 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDIF: Formula-Driven supervised Learning with Implicit Functions for 3D Medical Image Segmentation
Mar 24, 2026Deep learning-based 3D medical image segmentation methods relies on large-scale labeled datasets, yet acquiring such data is difficult due to privacy constraints and the high cost of expert annotation. Formula-Driven Supervised Learning (FDSL) offers an appealing alternative by generating training data and labels directly from mathematical formulas. However, existing voxel-based approaches are limited in geometric expressiveness and cannot synthesize realistic textures. We introduce Formula-Driven supervised learning with Implicit Functions (FDIF), a framework that enables scalable pre-training without using any real data and medical expert annotations. FDIF introduces an implicit-function representation based on signed distance functions (SDFs), enabling compact modeling of complex geometries while exploiting the surface representation of SDFs to support controllable synthesis of both geometric and intensity textures. Across three medical image segmentation benchmarks (AMOS, ACDC, and KiTS) and three architectures (SwinUNETR, nnUNet ResEnc-L, and nnUNet Primus-M), FDIF consistently improves over a formula-driven method, and achieves performance comparable to self-supervised approaches pre-trained on large-scale real datasets. We further show that FDIF pre-training also benefits 3D classification tasks, highlighting implicit-function-based formula supervision as a promising paradigm for data-free representation learning. Code is available at https://github.com/yamanoko/FDIF.
From Dialogue to Execution: Mixture-of-Agents Assisted Interactive Planning for Behavior Tree-Based Long-Horizon Robot Execution
Mar 01, 2026Interactive task planning with large language models (LLMs) enables robots to generate high-level action plans from natural language instructions. However, in long-horizon tasks, such approaches often require many questions, increasing user burden. Moreover, flat plan representations become difficult to manage as task complexity grows. We propose a framework that integrates Mixture-of-Agents (MoA)-based proxy answering into interactive planning and generates Behavior Trees (BTs) for structured long-term execution. The MoA consists of multiple LLM-based expert agents that answer general or domain-specific questions when possible, reducing unnecessary human intervention. The resulting BT hierarchically represents task logic and enables retry mechanisms and dynamic switching among multiple robot policies. Experiments on cocktail-making tasks show that the proposed method reduces human response requirements by approximately 27% while maintaining structural and semantic similarity to fully human-answered BTs. Real-robot experiments on a smoothie-making task further demonstrate successful long-horizon execution with adaptive policy switching and recovery from action failures. These results indicate that MoA-assisted interactive planning improves dialogue efficiency while preserving execution quality in real-world robotic tasks.
Compact Task-Aligned Imitation Learning for Laboratory Automation
Mar 01, 2026Robotic laboratory automation has traditionally relied on carefully engineered motion pipelines and task-specific hardware interfaces, resulting in high design cost and limited flexibility. While recent imitation learning techniques can generate general robot behaviors, their large model sizes often require high-performance computational resources, limiting applicability in practical laboratory environments. In this study, we propose a compact imitation learning framework for laboratory automation using small foundation models. The proposed method, TVF-DiT, aligns a self-supervised vision foundation model with a vision-language model through a compact adapter, and integrates them with a Diffusion Transformer-based action expert. The entire model consists of fewer than 500M parameters, enabling inference on low-VRAM GPUs. Experiments on three real-world laboratory tasks - test tube cleaning, test tube arrangement, and powder transfer - demonstrate an average success rate of 86.6%, significantly outperforming alternative lightweight baselines. Furthermore, detailed task prompts improve vision-language alignment and task performance. These results indicate that small foundation models, when properly aligned and integrated with diffusion-based policy learning, can effectively support practical laboratory automation with limited computational resources.
