 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADaFuSE: Adaptive Diffusion-generated Image and Text Fusion for Interactive Text-to-Image Retrieval
Mar 23, 2026Recent advances in interactive text-to-image retrieval (I-TIR) use diffusion models to bridge the modality gap between the textual information need and the images to be searched, resulting in increased effectiveness. However, existing frameworks fuse multi-modal views of user feedback by simple embedding addition. In this work, we show that this static and undifferentiated fusion indiscriminately incorporates generative noise produced by the diffusion model, leading to performance degradation for up to 55.62% samples. We further propose ADaFuSE (Adaptive Diffusion-Text Fusion with Semantic-aware Experts), a lightweight fusion model designed to align and calibrate multi-modal views for diffusion-augmented I-TIR, which can be plugged into existing frameworks without modifying the backbone encoder. Specifically, we introduce a dual-branch fusion mechanism that employs an adaptive gating branch to dynamically balance modality reliability, alongside a semantic-aware mixture-of-experts branch to capture fine-grained cross-modal nuances. Via thorough evaluation over four standard I-TIR benchmarks, ADaFuSE achieves state-of-the-art performance, surpassing DAR by up to 3.49% in Hits@10 with only a 5.29% parameter increase, while exhibiting stronger robustness to noisy and longer interactive queries. These results show that generative augmentation coupled with principled fusion provides a simple, generalizable alternative to fine-tuning for interactive retrieval.
Is Training Necessary for Anomaly Detection?
Jan 30, 2026Current state-of-the-art multi-class unsupervised anomaly detection (MUAD) methods rely on training encoder-decoder models to reconstruct anomaly-free features. We first show these approaches have an inherent fidelity-stability dilemma in how they detect anomalies via reconstruction residuals. We then abandon the reconstruction paradigm entirely and propose Retrieval-based Anomaly Detection (RAD). RAD is a training-free approach that stores anomaly-free features in a memory and detects anomalies through multi-level retrieval, matching test patches against the memory. Experiments demonstrate that RAD achieves state-of-the-art performance across four established benchmarks (MVTec-AD, VisA, Real-IAD, 3D-ADAM) under both standard and few-shot settings. On MVTec-AD, RAD reaches 96.7\% Pixel AUROC with just a single anomaly-free image compared to 98.5\% of RAD's full-data performance. We further prove that retrieval-based scores theoretically upper-bound reconstruction-residual scores. Collectively, these findings overturn the assumption that MUAD requires task-specific training, showing that state-of-the-art anomaly detection is feasible with memory-based retrieval. Our code is available at https://github.com/longkukuhi/RAD.
Eliminating Hallucination in Diffusion-Augmented Interactive Text-to-Image Retrieval
Jan 28, 2026Diffusion-Augmented Interactive Text-to-Image Retrieval (DAI-TIR) is a promising paradigm that improves retrieval performance by generating query images via diffusion models and using them as additional ``views'' of the user's intent. However, these generative views can be incorrect because diffusion generation may introduce hallucinated visual cues that conflict with the original query text. Indeed, we empirically demonstrate that these hallucinated cues can substantially degrade DAI-TIR performance. To address this, we propose Diffusion-aware Multi-view Contrastive Learning (DMCL), a hallucination-robust training framework that casts DAI-TIR as joint optimization over representations of query intent and the target image. DMCL introduces semantic-consistency and diffusion-aware contrastive objectives to align textual and diffusion-generated query views while suppressing hallucinated query signals. This yields an encoder that acts as a semantic filter, effectively mapping hallucinated cues into a null space, improving robustness to spurious cues and better representing the user's intent. Attention visualization and geometric embedding-space analyses corroborate this filtering behavior. Across five standard benchmarks, DMCL delivers consistent improvements in multi-round Hits@10, reaching as high as 7.37\% over prior fine-tuned and zero-shot baselines, which indicates it is a general and robust training framework for DAI-TIR.
