 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Generative AI Agents Effective Personalized Financial Advisors?
Apr 08, 2025Large language model-based agents are becoming increasingly popular as a low-cost mechanism to provide personalized, conversational advice, and have demonstrated impressive capabilities in relatively simple scenarios, such as movie recommendations. But how do these agents perform in complex high-stakes domains, where domain expertise is essential and mistakes carry substantial risk? This paper investigates the effectiveness of LLM-advisors in the finance domain, focusing on three distinct challenges: (1) eliciting user preferences when users themselves may be unsure of their needs, (2) providing personalized guidance for diverse investment preferences, and (3) leveraging advisor personality to build relationships and foster trust. Via a lab-based user study with 64 participants, we show that LLM-advisors often match human advisor performance when eliciting preferences, although they can struggle to resolve conflicting user needs. When providing personalized advice, the LLM was able to positively influence user behavior, but demonstrated clear failure modes. Our results show that accurate preference elicitation is key, otherwise, the LLM-advisor has little impact, or can even direct the investor toward unsuitable assets. More worryingly, users appear insensitive to the quality of advice being given, or worse these can have an inverse relationship. Indeed, users reported a preference for and increased satisfaction as well as emotional trust with LLMs adopting an extroverted persona, even though those agents provided worse advice.
FAR-Trans: An Investment Dataset for Financial Asset Recommendation
Jul 11, 2024



Financial asset recommendation (FAR) is a sub-domain of recommender systems which identifies useful financial securities for investors, with the expectation that they will invest capital on the recommended assets. FAR solutions analyse and learn from multiple data sources, including time series pricing data, customer profile information and expectations, as well as past investments. However, most models have been developed over proprietary datasets, making a comparison over a common benchmark impossible. In this paper, we aim to solve this problem by introducing FAR-Trans, the first public dataset for FAR, containing pricing information and retail investor transactions acquired from a large European financial institution. We also provide a bench-marking comparison between eleven FAR algorithms over the data for use as future baselines. The dataset can be downloaded from https://doi.org/10.5525/gla.researchdata.1658 .
Understanding and Mitigating Human-Labelling Errors in Supervised Contrastive Learning
Mar 10, 2024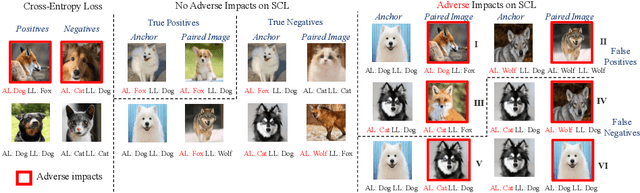
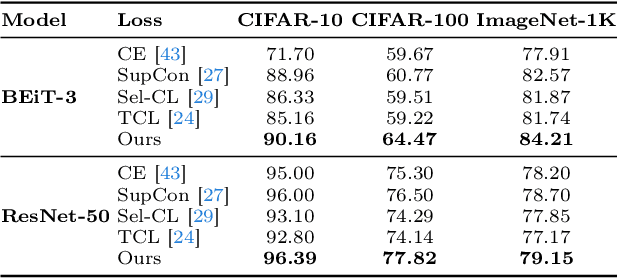
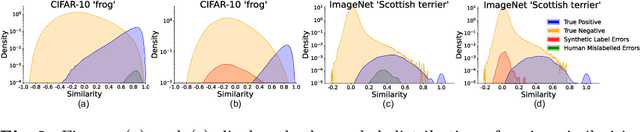
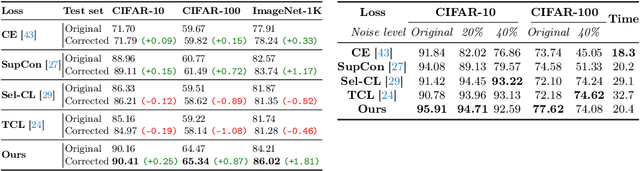
Human-annotated vision datasets inevitably contain a fraction of human mislabelled examples. While the detrimental effects of such mislabelling on supervised learning are well-researched, their influence on Supervised Contrastive Learning (SCL) remains largely unexplored. In this paper, we show that human-labelling errors not only differ significantly from synthetic label errors, but also pose unique challenges in SCL, different to those in traditional supervised learning methods. Specifically, our results indicate they adversely impact the learning process in the ~99% of cases when they occur as false positive samples. Existing noise-mitigating methods primarily focus on synthetic label errors and tackle the unrealistic setting of very high synthetic noise rates (40-80%), but they often underperform on common image datasets due to overfitting. To address this issue, we introduce a novel SCL objective with robustness to human-labelling errors, SCL-RHE. SCL-RHE is designed to mitigate the effects of real-world mislabelled examples, typically characterized by much lower noise rates (<5%). We demonstrate that SCL-RHE consistently outperforms state-of-the-art representation learning and noise-mitigating methods across various vision benchmarks, by offering improved resilience against human-labelling errors.
