving statistical significance.