 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaSA: Two-Phased Deep Predictive Learning of Tactile Sensory Attenuation for Improving In-Grasp Manipulation
Feb 05, 2026Humans can achieve diverse in-hand manipulations, such as object pinching and tool use, which often involve simultaneous contact between the object and multiple fingers. This is still an open issue for robotic hands because such dexterous manipulation requires distinguishing between tactile sensations generated by their self-contact and those arising from external contact. Otherwise, object/robot breakage happens due to contacts/collisions. Indeed, most approaches ignore self-contact altogether, by constraining motion to avoid/ignore self-tactile information during contact. While this reduces complexity, it also limits generalization to real-world scenarios where self-contact is inevitable. Humans overcome this challenge through self-touch perception, using predictive mechanisms that anticipate the tactile consequences of their own motion, through a principle called sensory attenuation, where the nervous system differentiates predictable self-touch signals, allowing novel object stimuli to stand out as relevant. Deriving from this, we introduce TaSA, a two-phased deep predictive learning framework. In the first phase, TaSA explicitly learns self-touch dynamics, modeling how a robot's own actions generate tactile feedback. In the second phase, this learned model is incorporated into the motion learning phase, to emphasize object contact signals during manipulation. We evaluate TaSA on a set of insertion tasks, which demand fine tactile discrimination: inserting a pencil lead into a mechanical pencil, inserting coins into a slot, and fixing a paper clip onto a sheet of paper, with various orientations, positions, and sizes. Across all tasks, policies trained with TaSA achieve significantly higher success rates than baseline methods, demonstrating that structured tactile perception with self-touch based on sensory attenuation is critical for dexterous robotic manipulation.
Close-Fitting Dressing Assistance Based on State Estimation of Feet and Garments with Semantic-based Visual Attention
May 06, 2025As the population continues to age, a shortage of caregivers is expected in the future. Dressing assistance, in particular, is crucial for opportunities for social participation. Especially dressing close-fitting garments, such as socks, remains challenging due to the need for fine force adjustments to handle the friction or snagging against the skin, while considering the shape and position of the garment. This study introduces a method uses multi-modal information including not only robot's camera images, joint angles, joint torques, but also tactile forces for proper force interaction that can adapt to individual differences in humans. Furthermore, by introducing semantic information based on object concepts, rather than relying solely on RGB data, it can be generalized to unseen feet and background. In addition, incorporating depth data helps infer relative spatial relationship between the sock and the foot. To validate its capability for semantic object conceptualization and to ensure safety, training data were collected using a mannequin, and subsequent experiments were conducted with human subjects. In experiments, the robot successfully adapted to previously unseen human feet and was able to put socks on 10 participants, achieving a higher success rate than Action Chunking with Transformer and Diffusion Policy. These results demonstrate that the proposed model can estimate the state of both the garment and the foot, enabling precise dressing assistance for close-fitting garments.
Dual-arm Motion Generation for Repositioning Care based on Deep Predictive Learning with Somatosensory Attention Mechanism
Jul 18, 2024A versatile robot working in a domestic environment based on a deep neural network (DNN) is currently attracting attention. One of the roles expected for domestic robots is caregiving for a human. In particular, we focus on repositioning care because repositioning plays a fundamental role in supporting the health and quality of life of individuals with limited mobility. However, generating motions of the repositioning care, avoiding applying force to non-target parts and applying appropriate force to target parts, remains challenging. In this study, we proposed a DNN-based architecture using visual and somatosensory attention mechanisms that can generate dual-arm repositioning motions which involve different sequential policies of interaction force; contact-less reaching and contact-based assisting motions. We used the humanoid robot Dry-AIREC, which features the capability to adjust joint impedance dynamically. In the experiment, the repositioning assistance from the supine position to the sitting position was conducted by Dry-AIREC. The trained model, utilizing the proposed architecture, successfully guided the robot's hand to the back of the mannequin without excessive contact force on the mannequin and provided adequate support and appropriate contact for postural adjustment.