RoboEye: Enhancing 2D Robotic Object Identification with Selective 3D Geometric Keypoint Matching
Sep 18, 2025
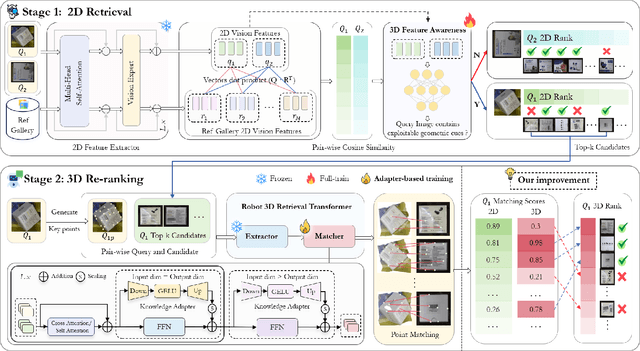
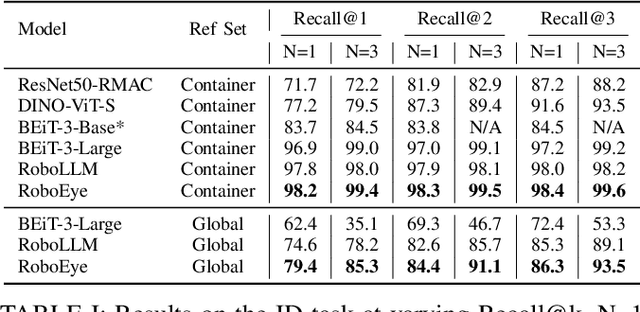
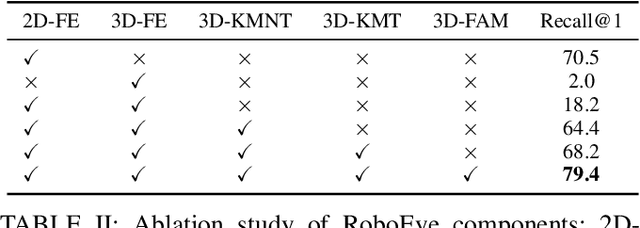
The rapidly growing number of product categories in large-scale e-commerce makes accurate object identification for automated packing in warehouses substantially more difficult. As the catalog grows, intra-class variability and a long tail of rare or visually similar items increase, and when combined with diverse packaging, cluttered containers, frequent occlusion, and large viewpoint changes-these factors amplify discrepancies between query and reference images, causing sharp performance drops for methods that rely solely on 2D appearance features. Thus, we propose RoboEye, a two-stage identification framework that dynamically augments 2D semantic features with domain-adapted 3D reasoning and lightweight adapters to bridge training deployment gaps. In the first stage, we train a large vision model to extract 2D features for generating candidate rankings. A lightweight 3D-feature-awareness module then estimates 3D feature quality and predicts whether 3D re-ranking is necessary, preventing performance degradation and avoiding unnecessary computation. When invoked, the second stage uses our robot 3D retrieval transformer, comprising a 3D feature extractor that produces geometry-aware dense features and a keypoint-based matcher that computes keypoint-correspondence confidences between query and reference images instead of conventional cosine-similarity scoring. Experiments show that RoboEye improves Recall@1 by 7.1% over the prior state of the art (RoboLLM). Moreover, RoboEye operates using only RGB images, avoiding reliance on explicit 3D inputs and reducing deployment costs. The code used in this paper is publicly available at: https://github.com/longkukuhi/RoboEye.
Zero-Shot Interactive Text-to-Image Retrieval via Diffusion-Augmented Representations
Jan 26, 2025



Interactive Text-to-Image Retrieval (I-TIR) has emerged as a transformative user-interactive tool for applications in domains such as e-commerce and education. Yet, current methodologies predominantly depend on finetuned Multimodal Large Language Models (MLLMs), which face two critical limitations: (1) Finetuning imposes prohibitive computational overhead and long-term maintenance costs. (2) Finetuning narrows the pretrained knowledge distribution of MLLMs, reducing their adaptability to novel scenarios. These issues are exacerbated by the inherently dynamic nature of real-world I-TIR systems, where queries and image databases evolve in complexity and diversity, often deviating from static training distributions. To overcome these constraints, we propose Diffusion Augmented Retrieval (DAR), a paradigm-shifting framework that bypasses MLLM finetuning entirely. DAR synergizes Large Language Model (LLM)-guided query refinement with Diffusion Model (DM)-based visual synthesis to create contextually enriched intermediate representations. This dual-modality approach deciphers nuanced user intent more holistically, enabling precise alignment between textual queries and visually relevant images. Rigorous evaluations across four benchmarks reveal DAR's dual strengths: (1) Matches state-of-the-art finetuned I-TIR models on straightforward queries without task-specific training. (2) Scalable Generalization: Surpasses finetuned baselines by 7.61% in Hits@10 (top-10 accuracy) under multi-turn conversational complexity, demonstrating robustness to intricate, distributionally shifted interactions. By eliminating finetuning dependencies and leveraging generative-augmented representations, DAR establishes a new trajectory for efficient, adaptive, and scalable cross-modal retrieval systems.
