 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Speaks Next? Multi-party AI Discussion Leveraging the Systematics of Turn-taking in Murder Mystery Games
Dec 06, 2024



Multi-agent systems utilizing large language models (LLMs) have shown great promise in achieving natural dialogue. However, smooth dialogue control and autonomous decision making among agents still remain challenges. In this study, we focus on conversational norms such as adjacency pairs and turn-taking found in conversation analysis and propose a new framework called "Murder Mystery Agents" that applies these norms to AI agents' dialogue control. As an evaluation target, we employed the "Murder Mystery" game, a reasoning-type table-top role-playing game that requires complex social reasoning and information manipulation. In this game, players need to unravel the truth of the case based on fragmentary information through cooperation and bargaining. The proposed framework integrates next speaker selection based on adjacency pairs and a self-selection mechanism that takes agents' internal states into account to achieve more natural and strategic dialogue. To verify the effectiveness of this new approach, we analyzed utterances that led to dialogue breakdowns and conducted automatic evaluation using LLMs, as well as human evaluation using evaluation criteria developed for the Murder Mystery game. Experimental results showed that the implementation of the next speaker selection mechanism significantly reduced dialogue breakdowns and improved the ability of agents to share information and perform logical reasoning. The results of this study demonstrate that the systematics of turn-taking in human conversation are also effective in controlling dialogue among AI agents, and provide design guidelines for more advanced multi-agent dialogue systems.
A Peg-in-hole Task Strategy for Holes in Concrete
Mar 29, 2024



A method that enables an industrial robot to accomplish the peg-in-hole task for holes in concrete is proposed. The proposed method involves slightly detaching the peg from the wall, when moving between search positions, to avoid the negative influence of the concrete's high friction coefficient. It uses a deep neural network (DNN), trained via reinforcement learning, to effectively find holes with variable shape and surface finish (due to the brittle nature of concrete) without analytical modeling or control parameter tuning. The method uses displacement of the peg toward the wall surface, in addition to force and torque, as one of the inputs of the DNN. Since the displacement increases as the peg gets closer to the hole (due to the chamfered shape of holes in concrete), it is a useful parameter for inputting in the DNN. The proposed method was evaluated by training the DNN on a hole 500 times and attempting to find 12 unknown holes. The results of the evaluation show the DNN enabled a robot to find the unknown holes with average success rate of 96.1% and average execution time of 12.5 seconds. Additional evaluations with random initial positions and a different type of peg demonstrate the trained DNN can generalize well to different conditions. Analyses of the influence of the peg displacement input showed the success rate of the DNN is increased by utilizing this parameter. These results validate the proposed method in terms of its effectiveness and applicability to the construction industry.
* Published in 2021 IEEE International Conference on Robotics and Automation (ICRA) on 30 May 2021
Visual Spatial Attention and Proprioceptive Data-Driven Reinforcement Learning for Robust Peg-in-Hole Task Under Variable Conditions
Dec 27, 2023Anchor-bolt insertion is a peg-in-hole task performed in the construction field for holes in concrete. Efforts have been made to automate this task, but the variable lighting and hole surface conditions, as well as the requirements for short setup and task execution time make the automation challenging. In this study, we introduce a vision and proprioceptive data-driven robot control model for this task that is robust to challenging lighting and hole surface conditions. This model consists of a spatial attention point network (SAP) and a deep reinforcement learning (DRL) policy that are trained jointly end-to-end to control the robot. The model is trained in an offline manner, with a sample-efficient framework designed to reduce training time and minimize the reality gap when transferring the model to the physical world. Through evaluations with an industrial robot performing the task in 12 unknown holes, starting from 16 different initial positions, and under three different lighting conditions (two with misleading shadows), we demonstrate that SAP can generate relevant attention points of the image even in challenging lighting conditions. We also show that the proposed model enables task execution with higher success rate and shorter task completion time than various baselines. Due to the proposed model's high effectiveness even in severe lighting, initial positions, and hole conditions, and the offline training framework's high sample-efficiency and short training time, this approach can be easily applied to construction.