Realtime Motion Generation with Active Perception Using Attention Mechanism for Cooking Robot
Sep 26, 2023



To support humans in their daily lives, robots are required to autonomously learn, adapt to objects and environments, and perform the appropriate actions. We tackled on the task of cooking scrambled eggs using real ingredients, in which the robot needs to perceive the states of the egg and adjust stirring movement in real time, while the egg is heated and the state changes continuously. In previous works, handling changing objects was found to be challenging because sensory information includes dynamical, both important or noisy information, and the modality which should be focused on changes every time, making it difficult to realize both perception and motion generation in real time. We propose a predictive recurrent neural network with an attention mechanism that can weigh the sensor input, distinguishing how important and reliable each modality is, that realize quick and efficient perception and motion generation. The model is trained with learning from the demonstration, and allows the robot to acquire human-like skills. We validated the proposed technique using the robot, Dry-AIREC, and with our learning model, it could perform cooking eggs with unknown ingredients. The robot could change the method of stirring and direction depending on the status of the egg, as in the beginning it stirs in the whole pot, then subsequently, after the egg started being heated, it starts flipping and splitting motion targeting specific areas, although we did not explicitly indicate them.
Multi-Fingered In-Hand Manipulation with Various Object Properties Using Graph Convolutional Networks and Distributed Tactile Sensors
May 09, 2022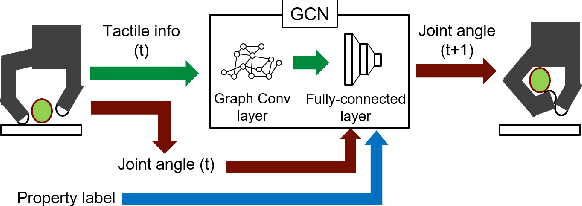
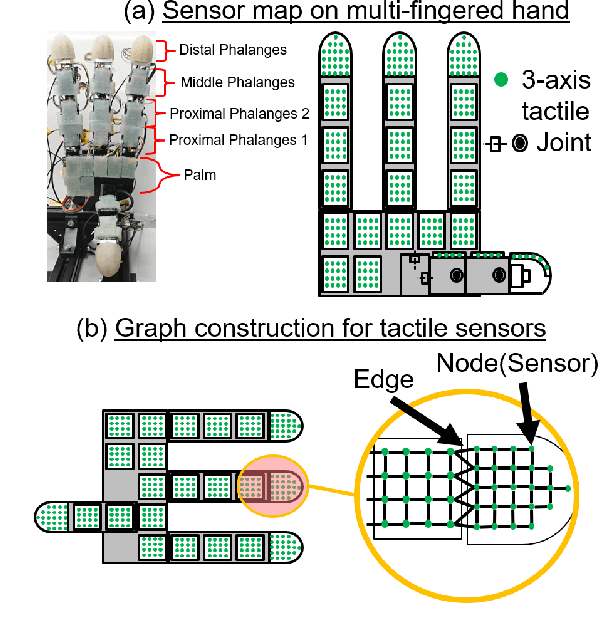


Multi-fingered hands could be used to achieve many dexterous manipulation tasks, similarly to humans, and tactile sensing could enhance the manipulation stability for a variety of objects. However, tactile sensors on multi-fingered hands have a variety of sizes and shapes. Convolutional neural networks (CNN) can be useful for processing tactile information, but the information from multi-fingered hands needs an arbitrary pre-processing, as CNNs require a rectangularly shaped input, which may lead to unstable results. Therefore, how to process such complex shaped tactile information and utilize it for achieving manipulation skills is still an open issue. This paper presents a control method based on a graph convolutional network (GCN) which extracts geodesical features from the tactile data with complicated sensor alignments. Moreover, object property labels are provided to the GCN to adjust in-hand manipulation motions. Distributed tri-axial tactile sensors are mounted on the fingertips, finger phalanges and palm of an Allegro hand, resulting in 1152 tactile measurements. Training data is collected with a data-glove to transfer human dexterous manipulation directly to the robot hand. The GCN achieved high success rates for in-hand manipulation. We also confirmed that fragile objects were deformed less when correct object labels were provided to the GCN. When visualizing the activation of the GCN with a PCA, we verified that the network acquired geodesical features. Our method achieved stable manipulation even when an experimenter pulled a grasped object and for untrained objects.
