 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Is the Story About? Protagonist Entity Recognition in News
Nov 10, 2025News articles often reference numerous organizations, but traditional Named Entity Recognition (NER) treats all mentions equally, obscuring which entities genuinely drive the narrative. This limits downstream tasks that rely on understanding event salience, influence, or narrative focus. We introduce Protagonist Entity Recognition (PER), a task that identifies the organizations that anchor a news story and shape its main developments. To validate PER, we compare he predictions of Large Language Models (LLMs) against annotations from four expert annotators over a gold corpus, establishing both inter-annotator consistency and human-LLM agreement. Leveraging these findings, we use state-of-the-art LLMs to automatically label large-scale news collections through NER-guided prompting, generating scalable, high-quality supervision. We then evaluate whether other LLMs, given reduced context and without explicit candidate guidance, can still infer the correct protagonists. Our results demonstrate that PER is a feasible and meaningful extension to narrative-centered information extraction, and that guided LLMs can approximate human judgments of narrative importance at scale.
Enhancing Automatic Keyphrase Labelling with Text-to-Text Transfer Transformer (T5) Architecture: A Framework for Keyphrase Generation and Filtering
Sep 25, 2024Automatic keyphrase labelling stands for the ability of models to retrieve words or short phrases that adequately describe documents' content. Previous work has put much effort into exploring extractive techniques to address this task; however, these methods cannot produce keyphrases not found in the text. Given this limitation, keyphrase generation approaches have arisen lately. This paper presents a keyphrase generation model based on the Text-to-Text Transfer Transformer (T5) architecture. Having a document's title and abstract as input, we learn a T5 model to generate keyphrases which adequately define its content. We name this model docT5keywords. We not only perform the classic inference approach, where the output sequence is directly selected as the predicted values, but we also report results from a majority voting approach. In this approach, multiple sequences are generated, and the keyphrases are ranked based on their frequency of occurrence across these sequences. Along with this model, we present a novel keyphrase filtering technique based on the T5 architecture. We train a T5 model to learn whether a given keyphrase is relevant to a document. We devise two evaluation methodologies to prove our model's capability to filter inadequate keyphrases. First, we perform a binary evaluation where our model has to predict if a keyphrase is relevant for a given document. Second, we filter the predicted keyphrases by several AKG models and check if the evaluation scores are improved. Experimental results demonstrate that our keyphrase generation model significantly outperforms all the baselines, with gains exceeding 100\% in some cases. The proposed filtering technique also achieves near-perfect accuracy in eliminating false positives across all datasets.
Keyword Embeddings for Query Suggestion
Jan 23, 2023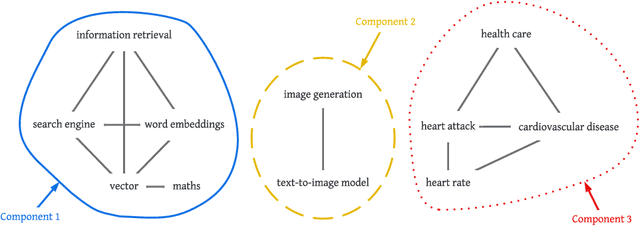
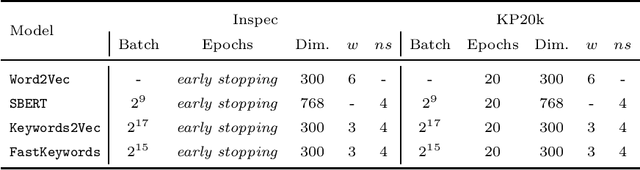
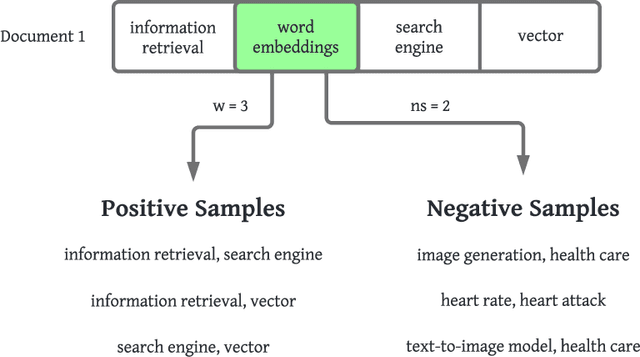
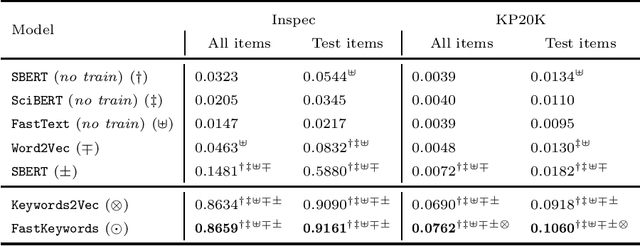
Nowadays, search engine users commonly rely on query suggestions to improve their initial inputs. Current systems are very good at recommending lexical adaptations or spelling corrections to users' queries. However, they often struggle to suggest semantically related keywords given a user's query. The construction of a detailed query is crucial in some tasks, such as legal retrieval or academic search. In these scenarios, keyword suggestion methods are critical to guide the user during the query formulation. This paper proposes two novel models for the keyword suggestion task trained on scientific literature. Our techniques adapt the architecture of Word2Vec and FastText to generate keyword embeddings by leveraging documents' keyword co-occurrence. Along with these models, we also present a specially tailored negative sampling approach that exploits how keywords appear in academic publications. We devise a ranking-based evaluation methodology following both known-item and ad-hoc search scenarios. Finally, we evaluate our proposals against the state-of-the-art word and sentence embedding models showing considerable improvements over the baselines for the tasks.