 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput-gated Bilateral Teleoperation: An Easy-to-implement Force Feedback Teleoperation Method for Low-cost Hardware
Sep 10, 2025Effective data collection in contact-rich manipulation requires force feedback during teleoperation, as accurate perception of contact is crucial for stable control. However, such technology remains uncommon, largely because bilateral teleoperation systems are complex and difficult to implement. To overcome this, we propose a bilateral teleoperation method that relies only on a simple feedback controller and does not require force sensors. The approach is designed for leader-follower setups using low-cost hardware, making it broadly applicable. Through numerical simulations and real-world experiments, we demonstrate that the method requires minimal parameter tuning, yet achieves both high operability and contact stability, outperforming conventional approaches. Furthermore, we show its high robustness: even at low communication cycle rates between leader and follower, control performance degradation is minimal compared to high-speed operation. We also prove our method can be implemented on two types of commercially available low-cost hardware with zero parameter adjustments. This highlights its high ease of implementation and versatility. We expect this method will expand the use of force feedback teleoperation systems on low-cost hardware. This will contribute to advancing contact-rich task autonomy in imitation learning.
Adaptive Motion Generation Using Uncertainty-Driven Foresight Prediction
Oct 01, 2024


Uncertainty of environments has long been a difficult characteristic to handle, when performing real-world robot tasks. This is because the uncertainty produces unexpected observations that cannot be covered by manual scripting. Learning based robot controlling methods are a promising approach for generating flexible motions against unknown situations, but still tend to suffer under uncertainty due to its deterministic nature. In order to adaptively perform the target task under such conditions, the robot control model must be able to accurately understand the possible uncertainty, and to exploratively derive the optimal action that minimizes such uncertainty. This paper extended an existing predictive learning based robot control method, which employ foresight prediction using dynamic internal simulation. The foresight module refines the model's hidden states by sampling multiple possible futures and replace with the one that led to the lower future uncertainty. The adaptiveness of the model was evaluated on a door opening task. The door can be opened either by pushing, pulling, or sliding, but robot cannot visually distinguish which way, and is required to adapt on the fly. The results showed that the proposed model adaptively diverged its motion through interaction with the door, whereas conventional methods failed to stably diverge. The models were analyzed on Lyapunov exponents of RNN hidden states which reflect the possible divergence at each time step during task execution. The result indicated that the foresight module biased the model to consider future consequences, which lead to embedding uncertainties at the policy of the robot controller, rather than the resultant observation. This is beneficial for implementing adaptive behaviors, which indices derivation of diverse motion during exploration.
Achieving Faster and More Accurate Operation of Deep Predictive Learning
Aug 03, 2024Achieving both high speed and precision in robot operations is a significant challenge for social implementation. While factory robots excel at predefined tasks, they struggle with environment-specific actions like cleaning and cooking. Deep learning research aims to address this by enabling robots to autonomously execute behaviors through end-to-end learning with sensor data. RT-1 and ACT are notable examples that have expanded robots' capabilities. However, issues with model inference speed and hand position accuracy persist. High-quality training data and fast, stable inference mechanisms are essential to overcome these challenges. This paper proposes a motion generation model for high-speed, high-precision tasks, exemplified by the sports stacking task. By teaching motions slowly and inferring at high speeds, the model achieved a 94% success rate in stacking cups with a real robot.
Visual Spatial Attention and Proprioceptive Data-Driven Reinforcement Learning for Robust Peg-in-Hole Task Under Variable Conditions
Dec 27, 2023Anchor-bolt insertion is a peg-in-hole task performed in the construction field for holes in concrete. Efforts have been made to automate this task, but the variable lighting and hole surface conditions, as well as the requirements for short setup and task execution time make the automation challenging. In this study, we introduce a vision and proprioceptive data-driven robot control model for this task that is robust to challenging lighting and hole surface conditions. This model consists of a spatial attention point network (SAP) and a deep reinforcement learning (DRL) policy that are trained jointly end-to-end to control the robot. The model is trained in an offline manner, with a sample-efficient framework designed to reduce training time and minimize the reality gap when transferring the model to the physical world. Through evaluations with an industrial robot performing the task in 12 unknown holes, starting from 16 different initial positions, and under three different lighting conditions (two with misleading shadows), we demonstrate that SAP can generate relevant attention points of the image even in challenging lighting conditions. We also show that the proposed model enables task execution with higher success rate and shorter task completion time than various baselines. Due to the proposed model's high effectiveness even in severe lighting, initial positions, and hole conditions, and the offline training framework's high sample-efficiency and short training time, this approach can be easily applied to construction.
* Published in IEEE Robotics and Automation Letters in 08 February 2023
Realtime Motion Generation with Active Perception Using Attention Mechanism for Cooking Robot
Sep 26, 2023