How to select and use tools? : Active Perception of Target Objects Using Multimodal Deep Learning
Jun 04, 2021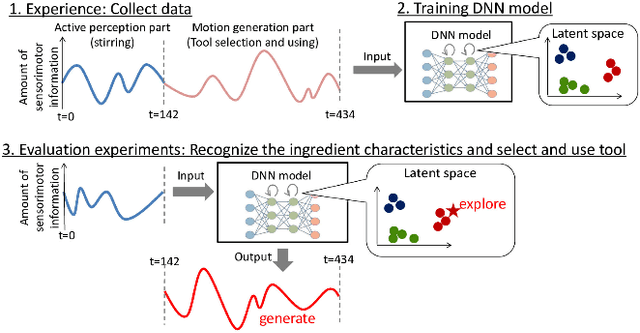
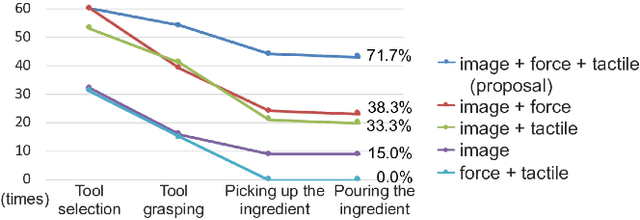


Selection of appropriate tools and use of them when performing daily tasks is a critical function for introducing robots for domestic applications. In previous studies, however, adaptability to target objects was limited, making it difficult to accordingly change tools and adjust actions. To manipulate various objects with tools, robots must both understand tool functions and recognize object characteristics to discern a tool-object-action relation. We focus on active perception using multimodal sensorimotor data while a robot interacts with objects, and allow the robot to recognize their extrinsic and intrinsic characteristics. We construct a deep neural networks (DNN) model that learns to recognize object characteristics, acquires tool-object-action relations, and generates motions for tool selection and handling. As an example tool-use situation, the robot performs an ingredients transfer task, using a turner or ladle to transfer an ingredient from a pot to a bowl. The results confirm that the robot recognizes object characteristics and servings even when the target ingredients are unknown. We also examine the contributions of images, force, and tactile data and show that learning a variety of multimodal information results in rich perception for tool use.
* Best Paper Award of Cognitive Robotics in ICRA2021 IEEE Robotics and Automation Letters 2021, Proceedings of the 2021 International Conference on Robotics and Automation (ICRA 2021), 2021
Rethinking Self-driving: Multi-task Knowledge for Better Generalization and Accident Explanation Ability
Sep 28, 2018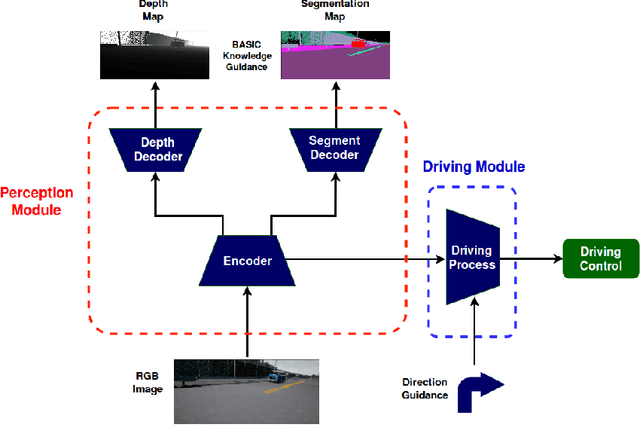

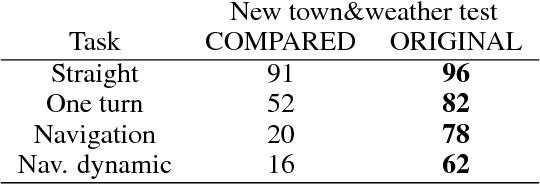

