 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Training Necessary for Anomaly Detection?
Jan 30, 2026Current state-of-the-art multi-class unsupervised anomaly detection (MUAD) methods rely on training encoder-decoder models to reconstruct anomaly-free features. We first show these approaches have an inherent fidelity-stability dilemma in how they detect anomalies via reconstruction residuals. We then abandon the reconstruction paradigm entirely and propose Retrieval-based Anomaly Detection (RAD). RAD is a training-free approach that stores anomaly-free features in a memory and detects anomalies through multi-level retrieval, matching test patches against the memory. Experiments demonstrate that RAD achieves state-of-the-art performance across four established benchmarks (MVTec-AD, VisA, Real-IAD, 3D-ADAM) under both standard and few-shot settings. On MVTec-AD, RAD reaches 96.7\% Pixel AUROC with just a single anomaly-free image compared to 98.5\% of RAD's full-data performance. We further prove that retrieval-based scores theoretically upper-bound reconstruction-residual scores. Collectively, these findings overturn the assumption that MUAD requires task-specific training, showing that state-of-the-art anomaly detection is feasible with memory-based retrieval. Our code is available at https://github.com/longkukuhi/RAD.
3D-ADAM: A Dataset for 3D Anomaly Detection in Advanced Manufacturing
Jul 10, 2025Surface defects are one of the largest contributors to low yield in the manufacturing sector. Accurate and reliable detection of defects during the manufacturing process is therefore of great value across the sector. State-of-the-art approaches to automated defect detection yield impressive performance on current datasets, yet still fall short in real-world manufacturing settings and developing improved methods relies on large datasets representative of real-world scenarios. Unfortunately, high-quality, high-precision RGB+3D industrial anomaly detection datasets are scarce, and typically do not reflect real-world industrial deployment scenarios. To address this, we introduce 3D-ADAM, the first large-scale industry-relevant dataset for high-precision 3D Anomaly Detection. 3D-ADAM comprises 14,120 high-resolution scans across 217 unique parts, captured using 4 industrial depth imaging sensors. It includes 27,346 annotated defect instances from 12 categories, covering the breadth of industrial surface defects. 3D-ADAM uniquely captures an additional 8,110 annotations of machine element features, spanning the range of relevant mechanical design form factors. Unlike existing datasets, 3D-ADAM is captured in a real industrial environment with variations in part position and orientation, camera positioning, ambient lighting conditions, as well as partial occlusions. Our evaluation of SOTA models across various RGB+3D anomaly detection tasks demonstrates the significant challenge this dataset presents to current approaches. We further validated the industrial relevance and quality of the dataset through an expert labelling survey conducted by industry partners. By providing this challenging benchmark, 3D-ADAM aims to accelerate the development of robust 3D Anomaly Detection models capable of meeting the demands of modern manufacturing environments.
Curio: A Cost-Effective Solution for Robotics Education
May 24, 2025Student engagement is one of the key challenges in robotics and artificial intelligence (AI) education. Tangible learning approaches, such as educational robots, provide an effective way to enhance engagement and learning by offering real-world applications to bridge the gap between theory and practice. However, existing platforms often face barriers such as high cost or limited capabilities. In this paper, we present Curio, a cost-effective, smartphone-integrated robotics platform designed to lower the entry barrier to robotics and AI education. With a retail price below $50, Curio is more affordable than similar platforms. By leveraging smartphones, Curio eliminates the need for onboard processing units, dedicated cameras, and additional sensors while maintaining the ability to perform AI-based tasks. To evaluate the impact of Curio on student engagement, we conducted a case study with 20 participants, where we examined usability, engagement, and potential for integrating into AI and robotics education. The results indicate high engagement and motivation levels across all participants. Additionally, 95% of participants reported an improvement in their understanding of robotics. Findings suggest that using a robotic system such as Curio can enhance engagement and hands-on learning in robotics and AI education. All resources and projects with Curio are available at trycurio.com.