CrisisViT: A Robust Vision Transformer for Crisis Image Classification
Jan 05, 2024In times of emergency, crisis response agencies need to quickly and accurately assess the situation on the ground in order to deploy relevant services and resources. However, authorities often have to make decisions based on limited information, as data on affected regions can be scarce until local response services can provide first-hand reports. Fortunately, the widespread availability of smartphones with high-quality cameras has made citizen journalism through social media a valuable source of information for crisis responders. However, analyzing the large volume of images posted by citizens requires more time and effort than is typically available. To address this issue, this paper proposes the use of state-of-the-art deep neural models for automatic image classification/tagging, specifically by adapting transformer-based architectures for crisis image classification (CrisisViT). We leverage the new Incidents1M crisis image dataset to develop a range of new transformer-based image classification models. Through experimentation over the standard Crisis image benchmark dataset, we demonstrate that the CrisisViT models significantly outperform previous approaches in emergency type, image relevance, humanitarian category, and damage severity classification. Additionally, we show that the new Incidents1M dataset can further augment the CrisisViT models resulting in an additional 1.25% absolute accuracy gain.
Elucidating and Overcoming the Challenges of Label Noise in Supervised Contrastive Learning
Nov 25, 2023Image classification datasets exhibit a non-negligible fraction of mislabeled examples, often due to human error when one class superficially resembles another. This issue poses challenges in supervised contrastive learning (SCL), where the goal is to cluster together data points of the same class in the embedding space while distancing those of disparate classes. While such methods outperform those based on cross-entropy, they are not immune to labeling errors. However, while the detrimental effects of noisy labels in supervised learning are well-researched, their influence on SCL remains largely unexplored. Hence, we analyse the effect of label errors and examine how they disrupt the SCL algorithm's ability to distinguish between positive and negative sample pairs. Our analysis reveals that human labeling errors manifest as easy positive samples in around 99% of cases. We, therefore, propose D-SCL, a novel Debiased Supervised Contrastive Learning objective designed to mitigate the bias introduced by labeling errors. We demonstrate that D-SCL consistently outperforms state-of-the-art techniques for representation learning across diverse vision benchmarks, offering improved robustness to label errors.