* Published in IEEE Robotics and Automation Letters in 08 February 2023
Real-time Motion Generation and Data Augmentation for Grasping Moving Objects with Dynamic Speed and Position Changes
Sep 22, 2023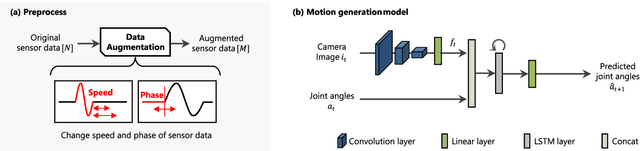
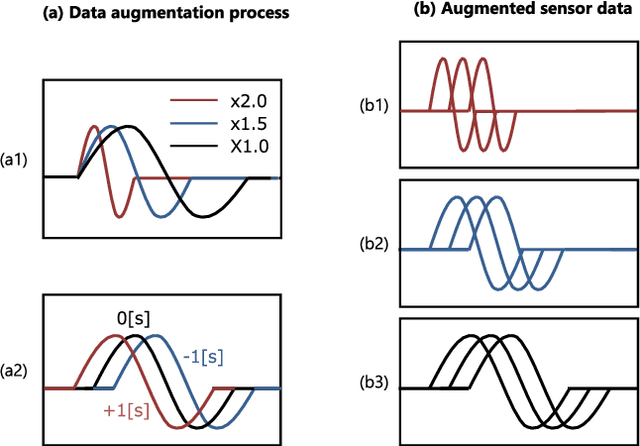
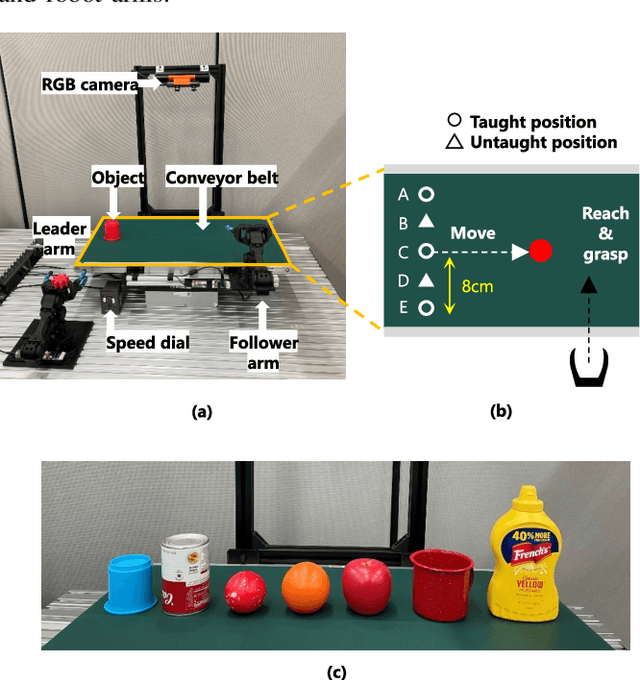

While deep learning enables real robots to perform complex tasks had been difficult to implement in the past, the challenge is the enormous amount of trial-and-error and motion teaching in a real environment. The manipulation of moving objects, due to their dynamic properties, requires learning a wide range of factors such as the object's position, movement speed, and grasping timing. We propose a data augmentation method for enabling a robot to grasp moving objects with different speeds and grasping timings at low cost. Specifically, the robot is taught to grasp an object moving at low speed using teleoperation, and multiple data with different speeds and grasping timings are generated by down-sampling and padding the robot sensor data in the time-series direction. By learning multiple sensor data in a time series, the robot can generate motions while adjusting the grasping timing for unlearned movement speeds and sudden speed changes. We have shown using a real robot that this data augmentation method facilitates learning the relationship between object position and velocity and enables the robot to perform robust grasping motions for unlearned positions and objects with dynamically changing positions and velocities.
