 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Generative Policy for Robotic Control
Dec 09, 2025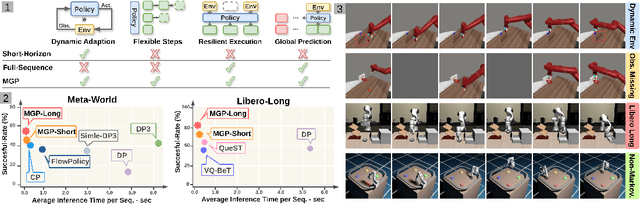

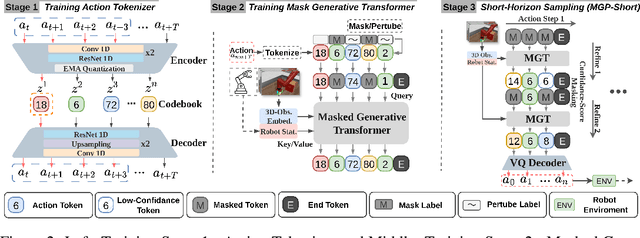

We present Masked Generative Policy (MGP), a novel framework for visuomotor imitation learning. We represent actions as discrete tokens, and train a conditional masked transformer that generates tokens in parallel and then rapidly refines only low-confidence tokens. We further propose two new sampling paradigms: MGP-Short, which performs parallel masked generation with score-based refinement for Markovian tasks, and MGP-Long, which predicts full trajectories in a single pass and dynamically refines low-confidence action tokens based on new observations. With globally coherent prediction and robust adaptive execution capabilities, MGP-Long enables reliable control on complex and non-Markovian tasks that prior methods struggle with. Extensive evaluations on 150 robotic manipulation tasks spanning the Meta-World and LIBERO benchmarks show that MGP achieves both rapid inference and superior success rates compared to state-of-the-art diffusion and autoregressive policies. Specifically, MGP increases the average success rate by 9% across 150 tasks while cutting per-sequence inference time by up to 35x. It further improves the average success rate by 60% in dynamic and missing-observation environments, and solves two non-Markovian scenarios where other state-of-the-art methods fail.
Can Real-to-Sim Approaches Capture Dynamic Fabric Behavior for Robotic Fabric Manipulation?
Mar 20, 2025This paper presents a rigorous evaluation of Real-to-Sim parameter estimation approaches for fabric manipulation in robotics. The study systematically assesses three state-of-the-art approaches, namely two differential pipelines and a data-driven approach. We also devise a novel physics-informed neural network approach for physics parameter estimation. These approaches are interfaced with two simulations across multiple Real-to-Sim scenarios (lifting, wind blowing, and stretching) for five different fabric types and evaluated on three unseen scenarios (folding, fling, and shaking). We found that the simulation engines and the choice of Real-to-Sim approaches significantly impact fabric manipulation performance in our evaluation scenarios. Moreover, PINN observes superior performance in quasi-static tasks but shows limitations in dynamic scenarios.
