 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Relevance Propagated from Retriever to Generator in RAG?
Paper and Code
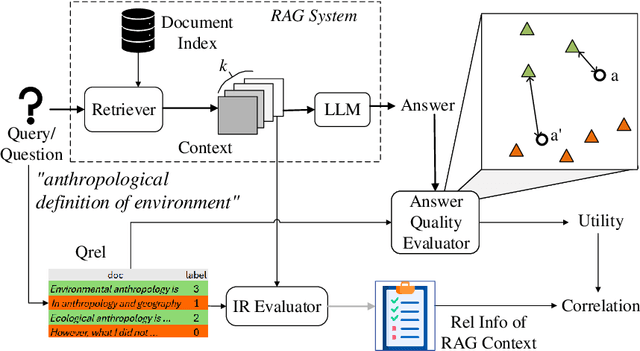
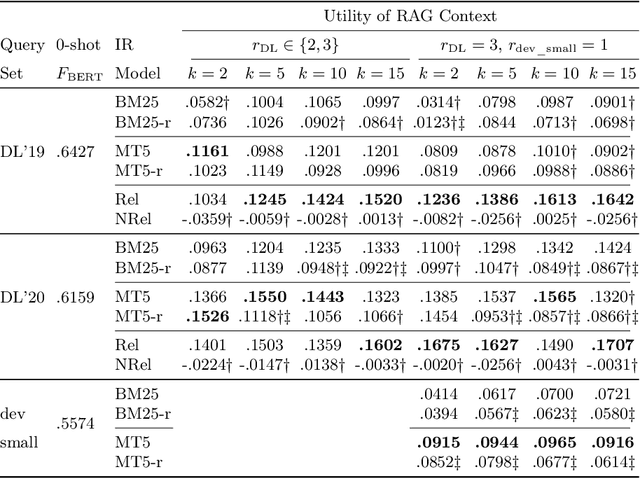
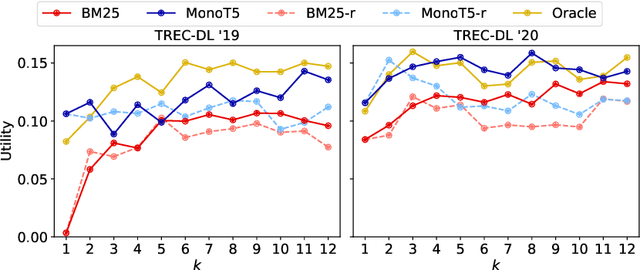
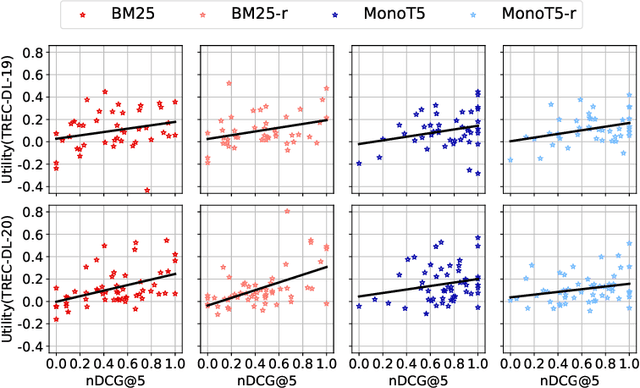
Retrieval Augmented Generation (RAG) is a framework for incorporating external knowledge, usually in the form of a set of documents retrieved from a collection, as a part of a prompt to a large language model (LLM) to potentially improve the performance of a downstream task, such as question answering. Different from a standard retrieval task's objective of maximising the relevance of a set of top-ranked documents, a RAG system's objective is rather to maximise their total utility, where the utility of a document indicates whether including it as a part of the additional contextual information in an LLM prompt improves a downstream task. Existing studies investigate the role of the relevance of a RAG context for knowledge-intensive language tasks (KILT), where relevance essentially takes the form of answer containment. In contrast, in our work, relevance corresponds to that of topical overlap between a query and a document for an information seeking task. Specifically, we make use of an IR test collection to empirically investigate whether a RAG context comprised of topically relevant documents leads to improved downstream performance. Our experiments lead to the following findings: (a) there is a small positive correlation between relevance and utility; (b) this correlation decreases with increasing context sizes (higher values of k in k-shot); and (c) a more effective retrieval model generally leads to better downstream RAG performance.