Zero-Shot Interactive Text-to-Image Retrieval via Diffusion-Augmented Representations
Jan 26, 2025



Interactive Text-to-Image Retrieval (I-TIR) has emerged as a transformative user-interactive tool for applications in domains such as e-commerce and education. Yet, current methodologies predominantly depend on finetuned Multimodal Large Language Models (MLLMs), which face two critical limitations: (1) Finetuning imposes prohibitive computational overhead and long-term maintenance costs. (2) Finetuning narrows the pretrained knowledge distribution of MLLMs, reducing their adaptability to novel scenarios. These issues are exacerbated by the inherently dynamic nature of real-world I-TIR systems, where queries and image databases evolve in complexity and diversity, often deviating from static training distributions. To overcome these constraints, we propose Diffusion Augmented Retrieval (DAR), a paradigm-shifting framework that bypasses MLLM finetuning entirely. DAR synergizes Large Language Model (LLM)-guided query refinement with Diffusion Model (DM)-based visual synthesis to create contextually enriched intermediate representations. This dual-modality approach deciphers nuanced user intent more holistically, enabling precise alignment between textual queries and visually relevant images. Rigorous evaluations across four benchmarks reveal DAR's dual strengths: (1) Matches state-of-the-art finetuned I-TIR models on straightforward queries without task-specific training. (2) Scalable Generalization: Surpasses finetuned baselines by 7.61% in Hits@10 (top-10 accuracy) under multi-turn conversational complexity, demonstrating robustness to intricate, distributionally shifted interactions. By eliminating finetuning dependencies and leveraging generative-augmented representations, DAR establishes a new trajectory for efficient, adaptive, and scalable cross-modal retrieval systems.
Breaking Down the Barriers: Investigating Non-Expert User Experiences in Robotic Teleoperation in UK and Japan
Oct 24, 2024
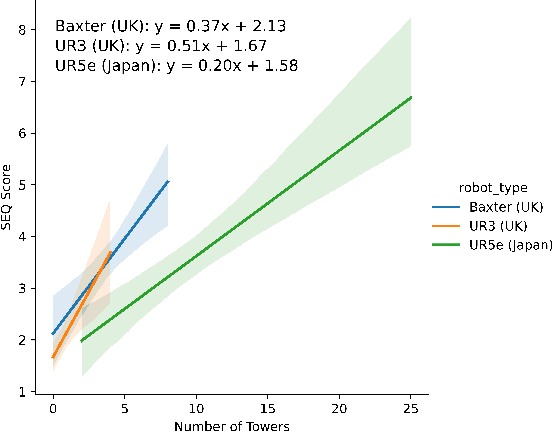
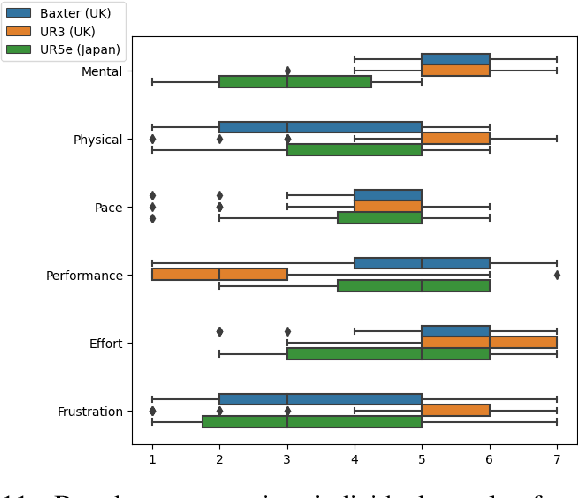
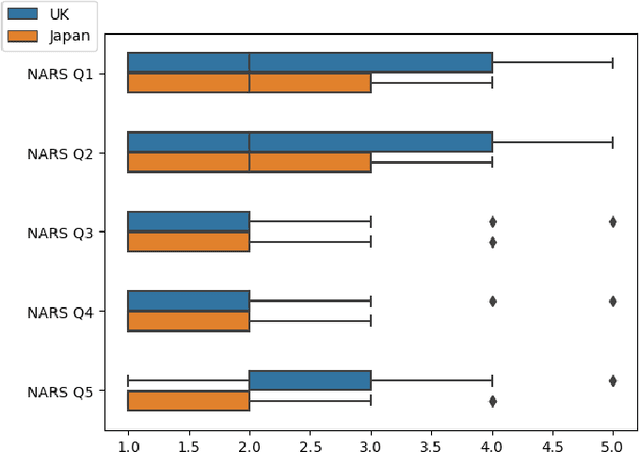
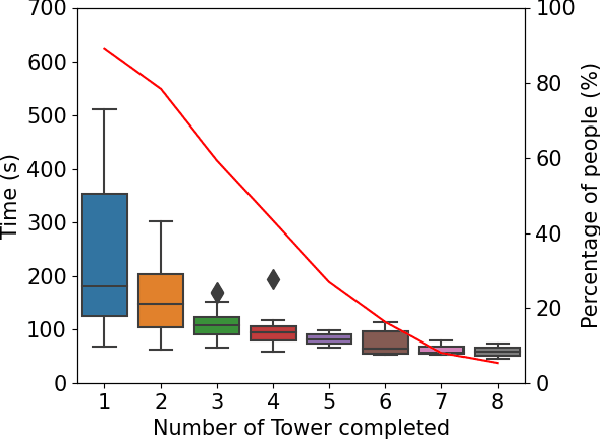