A generative framework for conversational laughter: Its 'language model' and laughter sound synthesis
Jun 06, 2023As the phonetic and acoustic manifestations of laughter in conversation are highly diverse, laughter synthesis should be capable of accommodating such diversity while maintaining high controllability. This paper proposes a generative model of laughter in conversation that can produce a wide variety of laughter by utilizing the emotion dimension as a conversational context. The model comprises two parts: the laughter "phones generator," which generates various, but realistic, combinations of laughter components for a given speaker ID and emotional state, and the laughter "sound synthesizer," which receives the laughter phone sequence and produces acoustic features that reflect the speaker's individuality and emotional state. The results of a listening experiment indicated that conditioning both the phones generator and the sound synthesizer on emotion dimensions resulted in the most effective control of the perceived emotion in synthesized laughter.
Deep Active Visual Attention for Real-time Robot Motion Generation: Emergence of Tool-body Assimilation and Adaptive Tool-use
Jun 29, 2022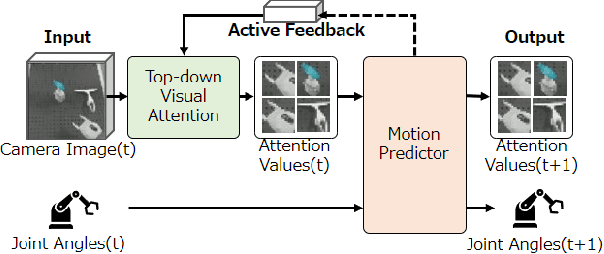

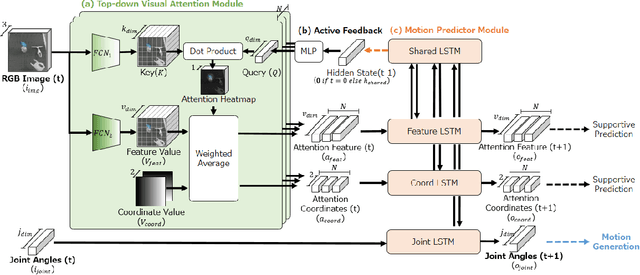
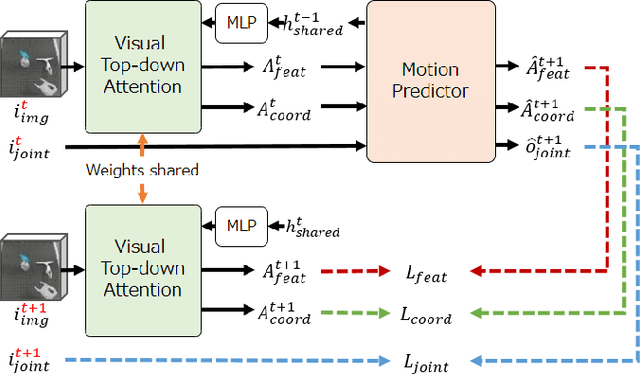
Sufficiently perceiving the environment is a critical factor in robot motion generation. Although the introduction of deep visual processing models have contributed in extending this ability, existing methods lack in the ability to actively modify what to perceive; humans perform internally during visual cognitive processes. This paper addresses the issue by proposing a novel robot motion generation model, inspired by a human cognitive structure. The model incorporates a state-driven active top-down visual attention module, which acquires attentions that can actively change targets based on task states. We term such attentions as role-based attentions, since the acquired attention directed to targets that shared a coherent role throughout the motion. The model was trained on a robot tool-use task, in which the role-based attentions perceived the robot grippers and tool as identical end-effectors, during object picking and object dragging motions respectively. This is analogous to a biological phenomenon called tool-body assimilation, in which one regards a handled tool as an extension of one's body. The results suggested an improvement of flexibility in model's visual perception, which sustained stable attention and motion even if it was provided with untrained tools or exposed to experimenter's distractions.
