 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Mitigating Human-Labelling Errors in Supervised Contrastive Learning
Mar 10, 2024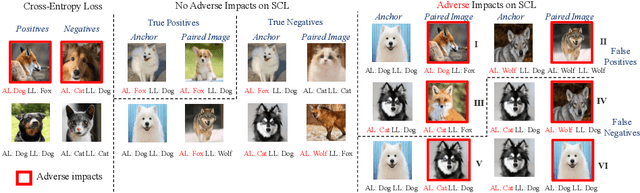
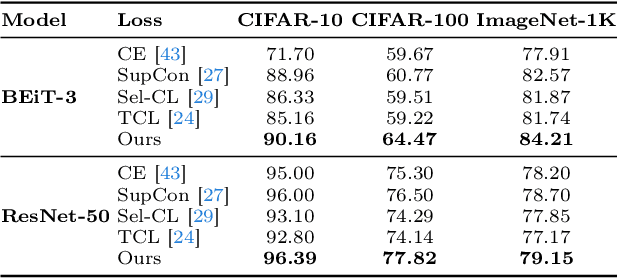
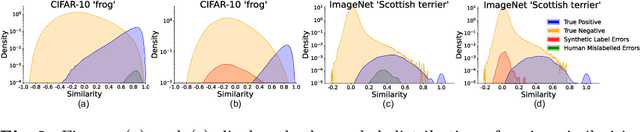
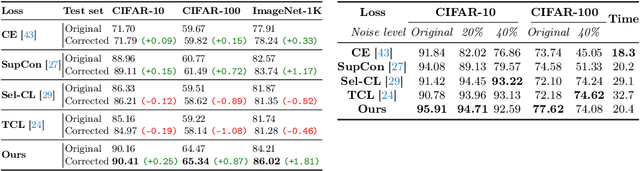
Human-annotated vision datasets inevitably contain a fraction of human mislabelled examples. While the detrimental effects of such mislabelling on supervised learning are well-researched, their influence on Supervised Contrastive Learning (SCL) remains largely unexplored. In this paper, we show that human-labelling errors not only differ significantly from synthetic label errors, but also pose unique challenges in SCL, different to those in traditional supervised learning methods. Specifically, our results indicate they adversely impact the learning process in the ~99% of cases when they occur as false positive samples. Existing noise-mitigating methods primarily focus on synthetic label errors and tackle the unrealistic setting of very high synthetic noise rates (40-80%), but they often underperform on common image datasets due to overfitting. To address this issue, we introduce a novel SCL objective with robustness to human-labelling errors, SCL-RHE. SCL-RHE is designed to mitigate the effects of real-world mislabelled examples, typically characterized by much lower noise rates (<5%). We demonstrate that SCL-RHE consistently outperforms state-of-the-art representation learning and noise-mitigating methods across various vision benchmarks, by offering improved resilience against human-labelling errors.
CLCE: An Approach to Refining Cross-Entropy and Contrastive Learning for Optimized Learning Fusion
Feb 22, 2024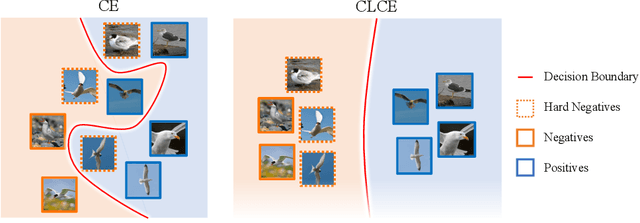
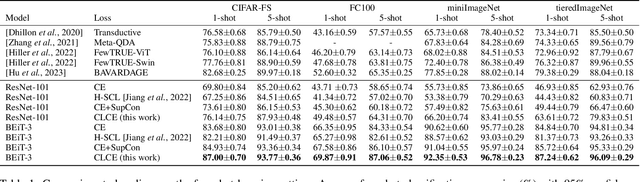
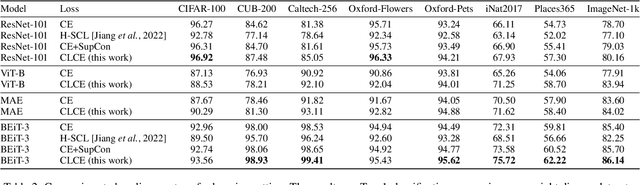
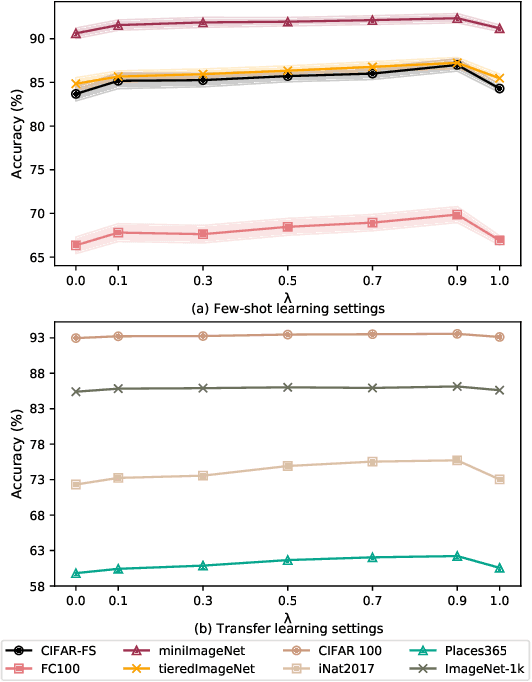
State-of-the-art pre-trained image models predominantly adopt a two-stage approach: initial unsupervised pre-training on large-scale datasets followed by task-specific fine-tuning using Cross-Entropy loss~(CE). However, it has been demonstrated that CE can compromise model generalization and stability. While recent works employing contrastive learning address some of these limitations by enhancing the quality of embeddings and producing better decision boundaries, they often overlook the importance of hard negative mining and rely on resource intensive and slow training using large sample batches. To counter these issues, we introduce a novel approach named CLCE, which integrates Label-Aware Contrastive Learning with CE. Our approach not only maintains the strengths of both loss functions but also leverages hard negative mining in a synergistic way to enhance performance. Experimental results demonstrate that CLCE significantly outperforms CE in Top-1 accuracy across twelve benchmarks, achieving gains of up to 3.52% in few-shot learning scenarios and 3.41% in transfer learning settings with the BEiT-3 model. Importantly, our proposed CLCE approach effectively mitigates the dependency of contrastive learning on large batch sizes such as 4096 samples per batch, a limitation that has previously constrained the application of contrastive learning in budget-limited hardware environments.