Robots are being created each year with the goal of integrating them into our daily lives. As such, there is an interest in research in evaluating the trust of humans toward robots. In addition, teleoperating robotic arms can be challenging for non-experts. In order to reduce the strain put on the user, we created TELESIM, a modular and plug-and-play framework that enables direct teleoperation of any robotic arm using a digital twin as the interface between users and the robotic system. However, analysis of the strain put on the user and its ability to trust robots was omitted. This paper addresses these omissions by presenting the additional results of our user survey of 37 participants carried out in UK. In addition, we present the results of an additional user survey, under similar conditions performed in Japan, with the goal of addressing the limitations of our previous approach, by interfacing a VR controller with a UR5e. Our experimental results show that the UR5e has a higher number of towers built. Additionally, the UR5e gives the least amount of cognitive stress, while the combination of Senseglove and UR3 gives the user the highest physical strain and causes the user to feel more frustrated. Finally, Japanese seems more trusting towards robots than British.
Flat'n'Fold: A Diverse Multi-Modal Dataset for Garment Perception and Manipulation
Sep 26, 2024



We present Flat'n'Fold, a novel large-scale dataset for garment manipulation that addresses critical gaps in existing datasets. Comprising 1,212 human and 887 robot demonstrations of flattening and folding 44 unique garments across 8 categories, Flat'n'Fold surpasses prior datasets in size, scope, and diversity. Our dataset uniquely captures the entire manipulation process from crumpled to folded states, providing synchronized multi-view RGB-D images, point clouds, and action data, including hand or gripper positions and rotations. We quantify the dataset's diversity and complexity compared to existing benchmarks and show that our dataset features natural and diverse manipulations of real-world demonstrations of human and robot demonstrations in terms of visual and action information. To showcase Flat'n'Fold's utility, we establish new benchmarks for grasping point prediction and subtask decomposition. Our evaluation of state-of-the-art models on these tasks reveals significant room for improvement. This underscores Flat'n'Fold's potential to drive advances in robotic perception and manipulation of deformable objects. Our dataset can be downloaded at https://cvas-ug.github.io/flat-n-fold
