 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Testing for Multiple Information Retrieval System Comparisons
Jan 07, 2025

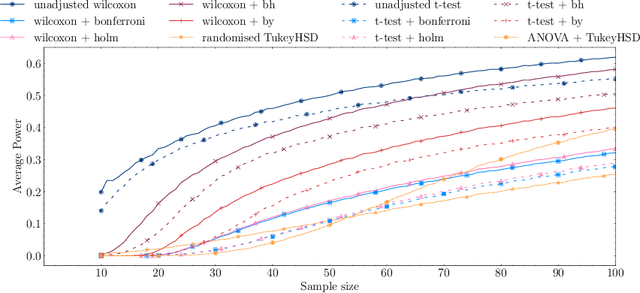
Null Hypothesis Significance Testing is the \textit{de facto} tool for assessing effectiveness differences between Information Retrieval systems. Researchers use statistical tests to check whether those differences will generalise to online settings or are just due to the samples observed in the laboratory. Much work has been devoted to studying which test is the most reliable when comparing a pair of systems, but most of the IR real-world experiments involve more than two. In the multiple comparisons scenario, testing several systems simultaneously may inflate the errors committed by the tests. In this paper, we use a new approach to assess the reliability of multiple comparison procedures using simulated and real TREC data. Experiments show that Wilcoxon plus the Benjamini-Hochberg correction yields Type I error rates according to the significance level for typical sample sizes while being the best test in terms of statistical power.
On the Statistical Significance with Relevance Assessments of Large Language Models
Nov 20, 2024



Test collections are an integral part of Information Retrieval (IR) research. They allow researchers to evaluate and compare ranking algorithms in a quick, easy and reproducible way. However, constructing these datasets requires great efforts in manual labelling and logistics, and having only few human relevance judgements can introduce biases in the comparison. Recent research has explored the use of Large Language Models (LLMs) for labelling the relevance of documents for building new retrieval test collections. Their strong text-understanding capabilities and low cost compared to human-made judgements makes them an appealing tool for gathering relevance judgements. Results suggest that LLM-generated labels are promising for IR evaluation in terms of ranking correlation, but nothing is said about the implications in terms of statistical significance. In this work, we look at how LLM-generated judgements preserve the same pairwise significance evaluation as human judgements. Our results show that LLM judgements detect most of the significant differences while maintaining acceptable numbers of false positives. However, we also show that some systems are treated differently under LLM-generated labels, suggesting that evaluation with LLM judgements might not be entirely fair. Our work represents a step forward in the evaluation of statistical testing results provided by LLM judgements. We hope that this will serve as a basis for other researchers to develop reliable models for automatic relevance assessments.