 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPASE: A Generative Model for Universal Speech Enhancement with High Fidelity and Low Hallucinations
Apr 16, 2026Universal speech enhancement (USE) aims to restore speech signals from diverse distortions across multiple sampling rates. We propose UniPASE, an extension of the low-hallucination PASE framework tailored for USE. At its core is DeWavLM-Omni, a unified representation-level enhancement module fine-tuned from WavLM via knowledge distillation on a large-scale supervised multi-distortion dataset. This module directly converts degraded waveforms into clean and linguistically faithful phonetic representations, ensuring robust enhancement with minimal linguistic hallucination. Based on these enhanced phonetic representations, an Adapter generates enhanced acoustic representations containing rich acoustic details, which a neural Vocoder uses to reconstruct corresponding high-fidelity 16-kHz waveforms. A PostNet then converts the waveforms to 48~kHz before resampling them to their original rates, enabling seamless handling of inputs and outputs at multiple sampling rates. Experimental results on several evaluation datasets, covering sub-tasks and full tasks, demonstrate that UniPASE achieves superior or competitive performance compared with existing state-of-the-art models. The proposed model also serves as the backbone of our submission to the URGENT 2026 Challenge, which achieved 1st place in the objective evaluation. The source code and audio demos are available at https://github.com/xiaobin-rong/unipase/.
GAP-URGENet: A Generative-Predictive Fusion Framework for Universal Speech Enhancement
Apr 02, 2026We introduce GAP-URGENet, a generative-predictive fusion framework developed for Track 1 of the ICASSP 2026 URGENT Challenge. The system integrates a generative branch, which performs full-stack speech restoration in a self-supervised representation domain and reconstructs the waveform via a neural vocoder, along with a predictive branch that performs spectrogram-domain enhancement, providing complementary cues. Outputs from both branches are fused by a post-processing module, which also performs bandwidth extension to generate the enhanced waveform at 48 kHz, later downsampled to the original sampling rate. This generative-predictive fusion improves robustness and perceptual quality, achieving top performance in the blind-test phase and ranking 1st in the objective evaluation. Audio examples are available at https://xiaobin-rong.github.io/gap-urgenet_demo.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Learning Vision-Driven Reactive Soccer Skills for Humanoid Robots
Nov 06, 2025Humanoid soccer poses a representative challenge for embodied intelligence, requiring robots to operate within a tightly coupled perception-action loop. However, existing systems typically rely on decoupled modules, resulting in delayed responses and incoherent behaviors in dynamic environments, while real-world perceptual limitations further exacerbate these issues. In this work, we present a unified reinforcement learning-based controller that enables humanoid robots to acquire reactive soccer skills through the direct integration of visual perception and motion control. Our approach extends Adversarial Motion Priors to perceptual settings in real-world dynamic environments, bridging motion imitation and visually grounded dynamic control. We introduce an encoder-decoder architecture combined with a virtual perception system that models real-world visual characteristics, allowing the policy to recover privileged states from imperfect observations and establish active coordination between perception and action. The resulting controller demonstrates strong reactivity, consistently executing coherent and robust soccer behaviors across various scenarios, including real RoboCup matches.
Booster Gym: An End-to-End Reinforcement Learning Framework for Humanoid Robot Locomotion
Jun 18, 2025Recent advancements in reinforcement learning (RL) have led to significant progress in humanoid robot locomotion, simplifying the design and training of motion policies in simulation. However, the numerous implementation details make transferring these policies to real-world robots a challenging task. To address this, we have developed a comprehensive code framework that covers the entire process from training to deployment, incorporating common RL training methods, domain randomization, reward function design, and solutions for handling parallel structures. This library is made available as a community resource, with detailed descriptions of its design and experimental results. We validate the framework on the Booster T1 robot, demonstrating that the trained policies seamlessly transfer to the physical platform, enabling capabilities such as omnidirectional walking, disturbance resistance, and terrain adaptability. We hope this work provides a convenient tool for the robotics community, accelerating the development of humanoid robots. The code can be found in https://github.com/BoosterRobotics/booster_gym.
