 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaHate: A Dataset for Unifying Efforts on Hate Speech Detection
Paper and Code
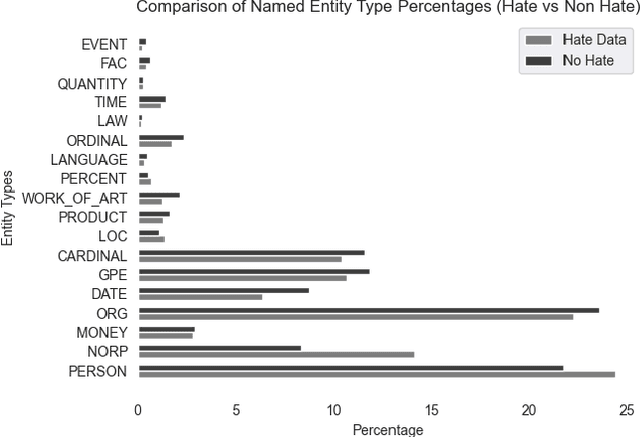
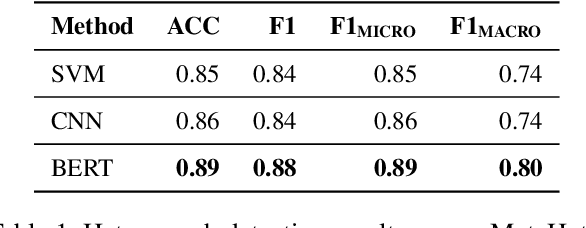

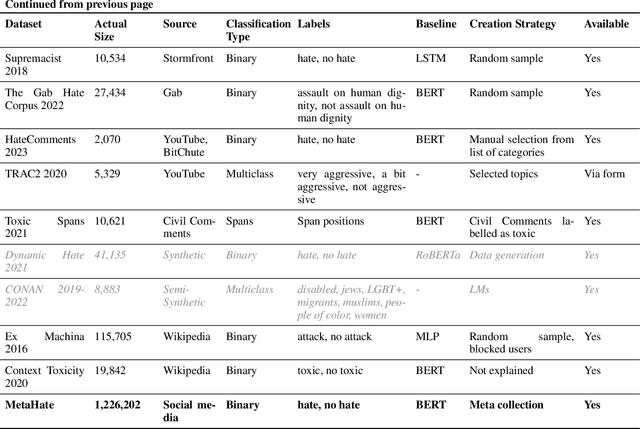
Hate speech represents a pervasive and detrimental form of online discourse, often manifested through an array of slurs, from hateful tweets to defamatory posts. As such speech proliferates, it connects people globally and poses significant social, psychological, and occasionally physical threats to targeted individuals and communities. Current computational linguistic approaches for tackling this phenomenon rely on labelled social media datasets for training. For unifying efforts, our study advances in the critical need for a comprehensive meta-collection, advocating for an extensive dataset to help counteract this problem effectively. We scrutinized over 60 datasets, selectively integrating those pertinent into MetaHate. This paper offers a detailed examination of existing collections, highlighting their strengths and limitations. Our findings contribute to a deeper understanding of the existing datasets, paving the way for training more robust and adaptable models. These enhanced models are essential for effectively combating the dynamic and complex nature of hate speech in the digital realm.