 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating Hallucination in Diffusion-Augmented Interactive Text-to-Image Retrieval
Jan 28, 2026Diffusion-Augmented Interactive Text-to-Image Retrieval (DAI-TIR) is a promising paradigm that improves retrieval performance by generating query images via diffusion models and using them as additional ``views'' of the user's intent. However, these generative views can be incorrect because diffusion generation may introduce hallucinated visual cues that conflict with the original query text. Indeed, we empirically demonstrate that these hallucinated cues can substantially degrade DAI-TIR performance. To address this, we propose Diffusion-aware Multi-view Contrastive Learning (DMCL), a hallucination-robust training framework that casts DAI-TIR as joint optimization over representations of query intent and the target image. DMCL introduces semantic-consistency and diffusion-aware contrastive objectives to align textual and diffusion-generated query views while suppressing hallucinated query signals. This yields an encoder that acts as a semantic filter, effectively mapping hallucinated cues into a null space, improving robustness to spurious cues and better representing the user's intent. Attention visualization and geometric embedding-space analyses corroborate this filtering behavior. Across five standard benchmarks, DMCL delivers consistent improvements in multi-round Hits@10, reaching as high as 7.37\% over prior fine-tuned and zero-shot baselines, which indicates it is a general and robust training framework for DAI-TIR.
Zero-Shot Interactive Text-to-Image Retrieval via Diffusion-Augmented Representations
Jan 26, 2025



Interactive Text-to-Image Retrieval (I-TIR) has emerged as a transformative user-interactive tool for applications in domains such as e-commerce and education. Yet, current methodologies predominantly depend on finetuned Multimodal Large Language Models (MLLMs), which face two critical limitations: (1) Finetuning imposes prohibitive computational overhead and long-term maintenance costs. (2) Finetuning narrows the pretrained knowledge distribution of MLLMs, reducing their adaptability to novel scenarios. These issues are exacerbated by the inherently dynamic nature of real-world I-TIR systems, where queries and image databases evolve in complexity and diversity, often deviating from static training distributions. To overcome these constraints, we propose Diffusion Augmented Retrieval (DAR), a paradigm-shifting framework that bypasses MLLM finetuning entirely. DAR synergizes Large Language Model (LLM)-guided query refinement with Diffusion Model (DM)-based visual synthesis to create contextually enriched intermediate representations. This dual-modality approach deciphers nuanced user intent more holistically, enabling precise alignment between textual queries and visually relevant images. Rigorous evaluations across four benchmarks reveal DAR's dual strengths: (1) Matches state-of-the-art finetuned I-TIR models on straightforward queries without task-specific training. (2) Scalable Generalization: Surpasses finetuned baselines by 7.61% in Hits@10 (top-10 accuracy) under multi-turn conversational complexity, demonstrating robustness to intricate, distributionally shifted interactions. By eliminating finetuning dependencies and leveraging generative-augmented representations, DAR establishes a new trajectory for efficient, adaptive, and scalable cross-modal retrieval systems.