TaSA: Two-Phased Deep Predictive Learning of Tactile Sensory Attenuation for Improving In-Grasp Manipulation
Feb 05, 2026Humans can achieve diverse in-hand manipulations, such as object pinching and tool use, which often involve simultaneous contact between the object and multiple fingers. This is still an open issue for robotic hands because such dexterous manipulation requires distinguishing between tactile sensations generated by their self-contact and those arising from external contact. Otherwise, object/robot breakage happens due to contacts/collisions. Indeed, most approaches ignore self-contact altogether, by constraining motion to avoid/ignore self-tactile information during contact. While this reduces complexity, it also limits generalization to real-world scenarios where self-contact is inevitable. Humans overcome this challenge through self-touch perception, using predictive mechanisms that anticipate the tactile consequences of their own motion, through a principle called sensory attenuation, where the nervous system differentiates predictable self-touch signals, allowing novel object stimuli to stand out as relevant. Deriving from this, we introduce TaSA, a two-phased deep predictive learning framework. In the first phase, TaSA explicitly learns self-touch dynamics, modeling how a robot's own actions generate tactile feedback. In the second phase, this learned model is incorporated into the motion learning phase, to emphasize object contact signals during manipulation. We evaluate TaSA on a set of insertion tasks, which demand fine tactile discrimination: inserting a pencil lead into a mechanical pencil, inserting coins into a slot, and fixing a paper clip onto a sheet of paper, with various orientations, positions, and sizes. Across all tasks, policies trained with TaSA achieve significantly higher success rates than baseline methods, demonstrating that structured tactile perception with self-touch based on sensory attenuation is critical for dexterous robotic manipulation.
Proprioception Enhances Vision Language Model in Generating Captions and Subtask Segmentations for Robot Task
Dec 24, 2025From the perspective of future developments in robotics, it is crucial to verify whether foundation models trained exclusively on offline data, such as images and language, can understand the robot motion. In particular, since Vision Language Models (VLMs) do not include low-level motion information from robots in their training datasets, video understanding including trajectory information remains a significant challenge. In this study, we assess two capabilities of VLMs through a video captioning task with low-level robot motion information: (1) automatic captioning of robot tasks and (2) segmentation of a series of tasks. Both capabilities are expected to enhance the efficiency of robot imitation learning by linking language and motion and serve as a measure of the foundation model's performance. The proposed method generates multiple "scene" captions using image captions and trajectory data from robot tasks. The full task caption is then generated by summarizing these individual captions. Additionally, the method performs subtask segmentation by comparing the similarity between text embeddings of image captions. In both captioning tasks, the proposed method aims to improve performance by providing the robot's motion data - joint and end-effector states - as input to the VLM. Simulator experiments were conducted to validate the effectiveness of the proposed method.
Input-gated Bilateral Teleoperation: An Easy-to-implement Force Feedback Teleoperation Method for Low-cost Hardware
Sep 10, 2025

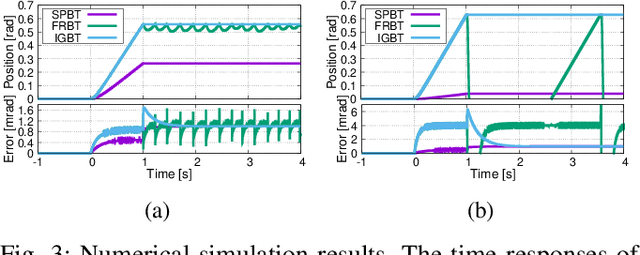

Effective data collection in contact-rich manipulation requires force feedback during teleoperation, as accurate perception of contact is crucial for stable control. However, such technology remains uncommon, largely because bilateral teleoperation systems are complex and difficult to implement. To overcome this, we propose a bilateral teleoperation method that relies only on a simple feedback controller and does not require force sensors. The approach is designed for leader-follower setups using low-cost hardware, making it broadly applicable. Through numerical simulations and real-world experiments, we demonstrate that the method requires minimal parameter tuning, yet achieves both high operability and contact stability, outperforming conventional approaches. Furthermore, we show its high robustness: even at low communication cycle rates between leader and follower, control performance degradation is minimal compared to high-speed operation. We also prove our method can be implemented on two types of commercially available low-cost hardware with zero parameter adjustments. This highlights its high ease of implementation and versatility. We expect this method will expand the use of force feedback teleoperation systems on low-cost hardware. This will contribute to advancing contact-rich task autonomy in imitation learning.