Understanding and Mitigating Human-Labelling Errors in Supervised Contrastive Learning
Mar 10, 2024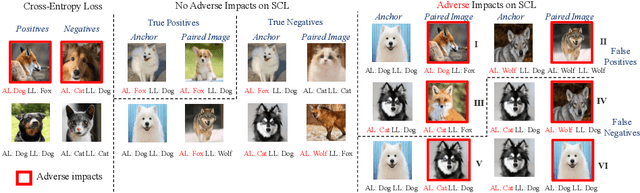
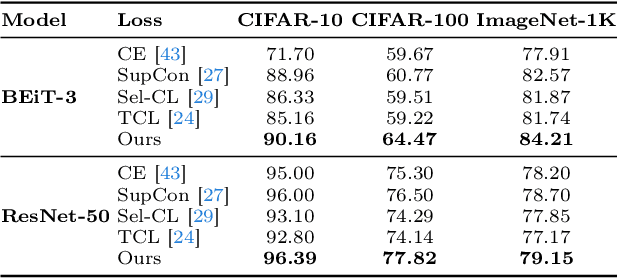
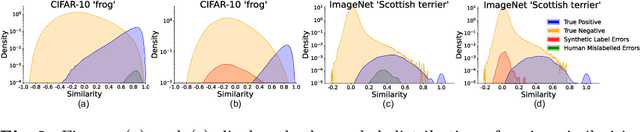
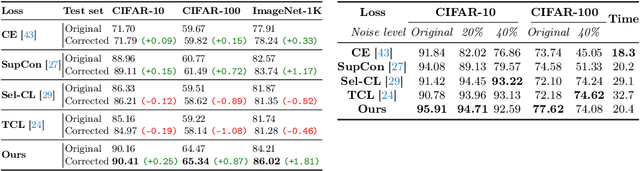
Human-annotated vision datasets inevitably contain a fraction of human mislabelled examples. While the detrimental effects of such mislabelling on supervised learning are well-researched, their influence on Supervised Contrastive Learning (SCL) remains largely unexplored. In this paper, we show that human-labelling errors not only differ significantly from synthetic label errors, but also pose unique challenges in SCL, different to those in traditional supervised learning methods. Specifically, our results indicate they adversely impact the learning process in the ~99% of cases when they occur as false positive samples. Existing noise-mitigating methods primarily focus on synthetic label errors and tackle the unrealistic setting of very high synthetic noise rates (40-80%), but they often underperform on common image datasets due to overfitting. To address this issue, we introduce a novel SCL objective with robustness to human-labelling errors, SCL-RHE. SCL-RHE is designed to mitigate the effects of real-world mislabelled examples, typically characterized by much lower noise rates (<5%). We demonstrate that SCL-RHE consistently outperforms state-of-the-art representation learning and noise-mitigating methods across various vision benchmarks, by offering improved resilience against human-labelling errors.