RoboLLM: Robotic Vision Tasks Grounded on Multimodal Large Language Models
Oct 16, 2023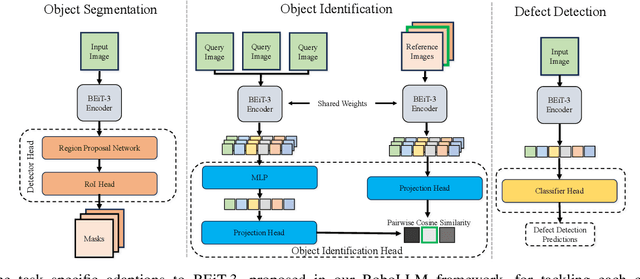
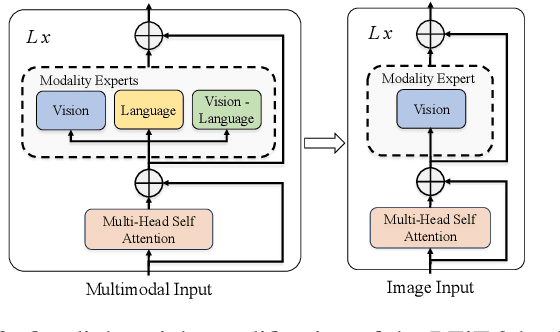

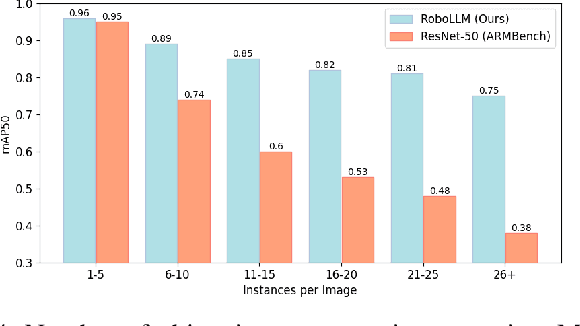
Robotic vision applications often necessitate a wide range of visual perception tasks, such as object detection, segmentation, and identification. While there have been substantial advances in these individual tasks, integrating specialized models into a unified vision pipeline presents significant engineering challenges and costs. Recently, Multimodal Large Language Models (MLLMs) have emerged as novel backbones for various downstream tasks. We argue that leveraging the pre-training capabilities of MLLMs enables the creation of a simplified framework, thus mitigating the need for task-specific encoders. Specifically, the large-scale pretrained knowledge in MLLMs allows for easier fine-tuning to downstream robotic vision tasks and yields superior performance. We introduce the RoboLLM framework, equipped with a BEiT-3 backbone, to address all visual perception tasks in the ARMBench challenge-a large-scale robotic manipulation dataset about real-world warehouse scenarios. RoboLLM not only outperforms existing baselines but also substantially reduces the engineering burden associated with model selection and tuning. The source code is publicly available at https://github.com/longkukuhi/armbench.
MultiWay-Adapater: Adapting large-scale multi-modal models for scalable image-text retrieval
Sep 12, 2023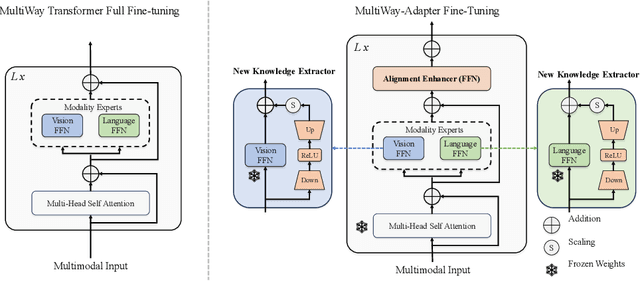
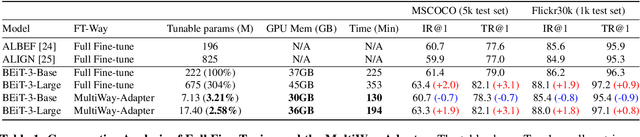

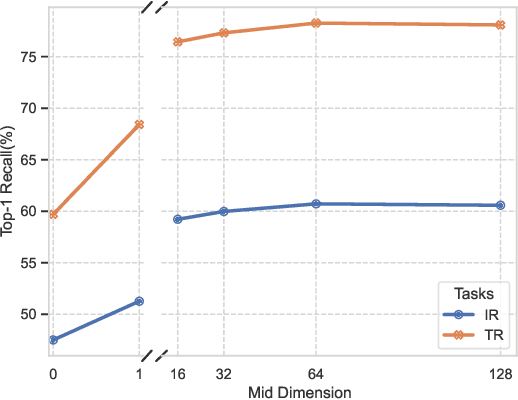
As the size of Large Multi-Modal Models (LMMs) increases consistently, the adaptation of these pre-trained models to specialized tasks has become a computationally and memory-intensive challenge. Traditional fine-tuning methods require isolated, exhaustive retuning for each new task, limiting the models' versatility. Moreover, current efficient adaptation techniques often overlook modality alignment, focusing only on the knowledge extraction of new tasks. To tackle these issues, we introduce Multiway-Adapter, an innovative framework incorporating an 'Alignment Enhancer' to deepen modality alignment, enabling high transferability without tuning pre-trained parameters. Our method adds fewer than 1.25\% of additional parameters to LMMs, exemplified by the BEiT-3 model in our study. This leads to superior zero-shot image-text retrieval performance compared to fully fine-tuned models, while achieving up to a 57\% reduction in fine-tuning time. Our approach offers a resource-efficient and effective adaptation pathway for LMMs, broadening their applicability. The source code is publicly available at: \url{https://github.com/longkukuhi/MultiWay-Adapter}.
