 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Instant Policy: Leveraging Student's t-Regression Model for Robust In-context Imitation Learning of Robot Manipulation
Jun 18, 2025Imitation learning (IL) aims to enable robots to perform tasks autonomously by observing a few human demonstrations. Recently, a variant of IL, called In-Context IL, utilized off-the-shelf large language models (LLMs) as instant policies that understand the context from a few given demonstrations to perform a new task, rather than explicitly updating network models with large-scale demonstrations. However, its reliability in the robotics domain is undermined by hallucination issues such as LLM-based instant policy, which occasionally generates poor trajectories that deviate from the given demonstrations. To alleviate this problem, we propose a new robust in-context imitation learning algorithm called the robust instant policy (RIP), which utilizes a Student's t-regression model to be robust against the hallucinated trajectories of instant policies to allow reliable trajectory generation. Specifically, RIP generates several candidate robot trajectories to complete a given task from an LLM and aggregates them using the Student's t-distribution, which is beneficial for ignoring outliers (i.e., hallucinations); thereby, a robust trajectory against hallucinations is generated. Our experiments, conducted in both simulated and real-world environments, show that RIP significantly outperforms state-of-the-art IL methods, with at least $26\%$ improvement in task success rates, particularly in low-data scenarios for everyday tasks. Video results available at https://sites.google.com/view/robustinstantpolicy.
IMMERTWIN: A Mixed Reality Framework for Enhanced Robotic Arm Teleoperation
Sep 13, 2024
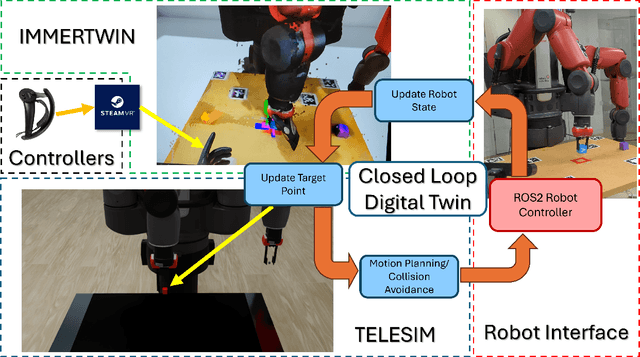
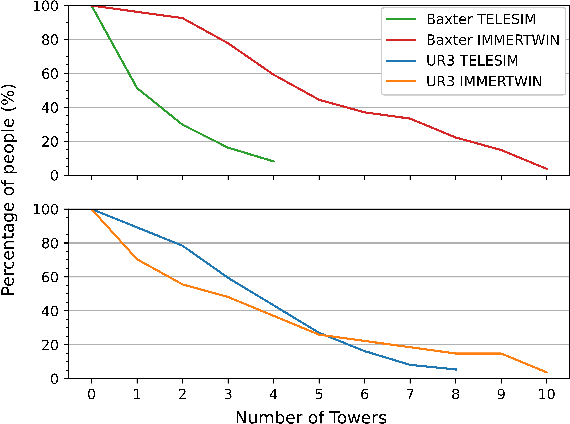
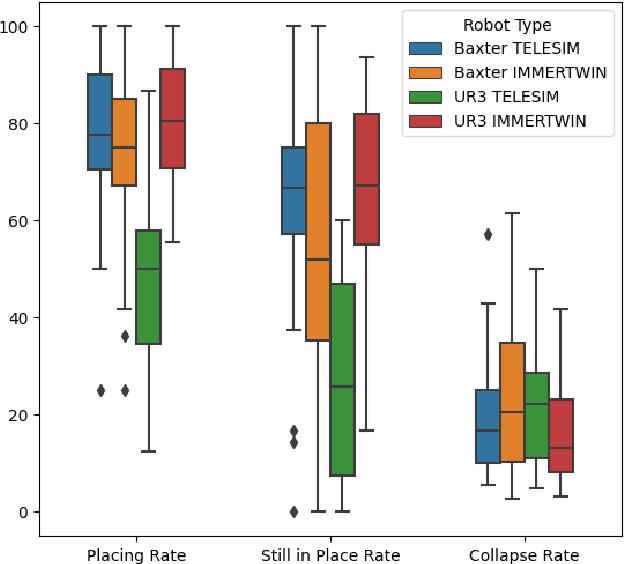
We present IMMERTWIN, a mixed reality framework for enhance robotic arm teleoperation using a closed-loop digital twin as a bridge for interaction between the user and the robotic system. We evaluated IMMERTWIN by performing a medium-scale user survey with 26 participants on two robots. Users were asked to teleoperate with both robots inside the virtual environment to pick and place 3 cubes in a tower and to repeat this task as many times as possible in 10 minutes, with only 5 minutes of training beforehand. Our experimental results show that most users were able to succeed by building at least a tower of 3 cubes regardless of the robot used and a maximum of 10 towers (1 tower per minute). In addition, users preferred to use IMMERTWIN over our previous work, TELESIM, as it caused them less mental workload. The project website and source code can be found at: https://cvas-ug.github.io/immertwin
Tactile-based Active Inference for Force-Controlled Peg-in-Hole Insertions
Sep 27, 2023