Flat'n'Fold: A Diverse Multi-Modal Dataset for Garment Perception and Manipulation
Sep 26, 2024



We present Flat'n'Fold, a novel large-scale dataset for garment manipulation that addresses critical gaps in existing datasets. Comprising 1,212 human and 887 robot demonstrations of flattening and folding 44 unique garments across 8 categories, Flat'n'Fold surpasses prior datasets in size, scope, and diversity. Our dataset uniquely captures the entire manipulation process from crumpled to folded states, providing synchronized multi-view RGB-D images, point clouds, and action data, including hand or gripper positions and rotations. We quantify the dataset's diversity and complexity compared to existing benchmarks and show that our dataset features natural and diverse manipulations of real-world demonstrations of human and robot demonstrations in terms of visual and action information. To showcase Flat'n'Fold's utility, we establish new benchmarks for grasping point prediction and subtask decomposition. Our evaluation of state-of-the-art models on these tasks reveals significant room for improvement. This underscores Flat'n'Fold's potential to drive advances in robotic perception and manipulation of deformable objects. Our dataset can be downloaded at https://cvas-ug.github.io/flat-n-fold
Understanding and Mitigating Human-Labelling Errors in Supervised Contrastive Learning
Mar 10, 2024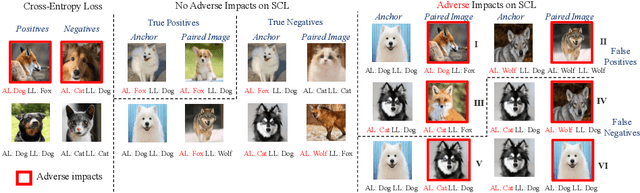
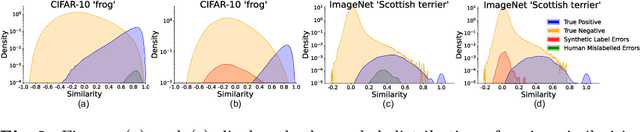
Human-annotated vision datasets inevitably contain a fraction of human mislabelled examples. While the detrimental effects of such mislabelling on supervised learning are well-researched, their influence on Supervised Contrastive Learning (SCL) remains largely unexplored. In this paper, we show that human-labelling errors not only differ significantly from synthetic label errors, but also pose unique challenges in SCL, different to those in traditional supervised learning methods. Specifically, our results indicate they adversely impact the learning process in the ~99% of cases when they occur as false positive samples. Existing noise-mitigating methods primarily focus on synthetic label errors and tackle the unrealistic setting of very high synthetic noise rates (40-80%), but they often underperform on common image datasets due to overfitting. To address this issue, we introduce a novel SCL objective with robustness to human-labelling errors, SCL-RHE. SCL-RHE is designed to mitigate the effects of real-world mislabelled examples, typically characterized by much lower noise rates (<5%). We demonstrate that SCL-RHE consistently outperforms state-of-the-art representation learning and noise-mitigating methods across various vision benchmarks, by offering improved resilience against human-labelling errors.
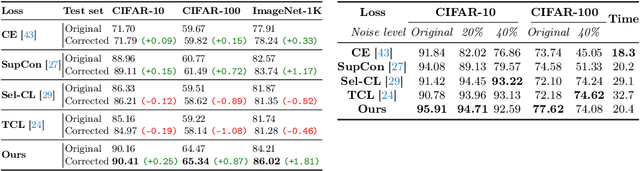
CLCE: An Approach to Refining Cross-Entropy and Contrastive Learning for Optimized Learning Fusion