To support humans in their daily lives, robots are required to autonomously learn, adapt to objects and environments, and perform the appropriate actions. We tackled on the task of cooking scrambled eggs using real ingredients, in which the robot needs to perceive the states of the egg and adjust stirring movement in real time, while the egg is heated and the state changes continuously. In previous works, handling changing objects was found to be challenging because sensory information includes dynamical, both important or noisy information, and the modality which should be focused on changes every time, making it difficult to realize both perception and motion generation in real time. We propose a predictive recurrent neural network with an attention mechanism that can weigh the sensor input, distinguishing how important and reliable each modality is, that realize quick and efficient perception and motion generation. The model is trained with learning from the demonstration, and allows the robot to acquire human-like skills. We validated the proposed technique using the robot, Dry-AIREC, and with our learning model, it could perform cooking eggs with unknown ingredients. The robot could change the method of stirring and direction depending on the status of the egg, as in the beginning it stirs in the whole pot, then subsequently, after the egg started being heated, it starts flipping and splitting motion targeting specific areas, although we did not explicitly indicate them.
Real-time Motion Generation and Data Augmentation for Grasping Moving Objects with Dynamic Speed and Position Changes
Sep 22, 2023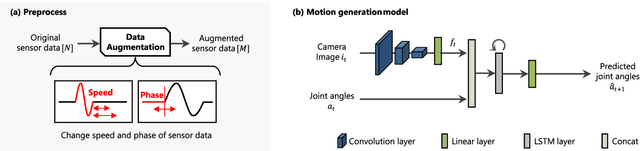
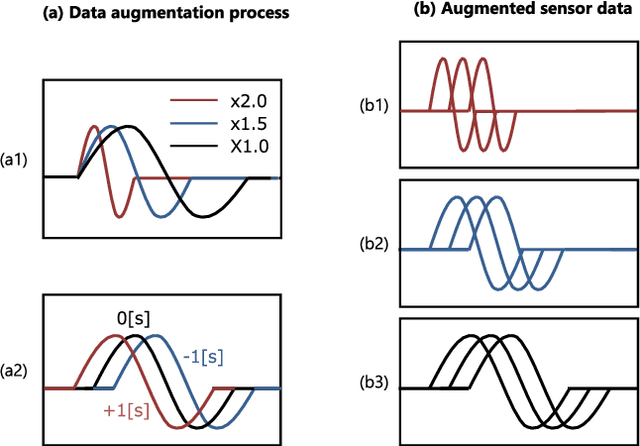

While deep learning enables real robots to perform complex tasks had been difficult to implement in the past, the challenge is the enormous amount of trial-and-error and motion teaching in a real environment. The manipulation of moving objects, due to their dynamic properties, requires learning a wide range of factors such as the object's position, movement speed, and grasping timing. We propose a data augmentation method for enabling a robot to grasp moving objects with different speeds and grasping timings at low cost. Specifically, the robot is taught to grasp an object moving at low speed using teleoperation, and multiple data with different speeds and grasping timings are generated by down-sampling and padding the robot sensor data in the time-series direction. By learning multiple sensor data in a time series, the robot can generate motions while adjusting the grasping timing for unlearned movement speeds and sudden speed changes. We have shown using a real robot that this data augmentation method facilitates learning the relationship between object position and velocity and enables the robot to perform robust grasping motions for unlearned positions and objects with dynamically changing positions and velocities.
Deep Predictive Learning : Motion Learning Concept inspired by Cognitive Robotics
Jun 26, 2023



A deep learning-based approach can generalize model performance while reducing feature design costs by learning end-to-end environment recognition and motion generation. However, the process incurs huge training data collection costs and time and human resources for trial-and-error when involving physical contact with robots. Therefore, we propose ``deep predictive learning,'' a motion learning concept that assumes imperfections in the predictive model and minimizes the prediction error with the real-world situation. Deep predictive learning is inspired by the ``free energy principle and predictive coding theory,'' which explains how living organisms behave to minimize the prediction error between the real world and the brain. Robots predict near-future situations based on sensorimotor information and generate motions that minimize the gap with reality. The robot can flexibly perform tasks in unlearned situations by adjusting its motion in real-time while considering the gap between learning and reality. This paper describes the concept of deep predictive learning, its implementation, and examples of its application to real robots. The code and document are available at https: //ogata-lab.github.io/eipl-docs
Deep Active Visual Attention for Real-time Robot Motion Generation: Emergence of Tool-body Assimilation and Adaptive Tool-use
Jun 29, 2022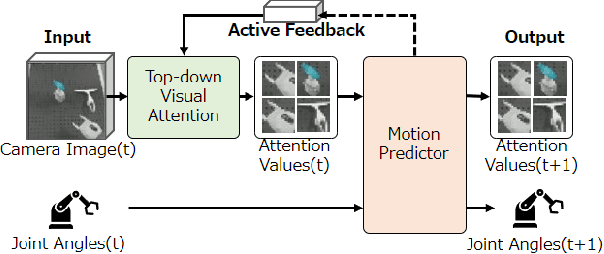