Collision-free Path Planning on Arbitrary Optimization Criteria in the Latent Space through cGANs
Feb 26, 2022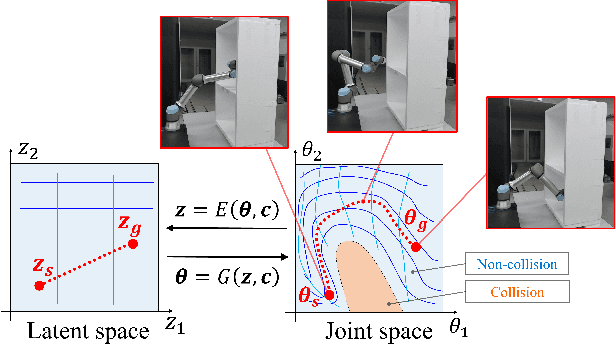
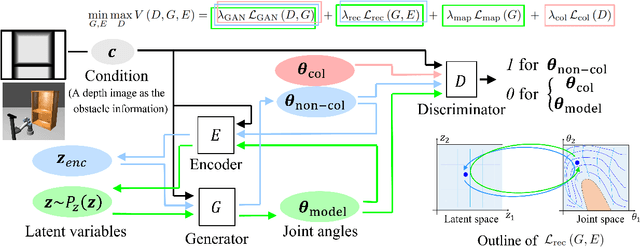
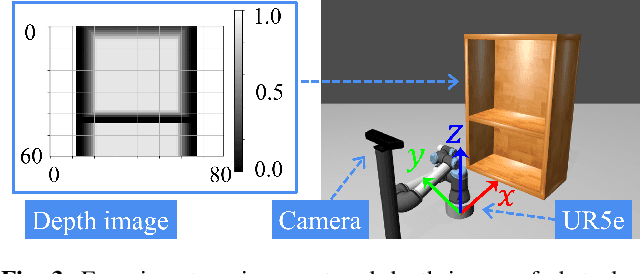

We propose a new method for collision-free path planning by Conditional Generative Adversarial Networks (cGANs) by mapping its latent space to only the collision-free areas of the robot joint space when an obstacle map is given as a condition. When manipulating a robot arm, it is necessary to generate a trajectory that avoids contact with the robot itself or the surrounding environment for safety reasons, and it is convenient to generate multiple arbitrary trajectories appropriate for respective purposes. In the proposed method, various trajectories to avoid obstacles can be generated by connecting the start and goal with arbitrary line segments in this latent space. Our method simply provides this collision-free latent space after which any planner, using any optimization conditions, can be used to generate the most suitable paths on the fly. We successfully verified this method with a simulated and actual UR5e 6-DoF robotic arm. We confirmed that different trajectories can be generated according to different optimization conditions.
Guided Visual Attention Model Based on Interactions Between Top-down and Bottom-up Information for Robot Pose Prediction
Feb 21, 2022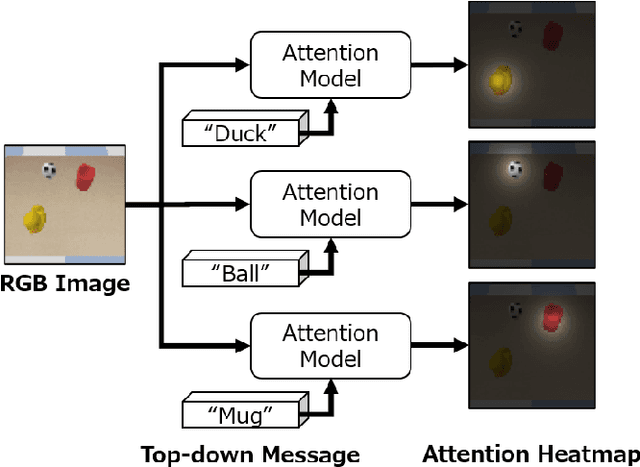
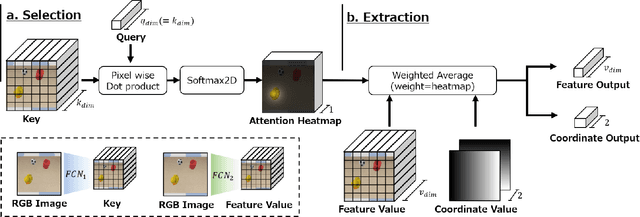
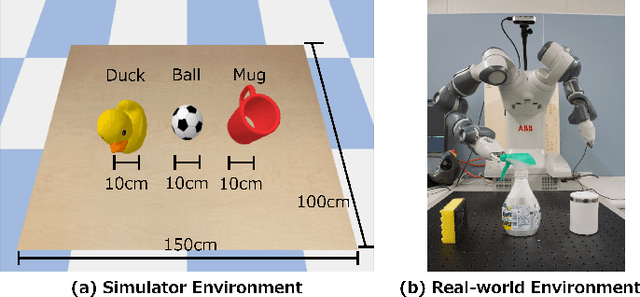