Reinforcement Learning (RL) has shown great promise for efficiently learning force control policies in peg-in-hole tasks. However, robots often face difficulties due to visual occlusions by the gripper and uncertainties in the initial grasping pose of the peg. These challenges often restrict force-controlled insertion policies to situations where the peg is rigidly fixed to the end-effector. While vision-based tactile sensors offer rich tactile feedback that could potentially address these issues, utilizing them to learn effective tactile policies is both computationally intensive and difficult to generalize. In this paper, we propose a robust tactile insertion policy that can align the tilted peg with the hole using active inference, without the need for extensive training on large datasets. Our approach employs a dual-policy architecture: one policy focuses on insertion, integrating force control and RL to guide the object into the hole, while the other policy performs active inference based on tactile feedback to align the tilted peg with the hole. In real-world experiments, our dual-policy architecture achieved 90% success rate into a hole with a clearance of less than 0.1 mm, significantly outperforming previous methods that lack tactile sensory feedback (5%). To assess the generalizability of our alignment policy, we conducted experiments with five different pegs, demonstrating its effective adaptation to multiple objects.
Force Map: Learning to Predict Contact Force Distribution from Vision
Apr 12, 2023



When humans see a scene, they can roughly imagine the forces applied to objects based on their experience and use them to handle the objects properly. This paper considers transferring this "force-visualization" ability to robots. We hypothesize that a rough force distribution (named "force map") can be utilized for object manipulation strategies even if accurate force estimation is impossible. Based on this hypothesis, we propose a training method to predict the force map from vision. To investigate this hypothesis, we generated scenes where objects were stacked in bulk through simulation and trained a model to predict the contact force from a single image. We further applied domain randomization to make the trained model function on real images. The experimental results showed that the model trained using only synthetic images could predict approximate patterns representing the contact areas of the objects even for real images. Then, we designed a simple algorithm to plan a lifting direction using the predicted force distribution. We confirmed that using the predicted force distribution contributes to finding natural lifting directions for typical real-world scenes. Furthermore, the evaluation through simulations showed that the disturbance caused to surrounding objects was reduced by 26 % (translation displacement) and by 39 % (angular displacement) for scenes where objects were overlapping.
Accelerating Robot Learning of Contact-Rich Manipulations: A Curriculum Learning Study
Apr 28, 2022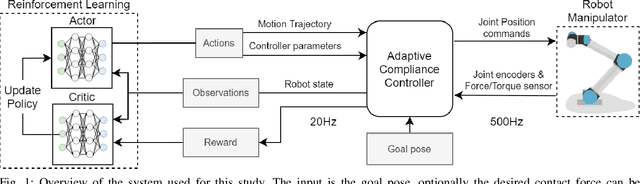
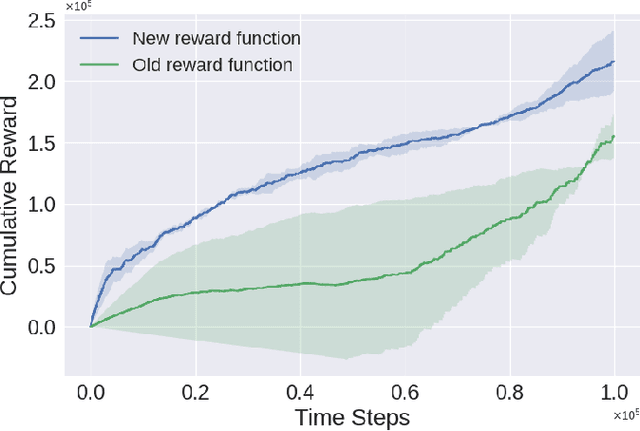
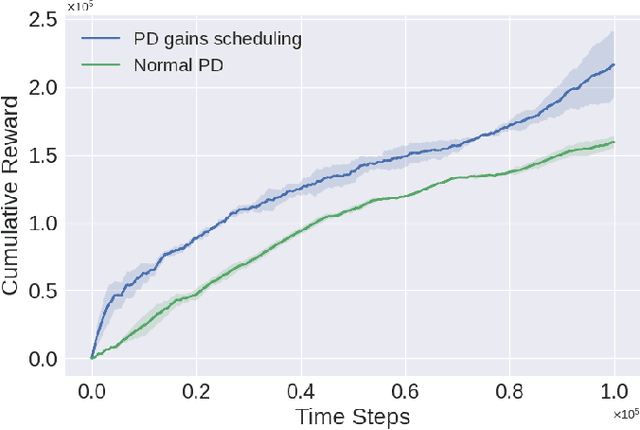
