 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInput-gated Bilateral Teleoperation: An Easy-to-implement Force Feedback Teleoperation Method for Low-cost Hardware
Sep 10, 2025Effective data collection in contact-rich manipulation requires force feedback during teleoperation, as accurate perception of contact is crucial for stable control. However, such technology remains uncommon, largely because bilateral teleoperation systems are complex and difficult to implement. To overcome this, we propose a bilateral teleoperation method that relies only on a simple feedback controller and does not require force sensors. The approach is designed for leader-follower setups using low-cost hardware, making it broadly applicable. Through numerical simulations and real-world experiments, we demonstrate that the method requires minimal parameter tuning, yet achieves both high operability and contact stability, outperforming conventional approaches. Furthermore, we show its high robustness: even at low communication cycle rates between leader and follower, control performance degradation is minimal compared to high-speed operation. We also prove our method can be implemented on two types of commercially available low-cost hardware with zero parameter adjustments. This highlights its high ease of implementation and versatility. We expect this method will expand the use of force feedback teleoperation systems on low-cost hardware. This will contribute to advancing contact-rich task autonomy in imitation learning.
Visual Spatial Attention and Proprioceptive Data-Driven Reinforcement Learning for Robust Peg-in-Hole Task Under Variable Conditions
Dec 27, 2023Anchor-bolt insertion is a peg-in-hole task performed in the construction field for holes in concrete. Efforts have been made to automate this task, but the variable lighting and hole surface conditions, as well as the requirements for short setup and task execution time make the automation challenging. In this study, we introduce a vision and proprioceptive data-driven robot control model for this task that is robust to challenging lighting and hole surface conditions. This model consists of a spatial attention point network (SAP) and a deep reinforcement learning (DRL) policy that are trained jointly end-to-end to control the robot. The model is trained in an offline manner, with a sample-efficient framework designed to reduce training time and minimize the reality gap when transferring the model to the physical world. Through evaluations with an industrial