Learning to control a robot commonly requires mapping between robot states and camera images, where conventional deep vision models require large training dataset. Existing visual attention models, such as Deep Spatial Autoencoders, have improved the data-efficiency by training the model to selectively extract only the task relevant image area. However, since the models are unable to select attention targets on demand, the diversity of trainable tasks are limited. This paper proposed a novel Key-Query-Value formulated visual attention model which can be guided to a certain attention target. The model creates an attention heatmap from Key and Query, and selectively extracts the attended data represented in Value. Such structure is capable of incorporating external inputs to create the Query, which will be trained to represent the target objects. The separation of Query creation improved the model's flexibility, enabling to simultaneously obtain and switch between multiple targets in a top-down manner. The proposed model is experimented on a simulator and a real-world environment, showing better performance compared to existing end-to-end robot vision models. The results of real-world experiments indicated the model's high scalability and extendiblity on robot controlling tasks.
Collision-free Path Planning in the Latent Space through cGANs
Feb 15, 2022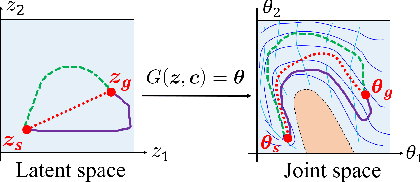
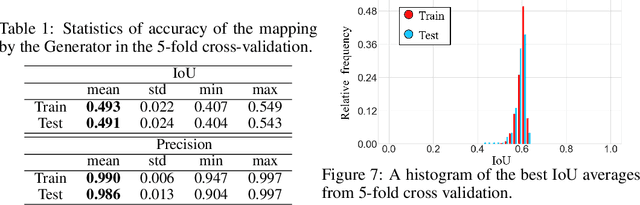
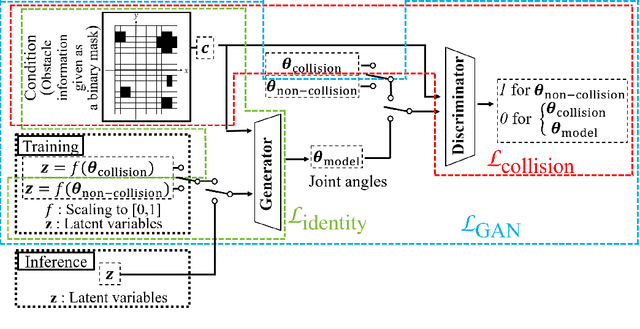
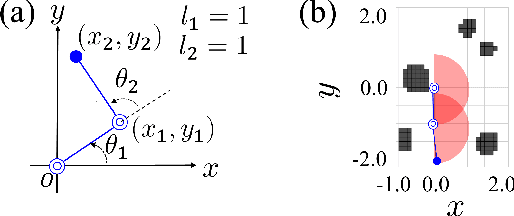
We show a new method for collision-free path planning by cGANs by mapping its latent space to only the collision-free areas of the robot joint space. Our method simply provides this collision-free latent space after which any planner, using any optimization conditions, can be used to generate the most suitable paths on the fly. We successfully verified this method with a simulated two-link robot arm.