TS-URGENet: A Three-stage Universal Robust and Generalizable Speech Enhancement Network
May 24, 2025Universal speech enhancement aims to handle input speech with different distortions and input formats. To tackle this challenge, we present TS-URGENet, a Three-Stage Universal, Robust, and Generalizable speech Enhancement Network. To address various distortions, the proposed system employs a novel three-stage architecture consisting of a filling stage, a separation stage, and a restoration stage. The filling stage mitigates packet loss by preliminarily filling lost regions under noise interference, ensuring signal continuity. The separation stage suppresses noise, reverberation, and clipping distortion to improve speech clarity. Finally, the restoration stage compensates for bandwidth limitation, codec artifacts, and residual packet loss distortion, refining the overall speech quality. Our proposed TS-URGENet achieved outstanding performance in the Interspeech 2025 URGENT Challenge, ranking 2nd in Track 1.
Close-Fitting Dressing Assistance Based on State Estimation of Feet and Garments with Semantic-based Visual Attention
May 06, 2025As the population continues to age, a shortage of caregivers is expected in the future. Dressing assistance, in particular, is crucial for opportunities for social participation. Especially dressing close-fitting garments, such as socks, remains challenging due to the need for fine force adjustments to handle the friction or snagging against the skin, while considering the shape and position of the garment. This study introduces a method uses multi-modal information including not only robot's camera images, joint angles, joint torques, but also tactile forces for proper force interaction that can adapt to individual differences in humans. Furthermore, by introducing semantic information based on object concepts, rather than relying solely on RGB data, it can be generalized to unseen feet and background. In addition, incorporating depth data helps infer relative spatial relationship between the sock and the foot. To validate its capability for semantic object conceptualization and to ensure safety, training data were collected using a mannequin, and subsequent experiments were conducted with human subjects. In experiments, the robot successfully adapted to previously unseen human feet and was able to put socks on 10 participants, achieving a higher success rate than Action Chunking with Transformer and Diffusion Policy. These results demonstrate that the proposed model can estimate the state of both the garment and the foot, enabling precise dressing assistance for close-fitting garments.
HiFAR: Multi-Stage Curriculum Learning for High-Dynamics Humanoid Fall Recovery
Feb 28, 2025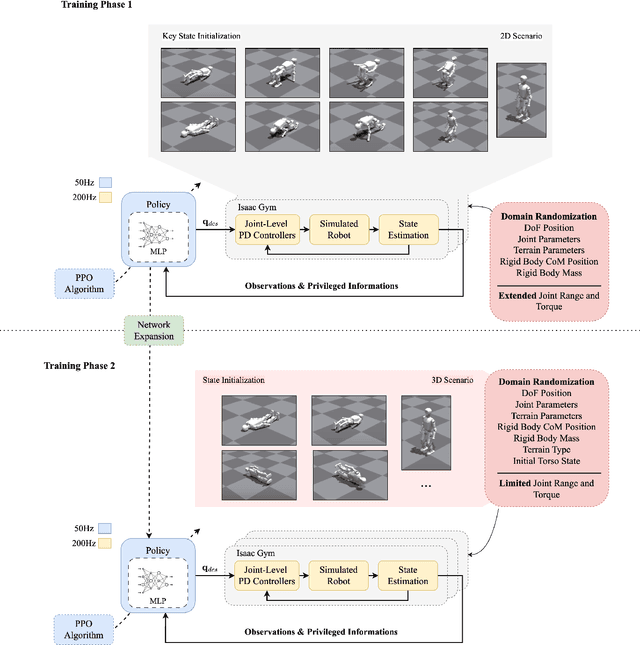
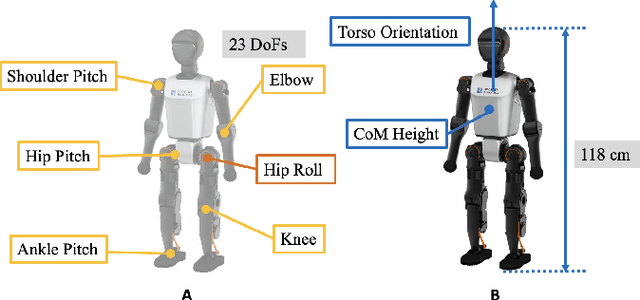
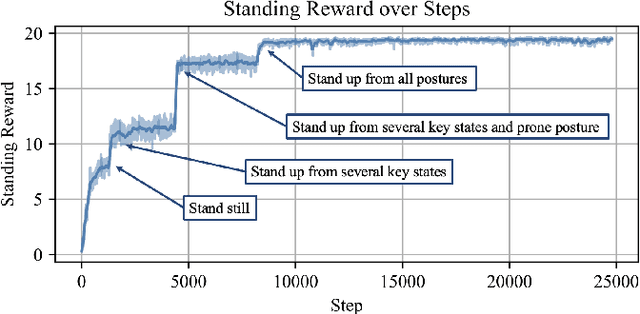
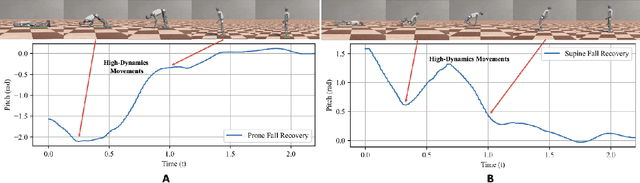