robot performing the task in 12 unknown holes, starting from 16 different initial positions, and under three different lighting conditions (two with misleading shadows), we demonstrate that SAP can generate relevant attention points of the image even in challenging lighting conditions. We also show that the proposed model enables task execution with higher success rate and shorter task completion time than various baselines. Due to the proposed model's high effectiveness even in severe lighting, initial positions, and hole conditions, and the offline training framework's high sample-efficiency and short training time, this approach can be easily applied to construction.
* Published in IEEE Robotics and Automation Letters in 08 February 2023
Real-time Motion Generation and Data Augmentation for Grasping Moving Objects with Dynamic Speed and Position Changes
Sep 22, 2023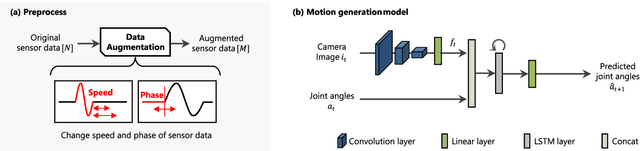
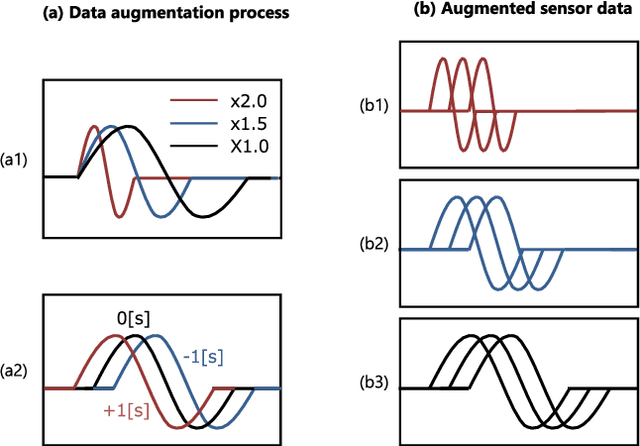
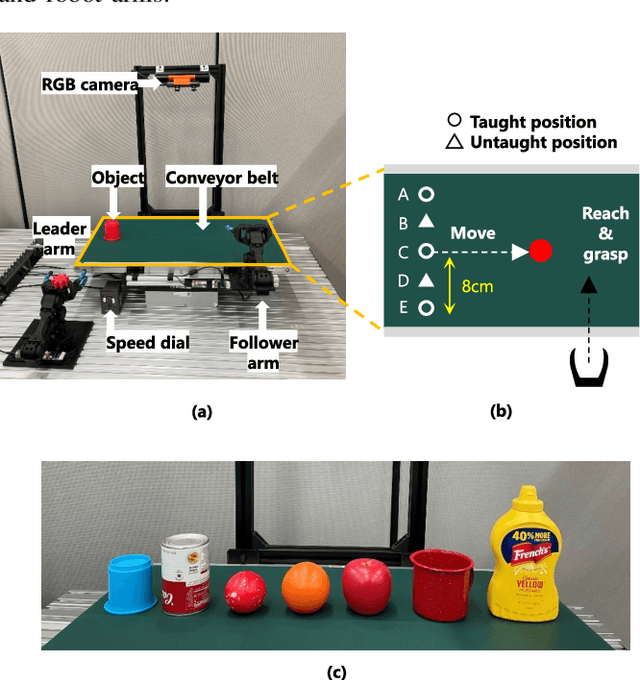

While deep learning enables real robots to perform complex tasks had been difficult to implement in the past, the challenge is the enormous amount of trial-and-error and motion teaching in a real environment. The manipulation of moving objects, due to their dynamic properties, requires learning a wide range of factors such as the object's position, movement speed, and grasping timing. We propose a data augmentation method for enabling a robot to grasp moving objects with different speeds and grasping timings at low cost. Specifically, the robot is taught to grasp an object moving at low speed using teleoperation, and multiple data with different speeds and grasping timings are generated by down-sampling and padding the robot sensor data in the time-series direction. By learning multiple sensor data in a time series, the robot can generate motions while adjusting the grasping timing for unlearned movement speeds and sudden speed changes. We have shown using a real robot that this data augmentation method facilitates learning the relationship between object position and velocity and enables the robot to perform robust grasping motions for unlearned positions and objects with dynamically changing positions and velocities.
Contact-Rich Manipulation of a Flexible Object based on Deep Predictive Learning using Vision and Tactility
Dec 13, 2021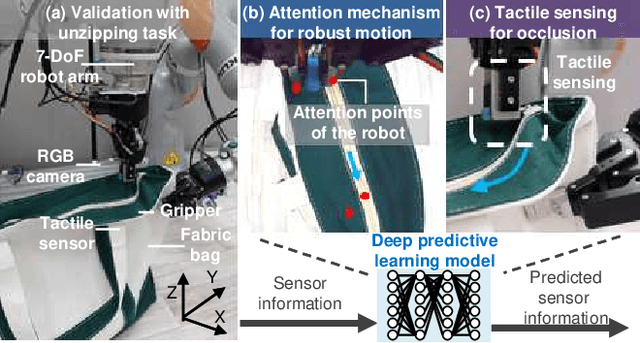
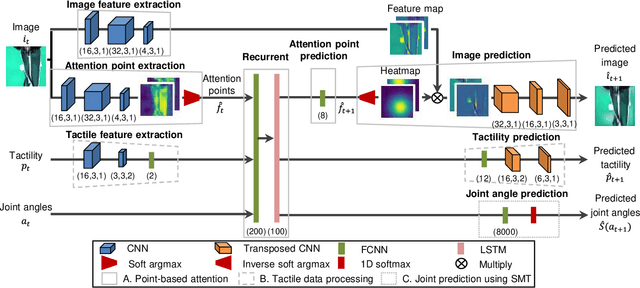

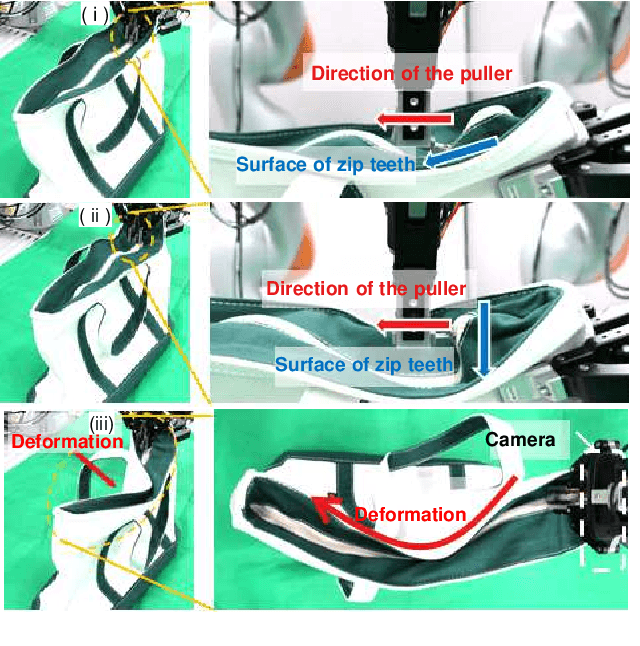