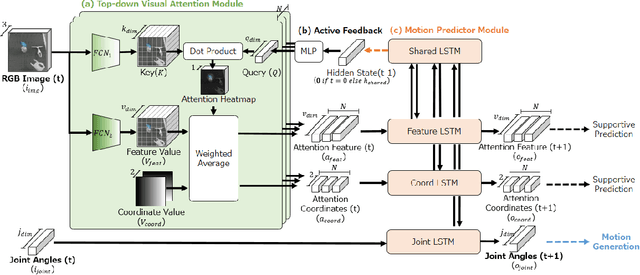
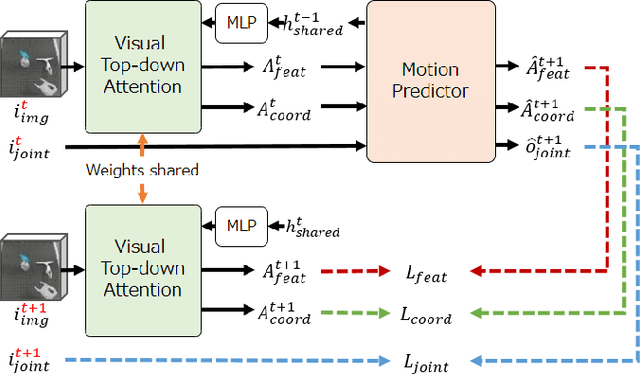
Sufficiently perceiving the environment is a critical factor in robot motion generation. Although the introduction of deep visual processing models have contributed in extending this ability, existing methods lack in the ability to actively modify what to perceive; humans perform internally during visual cognitive processes. This paper addresses the issue by proposing a novel robot motion generation model, inspired by a human cognitive structure. The model incorporates a state-driven active top-down visual attention module, which acquires attentions that can actively change targets based on task states. We term such attentions as role-based attentions, since the acquired attention directed to targets that shared a coherent role throughout the motion. The model was trained on a robot tool-use task, in which the role-based attentions perceived the robot grippers and tool as identical end-effectors, during object picking and object dragging motions respectively. This is analogous to a biological phenomenon called tool-body assimilation, in which one regards a handled tool as an extension of one's body. The results suggested an improvement of flexibility in model's visual perception, which sustained stable attention and motion even if it was provided with untrained tools or exposed to experimenter's distractions.
Contact-Rich Manipulation of a Flexible Object based on Deep Predictive Learning using Vision and Tactility
Dec 13, 2021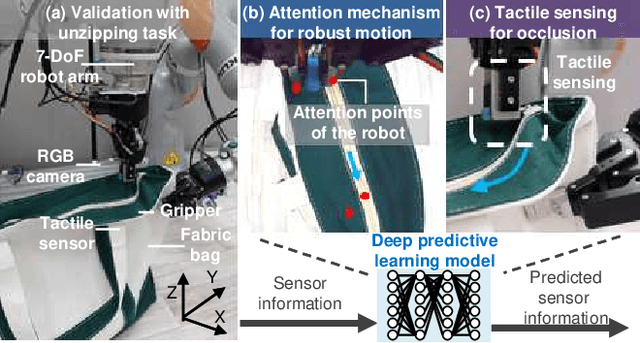
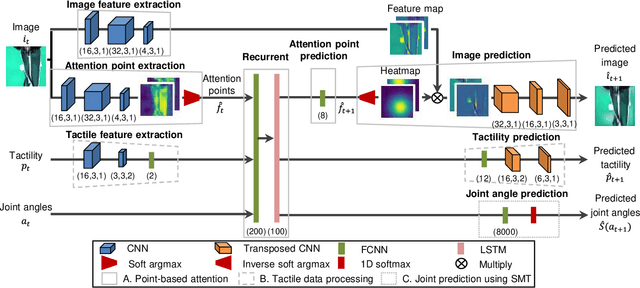