Foveation in the Era of Deep Learning
Dec 03, 2023



In this paper, we tackle the challenge of actively attending to visual scenes using a foveated sensor. We introduce an end-to-end differentiable foveated active vision architecture that leverages a graph convolutional network to process foveated images, and a simple yet effective formulation for foveated image sampling. Our model learns to iteratively attend to regions of the image relevant for classification. We conduct detailed experiments on a variety of image datasets, comparing the performance of our method with previous approaches to foveated vision while measuring how the impact of different choices, such as the degree of foveation, and the number of fixations the network performs, affect object recognition performance. We find that our model outperforms a state-of-the-art CNN and foveated vision architectures of comparable parameters and a given pixel or computation budget
Elucidating and Overcoming the Challenges of Label Noise in Supervised Contrastive Learning
Nov 25, 2023Image classification datasets exhibit a non-negligible fraction of mislabeled examples, often due to human error when one class superficially resembles another. This issue poses challenges in supervised contrastive learning (SCL), where the goal is to cluster together data points of the same class in the embedding space while distancing those of disparate classes. While such methods outperform those based on cross-entropy, they are not immune to labeling errors. However, while the detrimental effects of noisy labels in supervised learning are well-researched, their influence on SCL remains largely unexplored. Hence, we analyse the effect of label errors and examine how they disrupt the SCL algorithm's ability to distinguish between positive and negative sample pairs. Our analysis reveals that human labeling errors manifest as easy positive samples in around 99% of cases. We, therefore, propose D-SCL, a novel Debiased Supervised Contrastive Learning objective designed to mitigate the bias introduced by labeling errors. We demonstrate that D-SCL consistently outperforms state-of-the-art techniques for representation learning across diverse vision benchmarks, offering improved robustness to label errors.
RoboLLM: Robotic Vision Tasks Grounded on Multimodal Large Language Models
Oct 16, 2023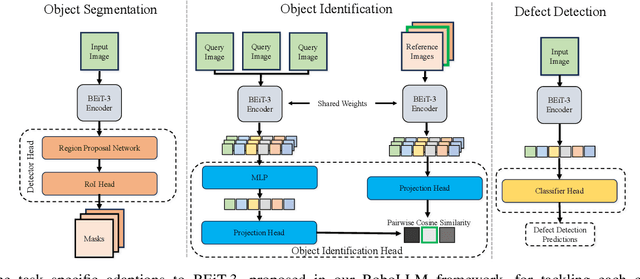
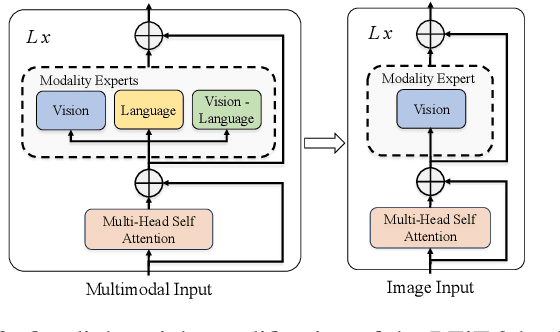

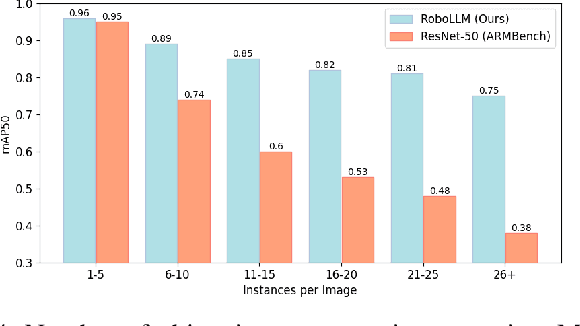
Robotic vision applications often necessitate a wide range of visual perception tasks, such as object detection, segmentation, and identification. While there have been substantial advances in these individual tasks, integrating specialized models into a unified vision pipeline presents significant engineering challenges and costs. Recently, Multimodal Large Language Models (MLLMs) have emerged as novel backbones for various downstream tasks. We argue that leveraging the pre-training capabilities of MLLMs enables the creation of a simplified framework, thus mitigating the need for task-specific encoders. Specifically, the large-scale pretrained knowledge in MLLMs allows for easier fine-tuning to downstream robotic vision tasks and yields superior performance. We introduce the RoboLLM framework, equipped with a BEiT-3 backbone, to address all visual perception tasks in the ARMBench challenge-a large-scale robotic manipulation dataset about real-world warehouse scenarios. RoboLLM not only outperforms existing baselines but also substantially reduces the engineering burden associated with model selection and tuning. The source code is publicly available at https://github.com/longkukuhi/armbench.