We achieved contact-rich flexible object manipulation, which was difficult to control with vision alone. In the unzipping task we chose as a validation task, the gripper grasps the puller, which hides the bag state such as the direction and amount of deformation behind it, making it difficult to obtain information to perform the task by vision alone. Additionally, the flexible fabric bag state constantly changes during operation, so the robot needs to dynamically respond to the change. However, the appropriate robot behavior for all bag states is difficult to prepare in advance. To solve this problem, we developed a model that can perform contact-rich flexible object manipulation by real-time prediction of vision with tactility. We introduced a point-based attention mechanism for extracting image features, softmax transformation for predicting motions, and convolutional neural network for extracting tactile features. The results of experiments using a real robot arm revealed that our method can realize motions responding to the deformation of the bag while reducing the load on the zipper. Furthermore, using tactility improved the success rate from 56.7% to 93.3% compared with vision alone, demonstrating the effectiveness and high performance of our method.
Spatial Attention Point Network for Deep-learning-based Robust Autonomous Robot Motion Generation
Mar 02, 2021
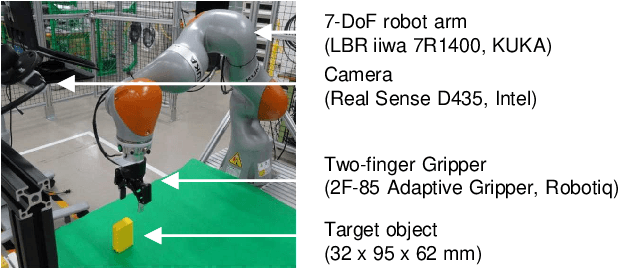
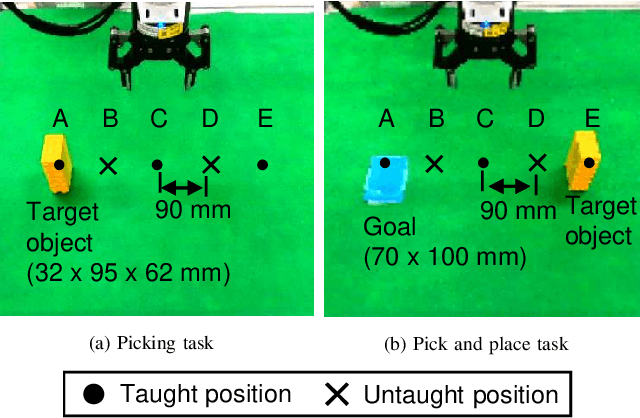

Deep learning provides a powerful framework for automated acquisition of complex robotic motions. However, despite a certain degree of generalization, the need for vast amounts of training data depending on the work-object position is an obstacle to industrial applications. Therefore, a robot motion-generation model that can respond to a variety of work-object positions with a small amount of training data is necessary. In this paper, we propose a method robust to changes in object position by automatically extracting spatial attention points in the image for the robot task and generating motions on the basis of their positions. We demonstrate our method with an LBR iiwa 7R1400 robot arm on a picking task and a pick-and-place task at various positions in various situations. In each task, the spatial attention points are obtained for the work objects that are important to the task. Our method is robust to changes in object position. Further, it is robust to changes in background, lighting, and obstacles that are not important to the task because it only focuses on positions that are important to the task.