Text2Pic Swift: Enhancing Long-Text to Image Retrieval for Large-Scale Libraries
Feb 28, 2024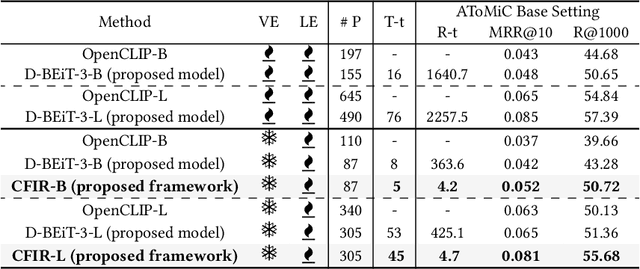
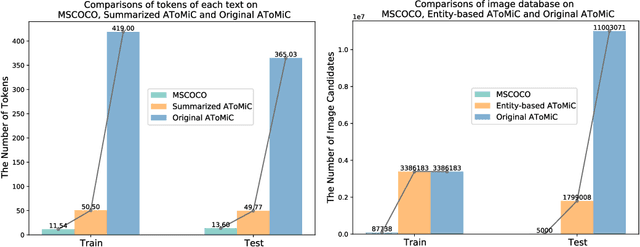
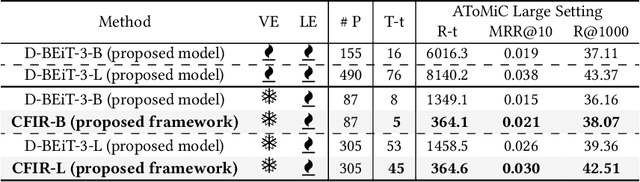
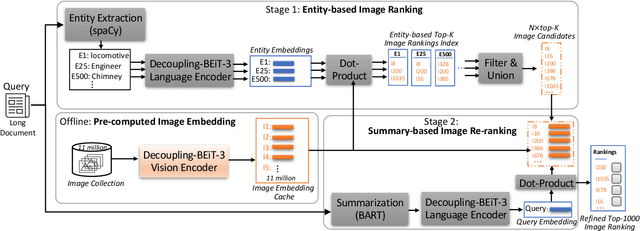
Text-to-image retrieval plays a crucial role across various applications, including digital libraries, e-commerce platforms, and multimedia databases, by enabling the search for images using text queries. Despite the advancements in Multimodal Large Language Models (MLLMs), which offer leading-edge performance, their applicability in large-scale, varied, and ambiguous retrieval scenarios is constrained by significant computational demands and the generation of injective embeddings. This paper introduces the Text2Pic Swift framework, tailored for efficient and robust retrieval of images corresponding to extensive textual descriptions in sizable datasets. The framework employs a two-tier approach: the initial Entity-based Ranking (ER) stage addresses the ambiguity inherent in lengthy text queries through a multiple-queries-to-multiple-targets strategy, effectively narrowing down potential candidates for subsequent analysis. Following this, the Summary-based Re-ranking (SR) stage further refines these selections based on concise query summaries. Additionally, we present a novel Decoupling-BEiT-3 encoder, specifically designed to tackle the challenges of ambiguous queries and to facilitate both stages of the retrieval process, thereby significantly improving computational efficiency via vector-based similarity assessments. Our evaluation, conducted on the AToMiC dataset, demonstrates that Text2Pic Swift outperforms current MLLMs by achieving up to an 11.06% increase in Recall@1000, alongside reductions in training and retrieval durations by 68.75% and 99.79%, respectively.
CLCE: An Approach to Refining Cross-Entropy and Contrastive Learning for Optimized Learning Fusion
Feb 22, 2024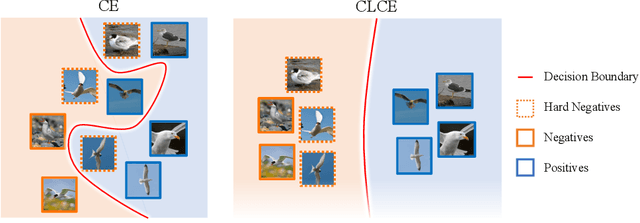
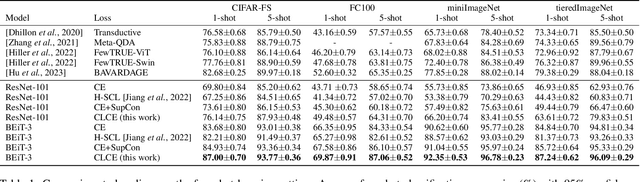
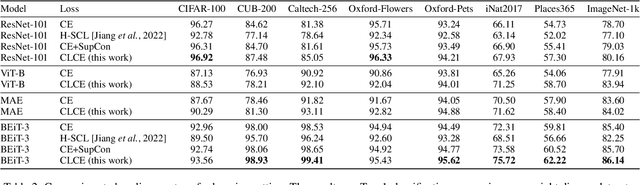
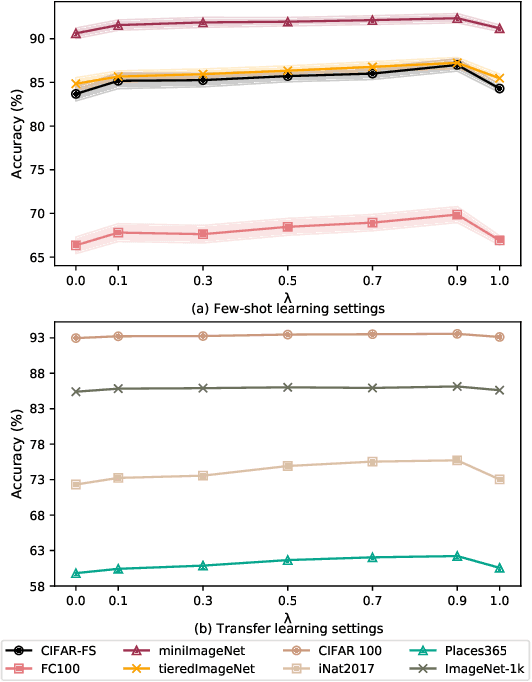
State-of-the-art pre-trained image models predominantly adopt a two-stage approach: initial unsupervised pre-training on large-scale datasets followed by task-specific fine-tuning using Cross-Entropy loss~(CE). However, it has been demonstrated that CE can compromise model generalization and stability. While recent works employing contrastive learning address some of these limitations by enhancing the quality of embeddings and producing better decision boundaries, they often overlook the importance of hard negative mining and rely on resource intensive