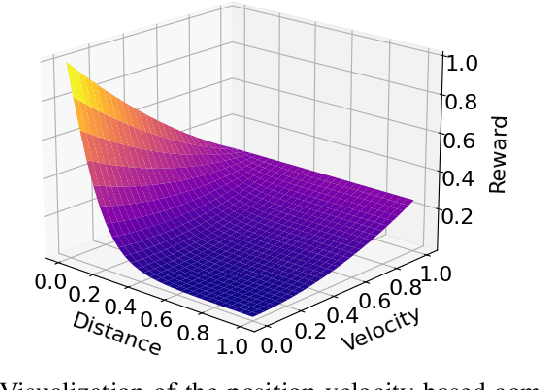
The Reinforcement Learning (RL) paradigm has been an essential tool for automating robotic tasks. Despite the advances in RL, it is still not widely adopted in the industry due to the need for an expensive large amount of robot interaction with its environment. Curriculum Learning (CL) has been proposed to expedite learning. However, most research works have been only evaluated in simulated environments, from video games to robotic toy tasks. This paper presents a study for accelerating robot learning of contact-rich manipulation tasks based on Curriculum Learning combined with Domain Randomization (DR). We tackle complex industrial assembly tasks with position-controlled robots, such as insertion tasks. We compare different curricula designs and sampling approaches for DR. Based on this study, we propose a method that significantly outperforms previous work, which uses DR only (No CL is used), with less than a fifth of the training time (samples). Results also show that even when training only in simulation with toy tasks, our method can learn policies that can be transferred to the real-world robot. The learned policies achieved success rates of up to 86\% on real-world complex industrial insertion tasks (with tolerances of $\pm 0.01~mm$) not seen during the training.
Assembly Planning by Recognizing a Graphical Instruction Manual
Jun 01, 2021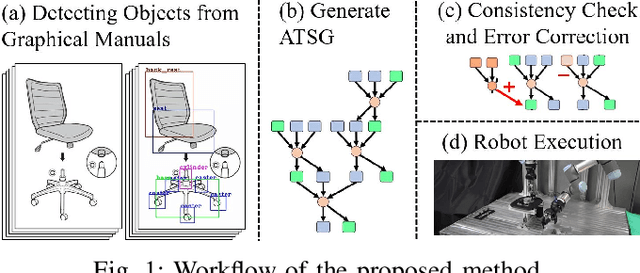
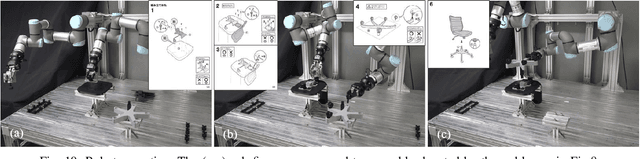
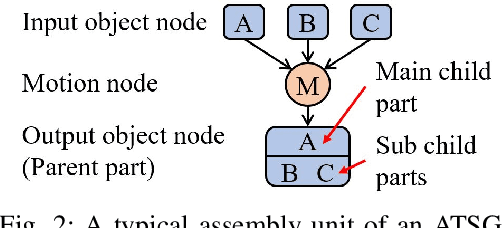

This paper proposes a robot assembly planning method by automatically reading the graphical instruction manuals design for humans. Essentially, the method generates an Assembly Task Sequence Graph (ATSG) by recognizing a graphical instruction manual. An ATSG is a graph describing the assembly task procedure by detecting types of parts included in the instruction images, completing the missing information automatically, and correcting the detection errors automatically. To build an ATSG, the proposed method first extracts the information of the parts contained in each image of the graphical instruction manual. Then, by using the extracted part information, it estimates the proper work motions and tools for the assembly task. After that, the method builds an ATSG by considering the relationship between the previous and following images, which makes it possible to estimate the undetected parts caused by occlusion using the information of the entire image series. Finally, by collating the total number of each part with the generated ATSG, the excess or deficiency of parts are investigated, and task procedures are removed or added according to those parts. In the experiment section, we build an ATSG using the proposed method to a graphical instruction manual for a chair and demonstrate the action sequences found in the ATSG can be performed by a dual-arm robot execution. The results show the proposed method is effective and simplifies robot teaching in automatic assembly.