IMMERTWIN: A Mixed Reality Framework for Enhanced Robotic Arm Teleoperation
Sep 13, 2024
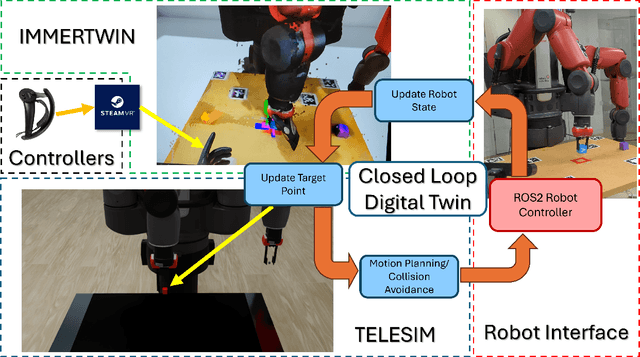
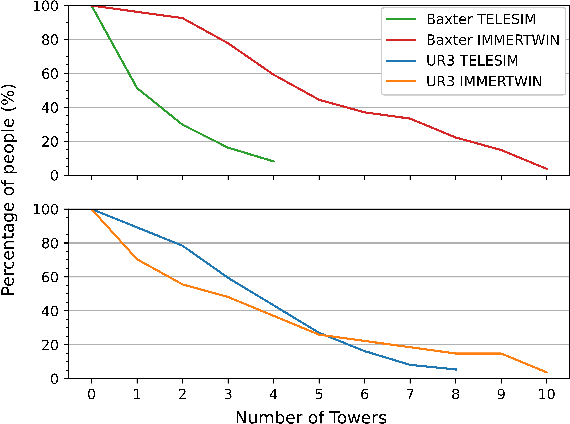
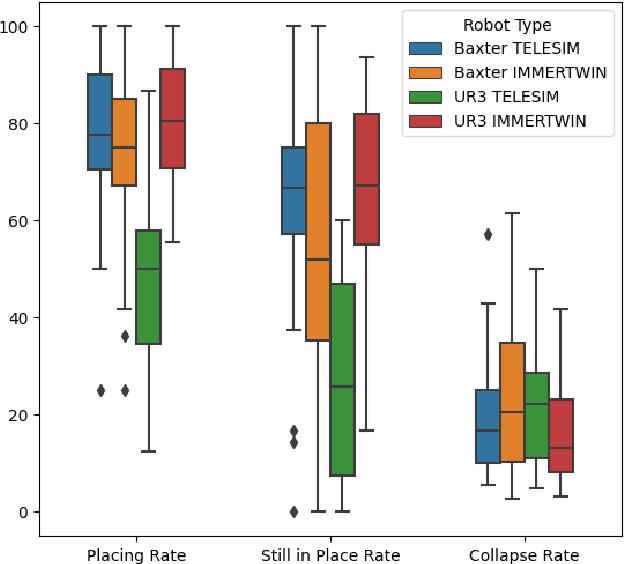
We present IMMERTWIN, a mixed reality framework for enhance robotic arm teleoperation using a closed-loop digital twin as a bridge for interaction between the user and the robotic system. We evaluated IMMERTWIN by performing a medium-scale user survey with 26 participants on two robots. Users were asked to teleoperate with both robots inside the virtual environment to pick and place 3 cubes in a tower and to repeat this task as many times as possible in 10 minutes, with only 5 minutes of training beforehand. Our experimental results show that most users were able to succeed by building at least a tower of 3 cubes regardless of the robot used and a maximum of 10 towers (1 tower per minute). In addition, users preferred to use IMMERTWIN over our previous work, TELESIM, as it caused them less mental workload. The project website and source code can be found at: https://cvas-ug.github.io/immertwin
CLCE: An Approach to Refining Cross-Entropy and Contrastive Learning for Optimized Learning Fusion
Feb 22, 2024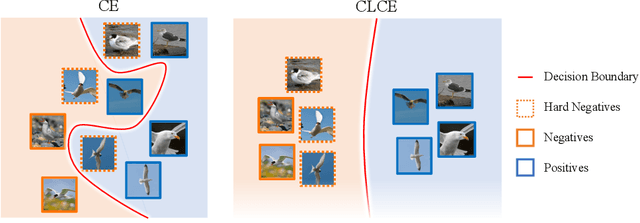
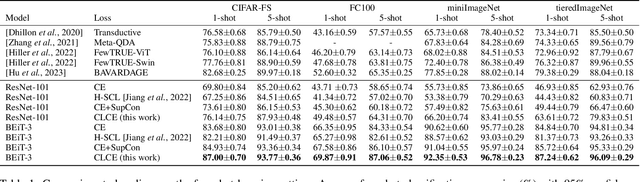
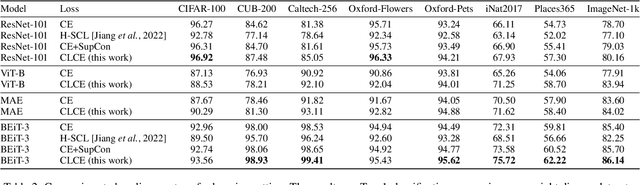
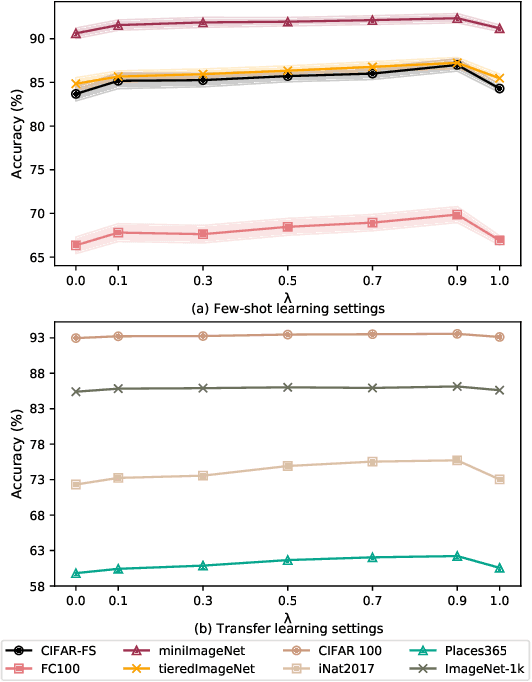
State-of-the-art pre-trained image models predominantly adopt a two-stage approach: initial unsupervised pre-training on large-scale datasets followed by task-specific fine-tuning using Cross-Entropy loss~(CE). However, it has been demonstrated that CE can compromise model generalization and stability. While recent works employing contrastive learning address some of these limitations by enhancing the quality of embeddings and producing better decision boundaries, they often overlook the importance of hard negative mining and rely on resource intensive and slow training using large sample batches. To counter these issues, we introduce a novel approach named CLCE, which integrates Label-Aware Contrastive Learning with CE. Our approach not only maintains the strengths of both loss functions but also leverages hard negative mining in a synergistic way to enhance performance. Experimental results demonstrate that CLCE significantly