Text2Pic Swift: Enhancing Long-Text to Image Retrieval for Large-Scale Libraries
Feb 28, 2024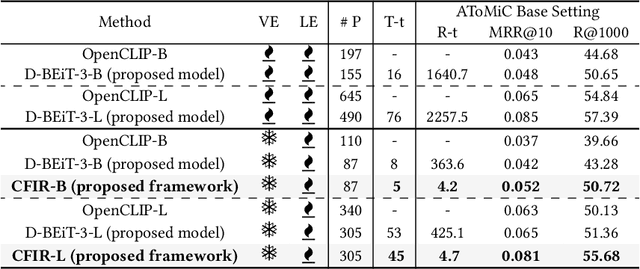
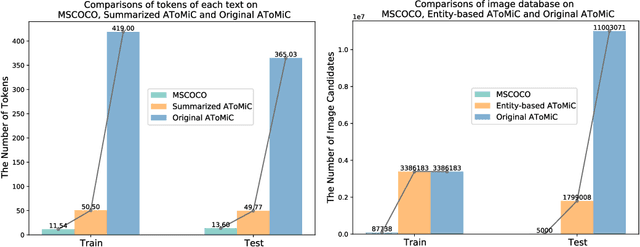
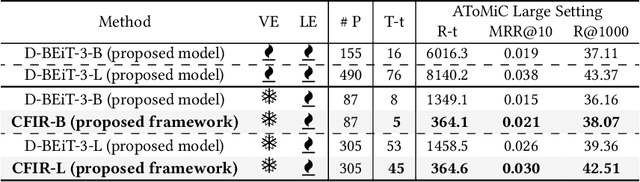
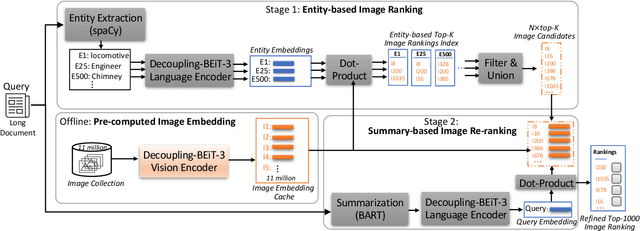
Text-to-image retrieval plays a crucial role across various applications, including digital libraries, e-commerce platforms, and multimedia databases, by enabling the search for images using text queries. Despite the advancements in Multimodal Large Language Models (MLLMs), which offer leading-edge performance, their applicability in large-scale, varied, and ambiguous retrieval scenarios is constrained by significant computational demands and the generation of injective embeddings. This paper introduces the Text2Pic Swift framework, tailored for efficient and robust retrieval of images corresponding to extensive textual descriptions in sizable datasets. The framework employs a two-tier approach: the initial Entity-based Ranking (ER) stage addresses the ambiguity inherent in lengthy text queries through a multiple-queries-to-multiple-targets strategy, effectively narrowing down potential candidates for subsequent analysis. Following this, the Summary-based Re-ranking (SR) stage further refines these selections based on concise query summaries. Additionally, we present a novel Decoupling-BEiT-3 encoder, specifically designed to tackle the challenges of ambiguous queries and to facilitate both stages of the retrieval process, thereby significantly improving computational efficiency via vector-based similarity assessments. Our evaluation, conducted on the AToMiC dataset, demonstrates that Text2Pic Swift outperforms current MLLMs by achieving up to an 11.06% increase in Recall@1000, alongside reductions in training and retrieval durations by 68.75% and 99.79%, respectively.
CLCE: An Approach to Refining Cross-Entropy and Contrastive Learning for Optimized Learning Fusion
Feb 22, 2024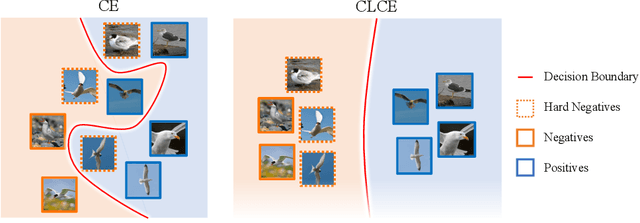
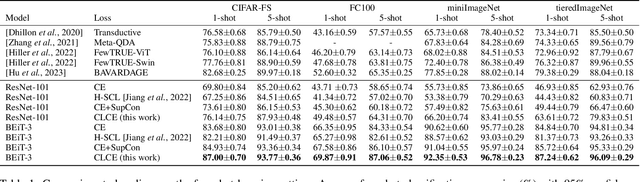
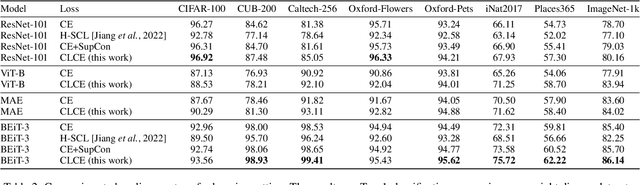
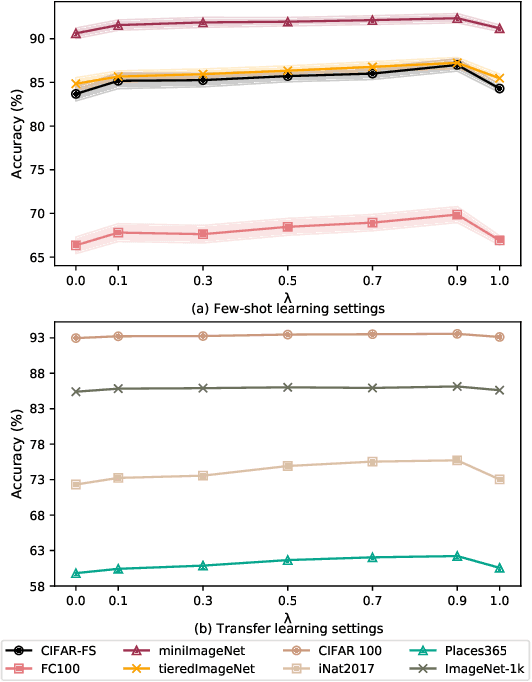
State-of-the-art pre-trained image models predominantly adopt a two-stage approach: initial unsupervised pre-training on large-scale datasets followed by task-specific fine-tuning using Cross-Entropy loss~(CE). However, it has been demonstrated that CE can compromise model generalization and stability. While recent works employing contrastive learning address some of these limitations by enhancing the quality of embeddings and producing better decision boundaries, they often overlook the importance of hard negative mining and rely on resource intensive and slow training using large sample batches. To counter these issues, we introduce a novel approach named CLCE, which integrates Label-Aware Contrastive Learning with CE. Our approach not only maintains the strengths of both loss functions but also leverages hard negative mining in a synergistic way to enhance performance. Experimental results demonstrate that CLCE significantly outperforms CE in Top-1 accuracy across twelve benchmarks, achieving gains of up to 3.52% in few-shot learning scenarios and 3.41% in transfer learning settings with the BEiT-3 model. Importantly, our proposed CLCE approach effectively mitigates the dependency of contrastive learning on large batch sizes such as 4096 samples per batch, a limitation that has previously constrained the application of contrastive learning in budget-limited hardware environments.