Variable Compliance Control for Robotic Peg-in-Hole Assembly: A Deep Reinforcement Learning Approach
Sep 25, 2020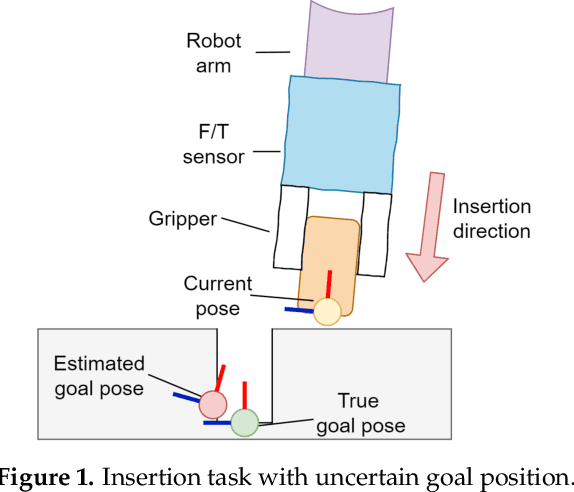
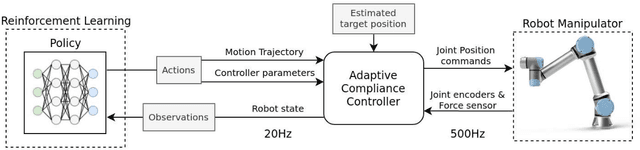

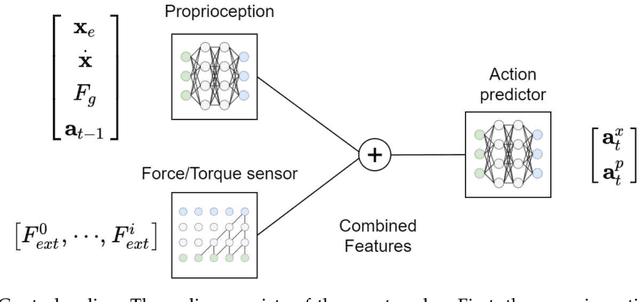
Industrial robot manipulators are playing a more significant role in modern manufacturing industries. Though peg-in-hole assembly is a common industrial task which has been extensively researched, safely solving complex high precision assembly in an unstructured environment remains an open problem. Reinforcement Learning (RL) methods have been proven successful in solving manipulation tasks autonomously. However, RL is still not widely adopted on real robotic systems because working with real hardware entails additional challenges, especially when using position-controlled manipulators. The main contribution of this work is a learning-based method to solve peg-in-hole tasks with position uncertainty of the hole. We proposed the use of an off-policy model-free reinforcement learning method and bootstrap the training speed by using several transfer learning techniques (sim2real) and domain randomization. Our proposed learning framework for position-controlled robots was extensively evaluated on contact-rich insertion tasks on a variety of environments.