outperforms CE in Top-1 accuracy across twelve benchmarks, achieving gains of up to 3.52% in few-shot learning scenarios and 3.41% in transfer learning settings with the BEiT-3 model. Importantly, our proposed CLCE approach effectively mitigates the dependency of contrastive learning on large batch sizes such as 4096 samples per batch, a limitation that has previously constrained the application of contrastive learning in budget-limited hardware environments.
Foveation in the Era of Deep Learning
Dec 03, 2023



In this paper, we tackle the challenge of actively attending to visual scenes using a foveated sensor. We introduce an end-to-end differentiable foveated active vision architecture that leverages a graph convolutional network to process foveated images, and a simple yet effective formulation for foveated image sampling. Our model learns to iteratively attend to regions of the image relevant for classification. We conduct detailed experiments on a variety of image datasets, comparing the performance of our method with previous approaches to foveated vision while measuring how the impact of different choices, such as the degree of foveation, and the number of fixations the network performs, affect object recognition performance. We find that our model outperforms a state-of-the-art CNN and foveated vision architectures of comparable parameters and a given pixel or computation budget
TELESIM: A Modular and Plug-and-Play Framework for Robotic Arm Teleoperation using a Digital Twin
Sep 20, 2023

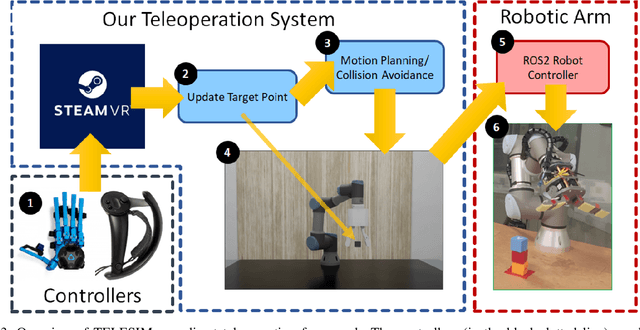
We present TELESIM, a modular and plug-and-play framework for direct teleoperation of a robotic arm using a digital twin as the interface between the user and the robotic system. We tested TELESIM by performing a user survey with 37 participants on two different robots using two different control modalities: a virtual reality controller and a finger mapping hardware controller using different grasping systems. Users were asked to teleoperate the robot to pick and place 3 cubes in a tower and to repeat this task as many times as possible in 10 minutes, with only 5 minutes of training beforehand. Our experimental results show that most users were able to succeed by building at least a tower of 3 cubes regardless of the control modality or robot used, demonstrating the user-friendliness of TELESIM.