Contact-Rich Manipulation of a Flexible Object based on Deep Predictive Learning using Vision and Tactility
Dec 13, 2021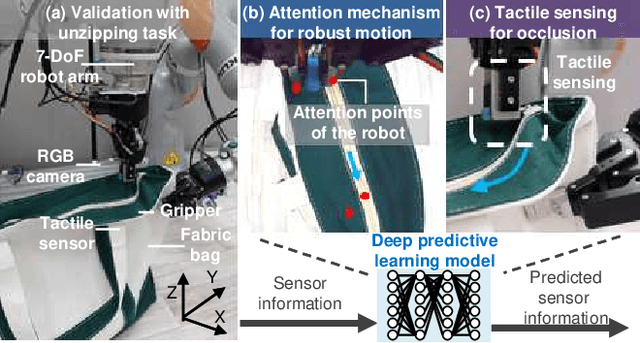
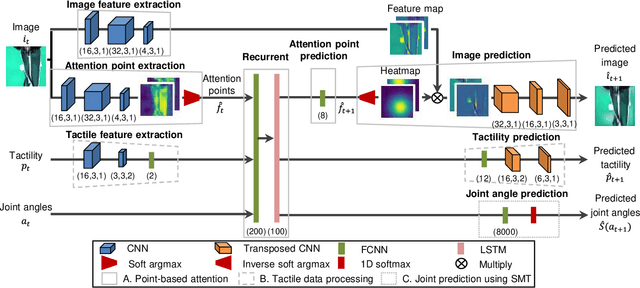

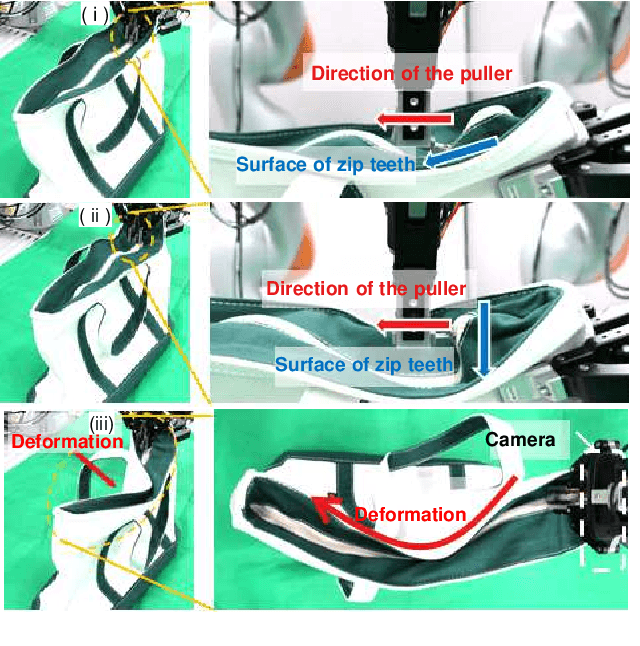
We achieved contact-rich flexible object manipulation, which was difficult to control with vision alone. In the unzipping task we chose as a validation task, the gripper grasps the puller, which hides the bag state such as the direction and amount of deformation behind it, making it difficult to obtain information to perform the task by vision alone. Additionally, the flexible fabric bag state constantly changes during operation, so the robot needs to dynamically respond to the change. However, the appropriate robot behavior for all bag states is difficult to prepare in advance. To solve this problem, we developed a model that can perform contact-rich flexible object manipulation by real-time prediction of vision with tactility. We introduced a point-based attention mechanism for extracting image features, softmax transformation for predicting motions, and convolutional neural network for extracting tactile features. The results of experiments using a real robot arm revealed that our method can realize motions responding to the deformation of the bag while reducing the load on the zipper. Furthermore, using tactility improved the success rate from 56.7% to 93.3% compared with vision alone, demonstrating the effectiveness and high performance of our method.