When hard negative sampling meets supervised contrastive learning
Aug 28, 2023



State-of-the-art image models predominantly follow a two-stage strategy: pre-training on large datasets and fine-tuning with cross-entropy loss. Many studies have shown that using cross-entropy can result in sub-optimal generalisation and stability. While the supervised contrastive loss addresses some limitations of cross-entropy loss by focusing on intra-class similarities and inter-class differences, it neglects the importance of hard negative mining. We propose that models will benefit from performance improvement by weighting negative samples based on their dissimilarity to positive counterparts. In this paper, we introduce a new supervised contrastive learning objective, SCHaNe, which incorporates hard negative sampling during the fine-tuning phase. Without requiring specialized architectures, additional data, or extra computational resources, experimental results indicate that SCHaNe outperforms the strong baseline BEiT-3 in Top-1 accuracy across various benchmarks, with significant gains of up to $3.32\%$ in few-shot learning settings and $3.41\%$ in full dataset fine-tuning. Importantly, our proposed objective sets a new state-of-the-art for base models on ImageNet-1k, achieving an 86.14\% accuracy. Furthermore, we demonstrate that the proposed objective yields better embeddings and explains the improved effectiveness observed in our experiments.
LaCViT: A Label-aware Contrastive Training Framework for Vision Transformers
Mar 31, 2023



Vision Transformers have been incredibly effective when tackling computer vision tasks due to their ability to model long feature dependencies. By using large-scale training data and various self-supervised signals (e.g., masked random patches), vision transformers provide state-of-the-art performance on several benchmarking datasets, such as ImageNet-1k and CIFAR-10. However, these vision transformers pretrained over general large-scale image corpora could only produce an anisotropic representation space, limiting their generalizability and transferability to the target downstream tasks. In this paper, we propose a simple and effective Label-aware Contrastive Training framework LaCViT, which improves the isotropy of the pretrained representation space for vision transformers, thereby enabling more effective transfer learning amongst a wide range of image classification tasks. Through experimentation over five standard image classification datasets, we demonstrate that LaCViT-trained models outperform the original pretrained baselines by around 9% absolute Accuracy@1, and consistent improvements can be observed when applying LaCViT to our three evaluated vision transformers.
Divergence-Based Domain Transferability for Zero-Shot Classification
Feb 28, 2023Transferring learned patterns from pretrained neural language models has been shown to significantly improve effectiveness across a variety of language-based tasks, meanwhile further tuning on intermediate tasks has been demonstrated to provide additional performance benefits, provided the intermediate task is sufficiently related to the target task. However, how to identify related tasks is an open problem, and brute-force searching effective task combinations is prohibitively expensive. Hence, the question arises, are we able to improve the effectiveness and efficiency of tasks with no training examples through selective fine-tuning? In this paper, we explore statistical measures that approximate the divergence between domain representations as a means to estimate whether tuning using one task pair will exhibit performance benefits over tuning another. This estimation can then be used to reduce the number of task pairs that need to be tested by eliminating pairs that are unlikely to provide benefits. Through experimentation over 58 tasks and over 6,600 task pair combinations, we demonstrate that statistical measures can distinguish effective task pairs, and the resulting estimates can reduce end-to-end runtime by up to 40%.