Close-Fitting Dressing Assistance Based on State Estimation of Feet and Garments with Semantic-based Visual Attention
May 06, 2025As the population continues to age, a shortage of caregivers is expected in the future. Dressing assistance, in particular, is crucial for opportunities for social participation. Especially dressing close-fitting garments, such as socks, remains challenging due to the need for fine force adjustments to handle the friction or snagging against the skin, while considering the shape and position of the garment. This study introduces a method uses multi-modal information including not only robot's camera images, joint angles, joint torques, but also tactile forces for proper force interaction that can adapt to individual differences in humans. Furthermore, by introducing semantic information based on object concepts, rather than relying solely on RGB data, it can be generalized to unseen feet and background. In addition, incorporating depth data helps infer relative spatial relationship between the sock and the foot. To validate its capability for semantic object conceptualization and to ensure safety, training data were collected using a mannequin, and subsequent experiments were conducted with human subjects. In experiments, the robot successfully adapted to previously unseen human feet and was able to put socks on 10 participants, achieving a higher success rate than Action Chunking with Transformer and Diffusion Policy. These results demonstrate that the proposed model can estimate the state of both the garment and the foot, enabling precise dressing assistance for close-fitting garments.
Focused Blind Switching Manipulation Based on Constrained and Regional Touch States of Multi-Fingered Hand Using Deep Learning
Mar 10, 2025To achieve a desired grasping posture (including object position and orientation), multi-finger motions need to be conducted according to the the current touch state. Specifically, when subtle changes happen during correcting the object state, not only proprioception but also tactile information from the entire hand can be beneficial. However, switching motions with high-DOFs of multiple fingers and abundant tactile information is still challenging. In this study, we propose a loss function with constraints of touch states and an attention mechanism for focusing on important modalities depending on the touch states. The policy model is AE-LSTM which consists of Autoencoder (AE) which compresses abundant tactile information and Long Short-Term Memory (LSTM) which switches the motion depending on the touch states. Motion for cap-opening was chosen as a target task which consists of subtasks of sliding an object and opening its cap. As a result, the proposed method achieved the best success rates with a variety of objects for real time cap-opening manipulation. Furthermore, we could confirm that the proposed model acquired the features of each subtask and attention on specific modalities.
Visual Imitation Learning of Non-Prehensile Manipulation Tasks with Dynamics-Supervised Models
Oct 25, 2024Unlike quasi-static robotic manipulation tasks like pick-and-place, dynamic tasks such as non-prehensile manipulation pose greater challenges, especially for vision-based control. Successful control requires the extraction of features relevant to the target task. In visual imitation learning settings, these features can be learnt by backpropagating the policy loss through the vision backbone. Yet, this approach tends to learn task-specific features with limited generalizability. Alternatively, learning world models can realize more generalizable vision backbones. Utilizing the learnt features, task-specific policies are subsequently trained. Commonly, these models are trained solely to predict the next RGB state from the current state and action taken. But only-RGB prediction might not fully-capture the task-relevant dynamics. In this work, we hypothesize that direct supervision of target dynamic states (Dynamics Mapping) can learn better dynamics-informed world models. Beside the next RGB reconstruction, the world model is also trained to directly predict position, velocity, and acceleration of environment rigid bodies. To verify our hypothesis, we designed a non-prehensile 2D environment tailored to two tasks: "Balance-Reaching" and "Bin-Dropping". When trained on the first task, dynamics mapping enhanced the task performance under different training configurations (Decoupled, Joint, End-to-End) and policy architectures (Feedforward, Recurrent). Notably, its most significant impact was for world model pretraining boosting the success rate from 21% to 85%. Although frozen dynamics-informed world models could generalize well to a task with in-domain dynamics, but poorly to a one with out-of-domain dynamics.
Achieving Faster and More Accurate Operation of Deep Predictive Learning
Aug 03, 2024
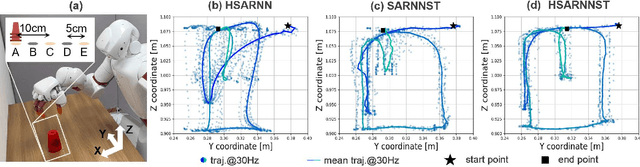
Achieving both high speed and precision in robot operations is a significant challenge for social implementation. While factory robots excel at predefined tasks, they struggle with environment-specific actions like cleaning and cooking. Deep learning research aims to address this by enabling robots to autonomously execute behaviors through end-to-end learning with sensor data. RT-1 and ACT are notable examples that have expanded robots' capabilities. However, issues with model inference speed and hand position accuracy persist. High-quality training data and fast, stable inference mechanisms are essential to overcome these challenges. This paper proposes a motion generation model for high-speed, high-precision tasks, exemplified by the sports stacking task. By teaching motions slowly and inferring at high speeds, the model achieved a 94% success rate in stacking cups with a real robot.