Feb 22, 2024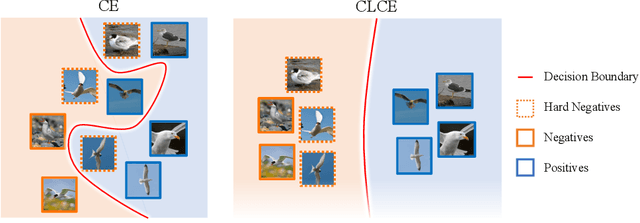
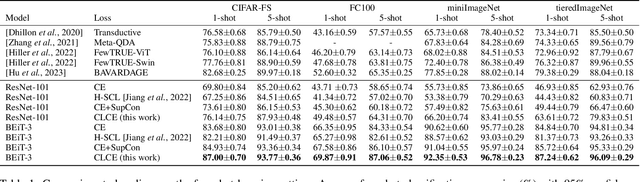
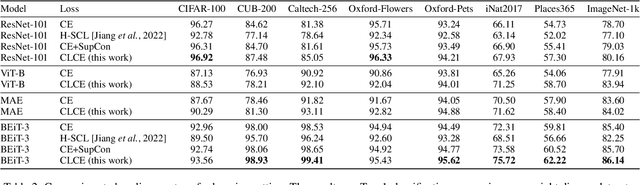
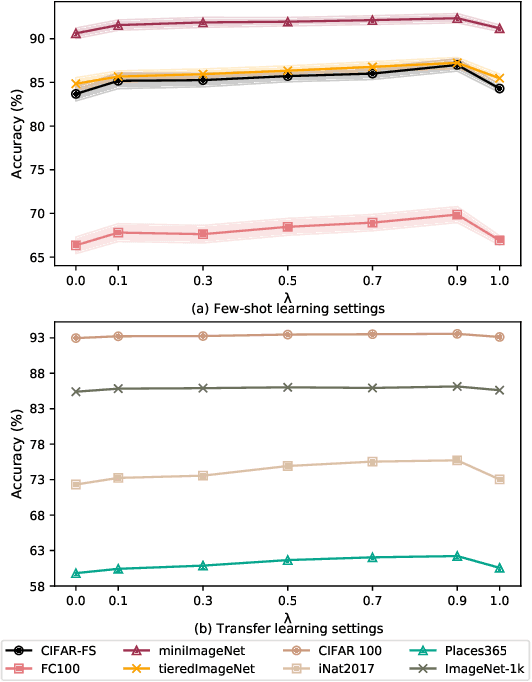
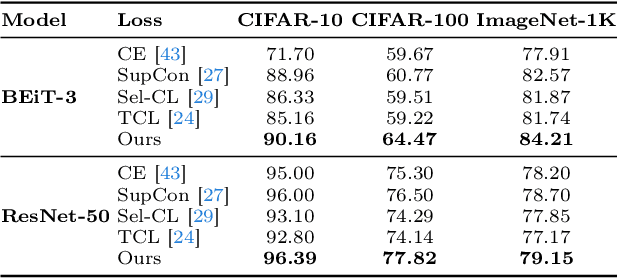
State-of-the-art pre-trained image models predominantly adopt a two-stage approach: initial unsupervised pre-training on large-scale datasets followed by task-specific fine-tuning using Cross-Entropy loss~(CE). However, it has been demonstrated that CE can compromise model generalization and stability. While recent works employing contrastive learning address some of these limitations by enhancing the quality of embeddings and producing better decision boundaries, they often overlook the importance of hard negative mining and rely on resource intensive and slow training using large sample batches. To counter these issues, we introduce a novel approach named CLCE, which integrates Label-Aware Contrastive Learning with CE. Our approach not only maintains the strengths of both loss functions but also leverages hard negative mining in a synergistic way to enhance performance. Experimental results demonstrate that CLCE significantly outperforms CE in Top-1 accuracy across twelve benchmarks, achieving gains of up to 3.52% in few-shot learning scenarios and 3.41% in transfer learning settings with the BEiT-3 model. Importantly, our proposed CLCE approach effectively mitigates the dependency of contrastive learning on large batch sizes such as 4096 samples per batch, a limitation that has previously constrained the application of contrastive learning in budget-limited hardware environments.
Elucidating and Overcoming the Challenges of Label Noise in Supervised Contrastive Learning
Nov 25, 2023Image classification datasets exhibit a non-negligible fraction of mislabeled examples, often due to human error when one class superficially resembles another. This issue poses challenges in supervised contrastive learning (SCL), where the goal is to cluster together data points of the same class in the embedding space while distancing those of disparate classes. While such methods outperform those based on cross-entropy, they are not immune to labeling errors. However, while the detrimental effects of noisy labels in supervised learning are well-researched, their influence on SCL remains largely unexplored. Hence, we analyse the effect of label errors and examine how they disrupt the SCL algorithm's ability to distinguish between positive and negative sample pairs. Our analysis reveals that human labeling errors manifest as easy positive samples in around 99% of cases. We, therefore, propose D-SCL, a novel Debiased Supervised Contrastive Learning objective designed to mitigate the bias introduced by labeling errors. We demonstrate that D-SCL consistently outperforms state-of-the-art techniques for representation learning across diverse vision benchmarks, offering improved robustness to label errors.