CrisisViT: A Robust Vision Transformer for Crisis Image Classification
Jan 05, 2024In times of emergency, crisis response agencies need to quickly and accurately assess the situation on the ground in order to deploy relevant services and resources. However, authorities often have to make decisions based on limited information, as data on affected regions can be scarce until local response services can provide first-hand reports. Fortunately, the widespread availability of smartphones with high-quality cameras has made citizen journalism through social media a valuable source of information for crisis responders. However, analyzing the large volume of images posted by citizens requires more time and effort than is typically available. To address this issue, this paper proposes the use of state-of-the-art deep neural models for automatic image classification/tagging, specifically by adapting transformer-based architectures for crisis image classification (CrisisViT). We leverage the new Incidents1M crisis image dataset to develop a range of new transformer-based image classification models. Through experimentation over the standard Crisis image benchmark dataset, we demonstrate that the CrisisViT models significantly outperform previous approaches in emergency type, image relevance, humanitarian category, and damage severity classification. Additionally, we show that the new Incidents1M dataset can further augment the CrisisViT models resulting in an additional 1.25% absolute accuracy gain.
Elucidating and Overcoming the Challenges of Label Noise in Supervised Contrastive Learning
Nov 25, 2023Image classification datasets exhibit a non-negligible fraction of mislabeled examples, often due to human error when one class superficially resembles another. This issue poses challenges in supervised contrastive learning (SCL), where the goal is to cluster together data points of the same class in the embedding space while distancing those of disparate classes. While such methods outperform those based on cross-entropy, they are not immune to labeling errors. However, while the detrimental effects of noisy labels in supervised learning are well-researched, their influence on SCL remains largely unexplored. Hence, we analyse the effect of label errors and examine how they disrupt the SCL algorithm's ability to distinguish between positive and negative sample pairs. Our analysis reveals that human labeling errors manifest as easy positive samples in around 99% of cases. We, therefore, propose D-SCL, a novel Debiased Supervised Contrastive Learning objective designed to mitigate the bias introduced by labeling errors. We demonstrate that D-SCL consistently outperforms state-of-the-art techniques for representation learning across diverse vision benchmarks, offering improved robustness to label errors.