MultiWay-Adapater: Adapting large-scale multi-modal models for scalable image-text retrieval
Sep 12, 2023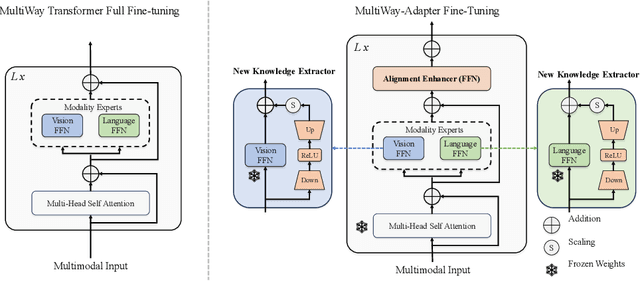
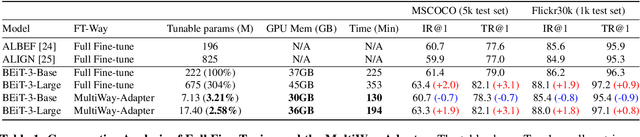

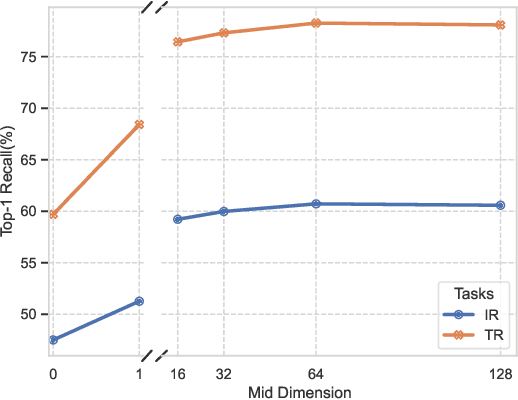
As the size of Large Multi-Modal Models (LMMs) increases consistently, the adaptation of these pre-trained models to specialized tasks has become a computationally and memory-intensive challenge. Traditional fine-tuning methods require isolated, exhaustive retuning for each new task, limiting the models' versatility. Moreover, current efficient adaptation techniques often overlook modality alignment, focusing only on the knowledge extraction of new tasks. To tackle these issues, we introduce Multiway-Adapter, an innovative framework incorporating an 'Alignment Enhancer' to deepen modality alignment, enabling high transferability without tuning pre-trained parameters. Our method adds fewer than 1.25\% of additional parameters to LMMs, exemplified by the BEiT-3 model in our study. This leads to superior zero-shot image-text retrieval performance compared to fully fine-tuned models, while achieving up to a 57\% reduction in fine-tuning time. Our approach offers a resource-efficient and effective adaptation pathway for LMMs, broadening their applicability. The source code is publicly available at: \url{https://github.com/longkukuhi/MultiWay-Adapter}.
When hard negative sampling meets supervised contrastive learning
Aug 28, 2023



State-of-the-art image models predominantly follow a two-stage strategy: pre-training on large datasets and fine-tuning with cross-entropy loss. Many studies have shown that using cross-entropy can result in sub-optimal generalisation and stability. While the supervised contrastive loss addresses some limitations of cross-entropy loss by focusing on intra-class similarities and inter-class differences, it neglects the importance of hard negative mining. We propose that models will benefit from performance improvement by weighting negative samples based on their dissimilarity to positive counterparts. In this paper, we introduce a new supervised contrastive learning objective, SCHaNe, which incorporates hard negative sampling during the fine-tuning phase. Without requiring specialized architectures, additional data, or extra computational resources, experimental results indicate that SCHaNe outperforms the strong baseline BEiT-3 in Top-1 accuracy across various benchmarks, with significant gains of up to $3.32\%$ in few-shot learning settings and $3.41\%$ in full dataset fine-tuning. Importantly, our proposed objective sets a new state-of-the-art for base models on ImageNet-1k, achieving an 86.14\% accuracy. Furthermore, we demonstrate that the proposed objective yields better embeddings and explains the improved effectiveness observed in our experiments.