Team O2AS at the World Robot Summit 2018: An Approach to Robotic Kitting and Assembly Tasks using General Purpose Grippers and Tools
Mar 05, 2020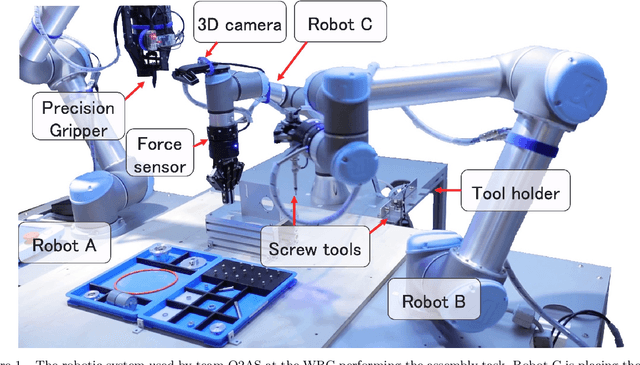
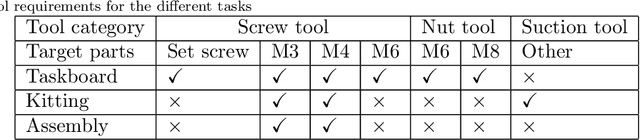
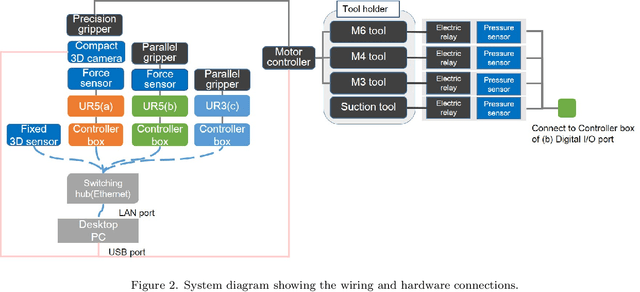

We propose a versatile robotic system for kitting and assembly tasks which uses no jigs or commercial tool changers. Instead of specialized end effectors, it uses its two-finger grippers to grasp and hold tools to perform subtasks such as screwing and suctioning. A third gripper is used as a precision picking and centering tool, and uses in-built passive compliance to compensate for small position errors and uncertainty. A novel grasp point detection for bin picking is described for the kitting task, using a single depth map. Using the proposed system we competed in the Assembly Challenge of the Industrial Robotics Category of the World Robot Challenge at the World Robot Summit 2018, obtaining 4th place and the SICE award for lean design and versatile tool use. We show the effectiveness of our approach through experiments performed during the competition.
Learning Contact-Rich Manipulation Tasks with Rigid Position-Controlled Robots: Learning to Force Control
Mar 02, 2020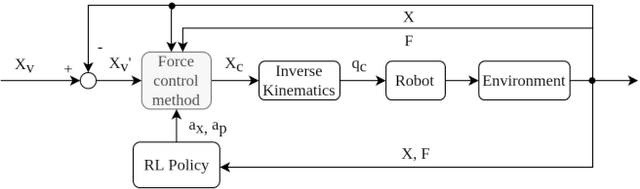
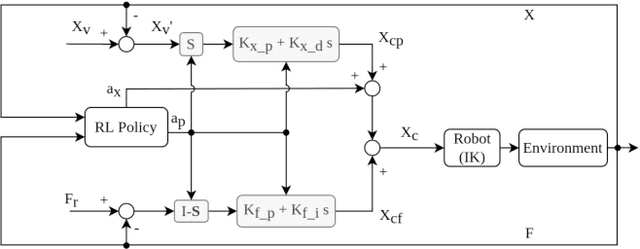
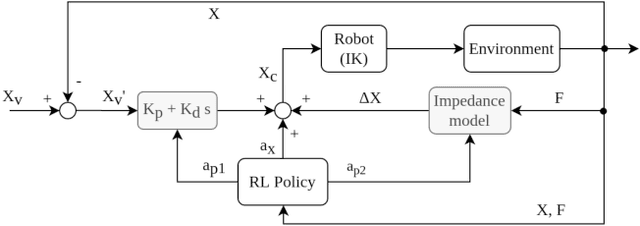
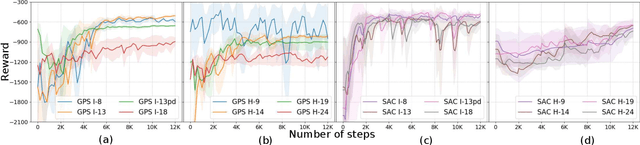
To fully realize industrial automation, it is indispensable to give the robot manipulators the ability to adapt by themselves to their surroundings and to learn to handle novel manipulation tasks. Reinforcement Learning (RL) methods have been proven successful in solving manipulation tasks autonomously. However, RL is still not widely adopted on real robotic systems because working with real hardware entails additional challenges, especially when using rigid position-controlled manipulators. These challenges include the need for a robust controller to avoid undesired behavior, that risk damaging the robot and its environment, and constant supervision from a human operator. The main contributions of this work are, first, we propose a framework for safely training an RL agent on manipulation tasks using a rigid robot. Second, to enable a position-controlled manipulator to perform contact-rich manipulation tasks, we implemented two different force control schemes based on standard force feedback controllers; one is a modified hybrid position-force control, and the other one is an impedance control. Third, we empirically study both control schemes when used as the action representation of an RL agent. We evaluate the trade-off between control complexity and performance by comparing several versions of the control schemes, each with a different number of force control parameters. The proposed methods are validated both on simulation and a real robot, a UR3 e-series robotic arm when executing contact-rich manipulation tasks.