and slow training using large sample batches. To counter these issues, we introduce a novel approach named CLCE, which integrates Label-Aware Contrastive Learning with CE. Our approach not only maintains the strengths of both loss functions but also leverages hard negative mining in a synergistic way to enhance performance. Experimental results demonstrate that CLCE significantly outperforms CE in Top-1 accuracy across twelve benchmarks, achieving gains of up to 3.52% in few-shot learning scenarios and 3.41% in transfer learning settings with the BEiT-3 model. Importantly, our proposed CLCE approach effectively mitigates the dependency of contrastive learning on large batch sizes such as 4096 samples per batch, a limitation that has previously constrained the application of contrastive learning in budget-limited hardware environments.
Large Multi-modal Encoders for Recommendation
Nov 03, 2023



In recent years, the rapid growth of online multimedia services, such as e-commerce platforms, has necessitated the development of personalised recommendation approaches that can encode diverse content about each item. Indeed, modern multi-modal recommender systems exploit diverse features obtained from raw images and item descriptions to enhance the recommendation performance. However, the existing multi-modal recommenders primarily depend on the features extracted individually from different media through pre-trained modality-specific encoders, and exhibit only shallow alignments between different modalities - limiting these systems' ability to capture the underlying relationships between the modalities. In this paper, we investigate the usage of large multi-modal encoders within the specific context of recommender systems, as these have previously demonstrated state-of-the-art effectiveness when ranking items across various domains. Specifically, we tailor two state-of-the-art multi-modal encoders (CLIP and VLMo) for recommendation tasks using a range of strategies, including the exploration of pre-trained and fine-tuned encoders, as well as the assessment of the end-to-end training of these encoders. We demonstrate that pre-trained large multi-modal encoders can generate more aligned and effective user/item representations compared to existing modality-specific encoders across three multi-modal recommendation datasets. Furthermore, we show that fine-tuning these large multi-modal encoders with recommendation datasets leads to an enhanced recommendation performance. In terms of different training paradigms, our experiments highlight the essential role of the end-to-end training of large multi-modal encoders in multi-modal recommendation systems.