 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Testing for Multiple Information Retrieval System Comparisons
Paper and Code


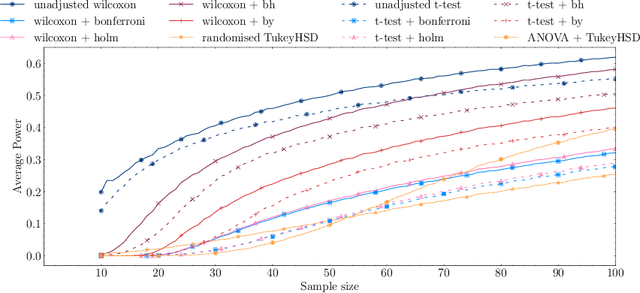
Null Hypothesis Significance Testing is the \textit{de facto} tool for assessing effectiveness differences between Information Retrieval systems. Researchers use statistical tests to check whether those differences will generalise to online settings or are just due to the samples observed in the laboratory. Much work has been devoted to studying which test is the most reliable when comparing a pair of systems, but most of the IR real-world experiments involve more than two. In the multiple comparisons scenario, testing several systems simultaneously may inflate the errors committed by the tests. In this paper, we use a new approach to assess the reliability of multiple comparison procedures using simulated and real TREC data. Experiments show that Wilcoxon plus the Benjamini-Hochberg correction yields Type I error rates according to the significance level for typical sample sizes while being the best test in terms of statistical power.