Tool Exchangeable Grasp/Assembly Planner
May 23, 2018
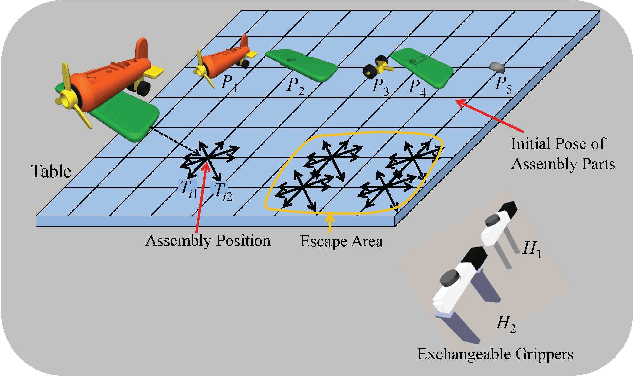
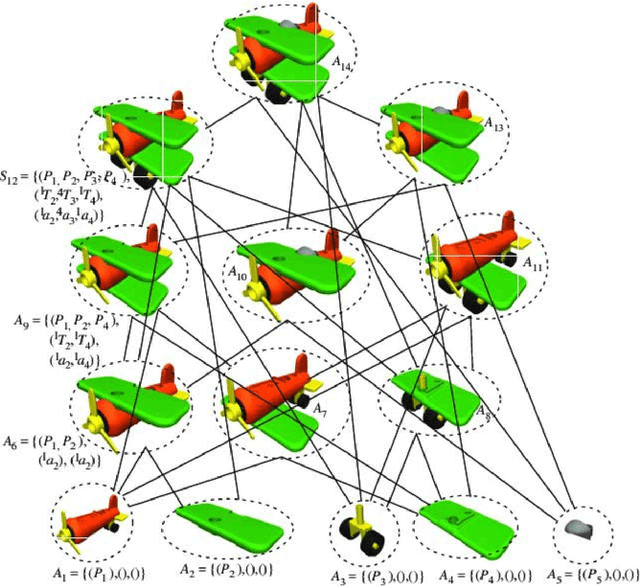
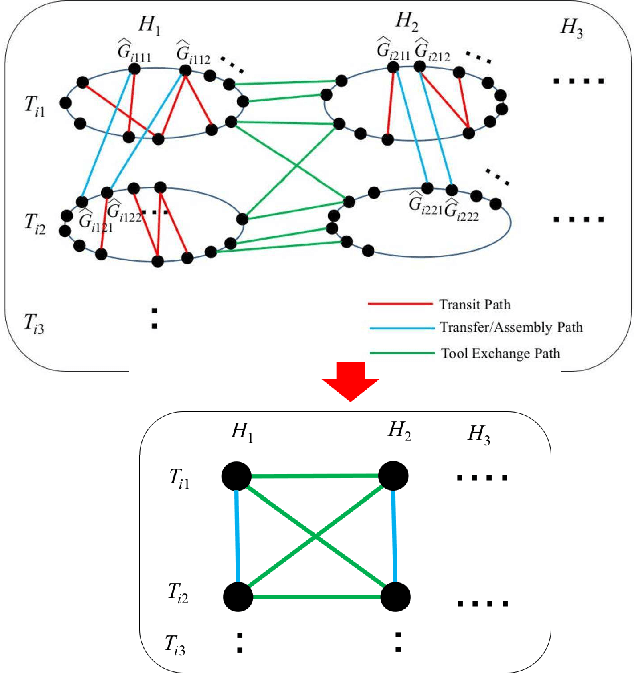
This paper proposes a novel assembly planner for a manipulator which can simultaneously plan assembly sequence, robot motion, grasping configuration, and exchange of grippers. Our assembly planner assumes multiple grippers and can automatically selects a feasible one to assemble a part. For a given AND/OR graph of an assembly task, we consider generating the assembly graph from which assembly motion of a robot can be planned. The edges of the assembly graph are composed of three kinds of paths, i.e., transfer/assembly paths, transit paths and tool exchange paths. In this paper, we first explain the proposed method for planning assembly motion sequence including the function of gripper exchange. Finally, the effectiveness of the proposed method is confirmed through some numerical examples and a physical experiment.
* This is to appear Int. Conf. on Intelligent Autonomous Systems