 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Visual Attention Model Based on Interactions Between Top-down and Bottom-up Information for Robot Pose Prediction
Paper and Code
Feb 21, 2022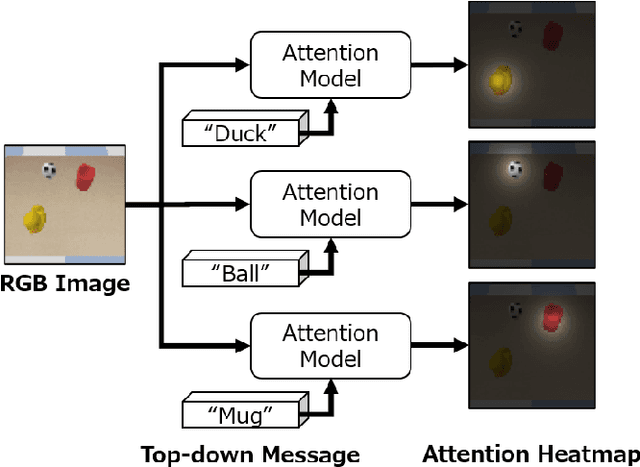
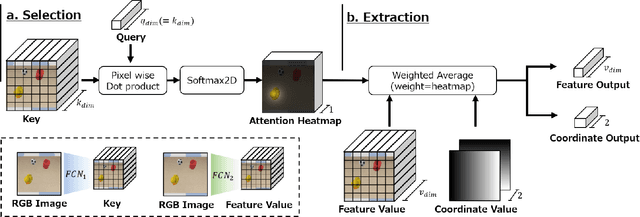
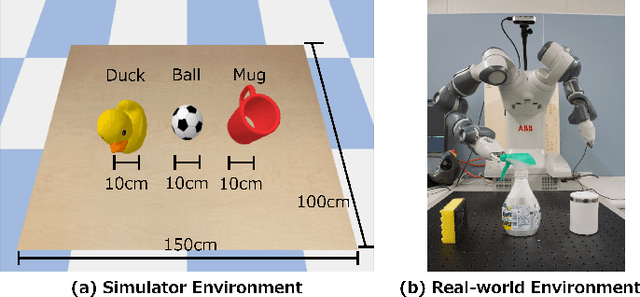

Learning to control a robot commonly requires mapping between robot states and camera images, where conventional deep vision models require large training dataset. Existing visual attention models, such as Deep Spatial Autoencoders, have improved the data-efficiency by training the model to selectively extract only the task relevant image area. However, since the models are unable to select attention targets on demand, the diversity of trainable tasks are limited. This paper proposed a novel Key-Query-Value formulated visual attention model which can be guided to a certain attention target. The model creates an attention heatmap from Key and Query, and selectively extracts the attended data represented in Value. Such structure is capable of incorporating external inputs to create the Query, which will be trained to represent the target objects. The separation of Query creation improved the model's flexibility, enabling to simultaneously obtain and switch between multiple targets in a top-down manner. The proposed model is experimented on a simulator and a real-world environment, showing better performance compared to existing end-to-end robot vision models. The results of real-world experiments indicated the model's high scalability and extendiblity on robot controlling tasks.