Current end-to-end deep learning driving models have two problems: (1) Poor generalization ability of unobserved driving environment when diversity of training driving dataset is limited (2) Lack of accident explanation ability when driving models don't work as expected. To tackle these two problems, rooted on the believe that knowledge of associated easy task is benificial for addressing difficult task, we proposed a new driving model which is composed of perception module for \textit{see and think} and driving module for \textit{behave}, and trained it with multi-task perception-related basic knowledge and driving knowledge stepwisely. Specifically segmentation map and depth map (pixel level understanding of images) were considered as \textit{what \& where} and \textit{how far} knowledge for tackling easier driving-related perception problems before generating final control commands for difficult driving task. The results of experiments demonstrated the effectiveness of multi-task perception knowledge for better generalization and accident explanation ability. With our method the average sucess rate of finishing most difficult navigation tasks in untrained city of CoRL test surpassed current benchmark method for 15 percent in trained weather and 20 percent in untrained weathers. Demonstration video link is: https://www.youtube.com/watch?v=N7ePnnZZwdE
Detecting Features of Tools, Objects, and Actions from Effects in a Robot using Deep Learning
Sep 23, 2018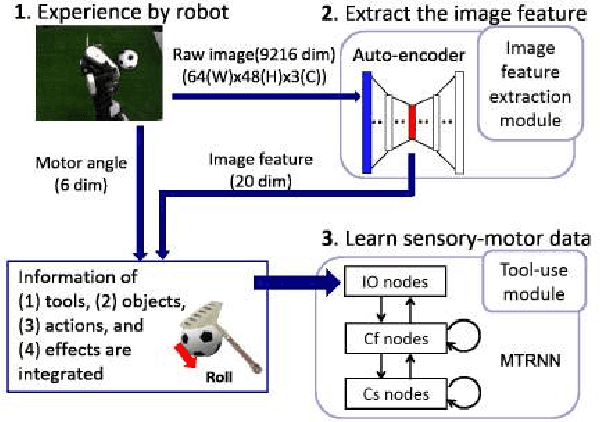
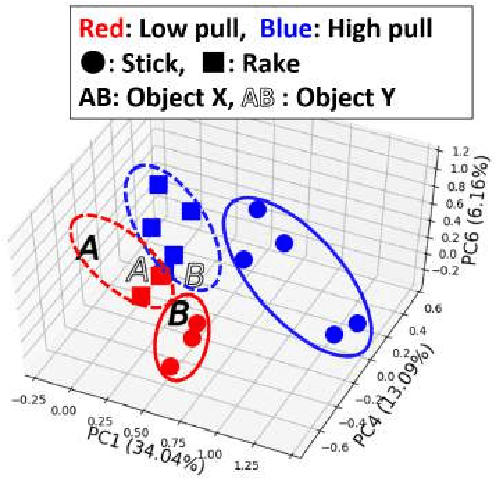

We propose a tool-use model that can detect the features of tools, target objects, and actions from the provided effects of object manipulation. We construct a model that enables robots to manipulate objects with tools, using infant learning as a concept. To realize this, we train sensory-motor data recorded during a tool-use task performed by a robot with deep learning. Experiments include four factors: (1) tools, (2) objects, (3) actions, and (4) effects, which the model considers simultaneously. For evaluation, the robot generates predicted images and motions given information of the effects of using unknown tools and objects. We confirm that the robot is capable of detecting features of tools, objects, and actions by learning the effects and executing the task.