 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Motion Generation Using Uncertainty-Driven Foresight Prediction
Oct 01, 2024


Uncertainty of environments has long been a difficult characteristic to handle, when performing real-world robot tasks. This is because the uncertainty produces unexpected observations that cannot be covered by manual scripting. Learning based robot controlling methods are a promising approach for generating flexible motions against unknown situations, but still tend to suffer under uncertainty due to its deterministic nature. In order to adaptively perform the target task under such conditions, the robot control model must be able to accurately understand the possible uncertainty, and to exploratively derive the optimal action that minimizes such uncertainty. This paper extended an existing predictive learning based robot control method, which employ foresight prediction using dynamic internal simulation. The foresight module refines the model's hidden states by sampling multiple possible futures and replace with the one that led to the lower future uncertainty. The adaptiveness of the model was evaluated on a door opening task. The door can be opened either by pushing, pulling, or sliding, but robot cannot visually distinguish which way, and is required to adapt on the fly. The results showed that the proposed model adaptively diverged its motion through interaction with the door, whereas conventional methods failed to stably diverge. The models were analyzed on Lyapunov exponents of RNN hidden states which reflect the possible divergence at each time step during task execution. The result indicated that the foresight module biased the model to consider future consequences, which lead to embedding uncertainties at the policy of the robot controller, rather than the resultant observation. This is beneficial for implementing adaptive behaviors, which indices derivation of diverse motion during exploration.
Deep Active Visual Attention for Real-time Robot Motion Generation: Emergence of Tool-body Assimilation and Adaptive Tool-use
Jun 29, 2022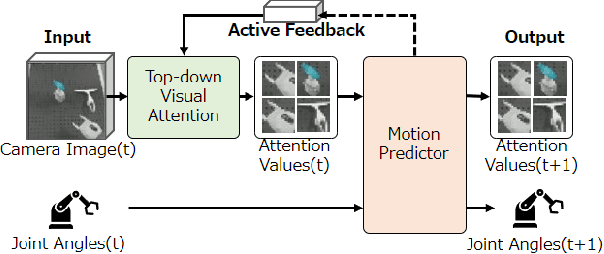

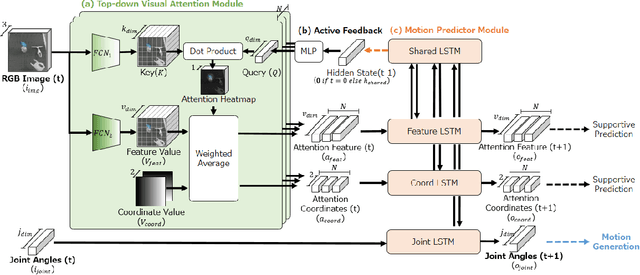
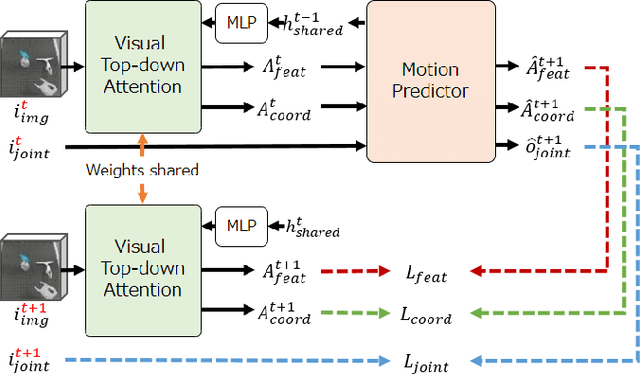
Sufficiently perceiving the environment is a critical factor in robot motion generation. Although the introduction of deep visual processing models have contributed in extending this ability, existing methods lack in the ability to actively modify what to perceive; humans perform internally during visual cognitive processes. This paper addresses the issue by proposing a novel robot motion generation model, inspired by a human cognitive structure. The model incorporates a state-driven active top-down visual attention module, which acquires attentions that can actively change targets based on task states. We term such attentions as role-based attentions, since the acquired attention directed to targets that shared a coherent role throughout the motion. The model was trained on a robot tool-use task, in which the role-based attentions perceived the robot grippers and tool as identical end-effectors, during object picking and object dragging motions respectively. This is analogous to a biological phenomenon called tool-body assimilation, in which one regards a handled tool as an extension of one's body. The results suggested an improvement of flexibility in model's visual perception, which sustained stable attention and motion even if it was provided with untrained tools or exposed to experimenter's distractions.
Guided Visual Attention Model Based on Interactions Between Top-down and Bottom-up Information for Robot Pose Prediction
Feb 21, 2022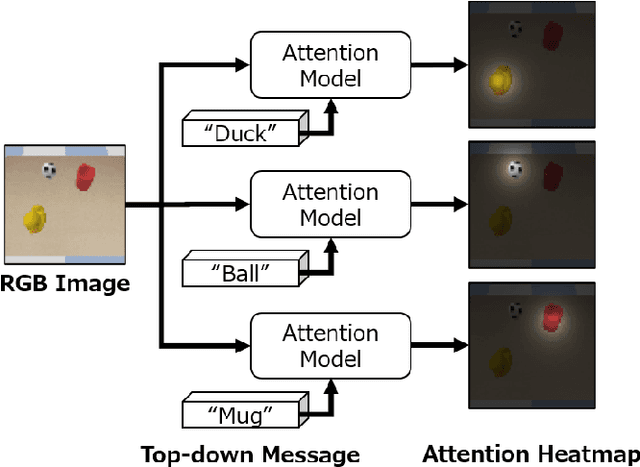
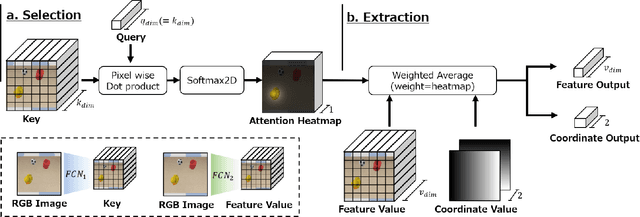
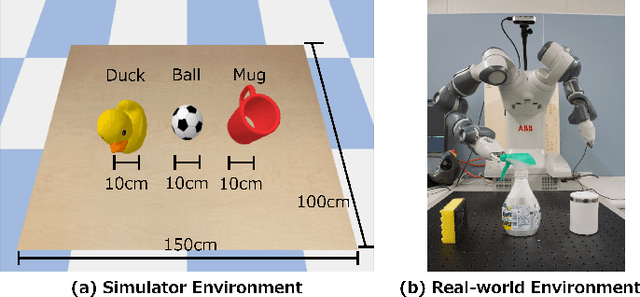

Learning to control a robot commonly requires mapping between robot states and camera images, where conventional deep vision models require large training dataset. Existing visual attention models, such as Deep Spatial Autoencoders, have improved the data-efficiency by training the model to selectively extract only the task relevant image area. However, since the models are unable to select attention targets on demand, the diversity of trainable tasks are limited. This paper proposed a novel Key-Query-Value formulated visual attention model which can be guided to a certain attention target. The model creates an attention heatmap from Key and Query, and selectively extracts the attended data represented in Value. Such structure is capable of incorporating external inputs to create the Query, which will be trained to represent the target objects. The separation of Query creation improved the model's flexibility, enabling to simultaneously obtain and switch between multiple targets in a top-down manner. The proposed model is experimented on a simulator and a real-world environment, showing better performance compared to existing end-to-end robot vision models. The results of real-world experiments indicated the model's high scalability and extendiblity on robot controlling tasks.