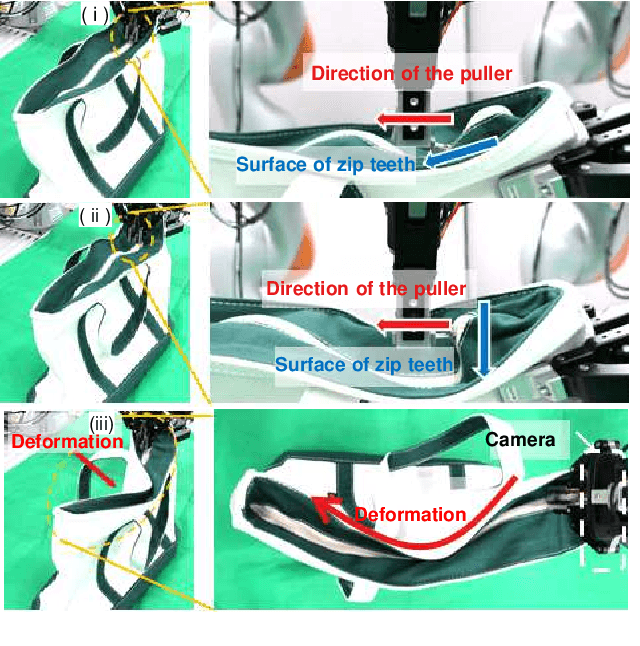
We achieved contact-rich flexible object manipulation, which was difficult to control with vision alone. In the unzipping task we chose as a validation task, the gripper grasps the puller, which hides the bag state such as the direction and amount of deformation behind it, making it difficult to obtain information to perform the task by vision alone. Additionally, the flexible fabric bag state constantly changes during operation, so the robot needs to dynamically respond to the change. However, the appropriate robot behavior for all bag states is difficult to prepare in advance. To solve this problem, we developed a model that can perform contact-rich flexible object manipulation by real-time prediction of vision with tactility. We introduced a point-based attention mechanism for extracting image features, softmax transformation for predicting motions, and convolutional neural network for extracting tactile features. The results of experiments using a real robot arm revealed that our method can realize motions responding to the deformation of the bag while reducing the load on the zipper. Furthermore, using tactility improved the success rate from 56.7% to 93.3% compared with vision alone, demonstrating the effectiveness and high performance of our method.
Spatial Attention Point Network for Deep-learning-based Robust Autonomous Robot Motion Generation
Mar 02, 2021
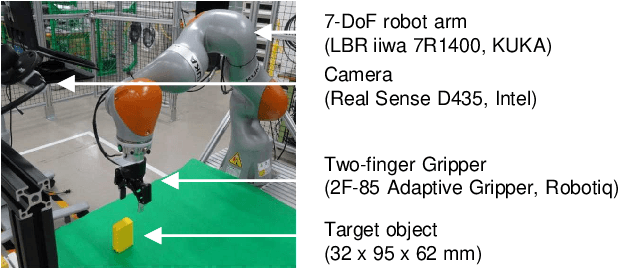
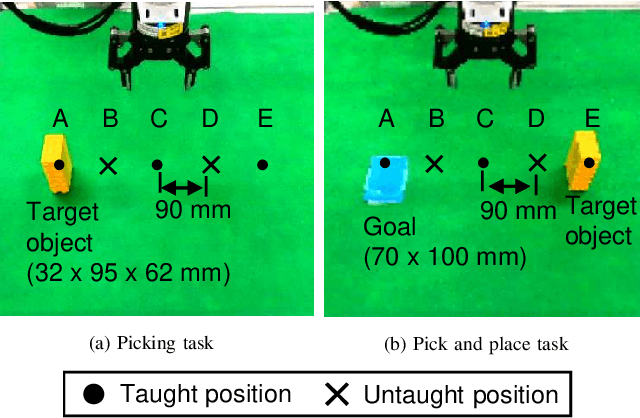

Deep learning provides a powerful framework for automated acquisition of complex robotic motions. However, despite a certain degree of generalization, the need for vast amounts of training data depending on the work-object position is an obstacle to industrial applications. Therefore, a robot motion-generation model that can respond to a variety of work-object positions with a small amount of training data is necessary. In this paper, we propose a method robust to changes in object position by automatically extracting spatial attention points in the image for the robot task and generating motions on the basis of their positions. We demonstrate our method with an LBR iiwa 7R1400 robot arm on a picking task and a pick-and-place task at various positions in various situations. In each task, the spatial attention points are obtained for the work objects that are important to the task. Our method is robust to changes in object position. Further, it is robust to changes in background, lighting, and obstacles that are not important to the task because it only focuses on positions that are important to the task.