Humanoid robots encounter considerable difficulties in autonomously recovering from falls, especially within dynamic and unstructured environments. Conventional control methodologies are often inadequate in addressing the complexities associated with high-dimensional dynamics and the contact-rich nature of fall recovery. Meanwhile, reinforcement learning techniques are hindered by issues related to sparse rewards, intricate collision scenarios, and discrepancies between simulation and real-world applications. In this study, we introduce a multi-stage curriculum learning framework, termed HiFAR. This framework employs a staged learning approach that progressively incorporates increasingly complex and high-dimensional recovery tasks, thereby facilitating the robot's acquisition of efficient and stable fall recovery strategies. Furthermore, it enables the robot to adapt its policy to effectively manage real-world fall incidents. We assess the efficacy of the proposed method using a real humanoid robot, showcasing its capability to autonomously recover from a diverse range of falls with high success rates, rapid recovery times, robustness, and generalization.
Dual-arm Motion Generation for Repositioning Care based on Deep Predictive Learning with Somatosensory Attention Mechanism
Jul 18, 2024A versatile robot working in a domestic environment based on a deep neural network (DNN) is currently attracting attention. One of the roles expected for domestic robots is caregiving for a human. In particular, we focus on repositioning care because repositioning plays a fundamental role in supporting the health and quality of life of individuals with limited mobility. However, generating motions of the repositioning care, avoiding applying force to non-target parts and applying appropriate force to target parts, remains challenging. In this study, we proposed a DNN-based architecture using visual and somatosensory attention mechanisms that can generate dual-arm repositioning motions which involve different sequential policies of interaction force; contact-less reaching and contact-based assisting motions. We used the humanoid robot Dry-AIREC, which features the capability to adjust joint impedance dynamically. In the experiment, the repositioning assistance from the supine position to the sitting position was conducted by Dry-AIREC. The trained model, utilizing the proposed architecture, successfully guided the robot's hand to the back of the mannequin without excessive contact force on the mannequin and provided adequate support and appropriate contact for postural adjustment.
Analyzing Deep Learning Based Brain Tumor Segmentation with Missing MRI Modalities
Aug 06, 2022



This technical report presents a comparative analysis of existing deep learning (DL) based approaches for brain tumor segmentation with missing MRI modalities. Approaches evaluated include the Adversarial Co-training Network (ACN) and a combination of mmGAN and DeepMedic. A more stable and easy-to-use version of mmGAN is also open-sourced at a GitHub repository. Using the BraTS2018 dataset, this work demonstrates that the state-of-the-art ACN performs better especially when T1c is missing. While a simple combination of mmGAN and DeepMedic also shows strong potentials when only one MRI modality is missing. Additionally, this work initiated discussions with future research directions for brain tumor segmentation with missing MRI modalities.