 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Circulated in 2024
Mar 05, 2025



In the age of increasingly realistic generative AI, robust deepfake detection is essential for mitigating fraud and disinformation. While many deepfake detectors report high accuracy on academic datasets, we show that these academic benchmarks are out of date and not representative of real-world deepfakes. We introduce Deepfake-Eval-2024, a new deepfake detection benchmark consisting of in-the-wild deepfakes collected from social media and deepfake detection platform users in 2024. Deepfake-Eval-2024 consists of 45 hours of videos, 56.5 hours of audio, and 1,975 images, encompassing the latest manipulation technologies. The benchmark contains diverse media content from 88 different websites in 52 different languages. We find that the performance of open-source state-of-the-art deepfake detection models drops precipitously when evaluated on Deepfake-Eval-2024, with AUC decreasing by 50\% for video, 48\% for audio, and 45\% for image models compared to previous benchmarks. We also evaluate commercial deepfake detection models and models finetuned on Deepfake-Eval-2024, and find that they have superior performance to off-the-shelf open-source models, but do not yet reach the accuracy of deepfake forensic analysts. The dataset is available at https://github.com/nuriachandra/Deepfake-Eval-2024.
The Tug-of-War Between Deepfake Generation and Detection
Jul 08, 2024
Multimodal generative models are rapidly evolving, leading to a surge in the generation of realistic video and audio that offers exciting possibilities but also serious risks. Deepfake videos, which can convincingly impersonate individuals, have particularly garnered attention due to their potential misuse in spreading misinformation and creating fraudulent content. This survey paper examines the dual landscape of deepfake video generation and detection, emphasizing the need for effective countermeasures against potential abuses. We provide a comprehensive overview of current deepfake generation techniques, including face swapping, reenactment, and audio-driven animation, which leverage cutting-edge technologies like generative adversarial networks and diffusion models to produce highly realistic fake videos. Additionally, we analyze various detection approaches designed to differentiate authentic from altered videos, from detecting visual artifacts to deploying advanced algorithms that pinpoint inconsistencies across video and audio signals. The effectiveness of these detection methods heavily relies on the diversity and quality of datasets used for training and evaluation. We discuss the evolution of deepfake datasets, highlighting the importance of robust, diverse, and frequently updated collections to enhance the detection accuracy and generalizability. As deepfakes become increasingly indistinguishable from authentic content, developing advanced detection techniques that can keep pace with generation technologies is crucial. We advocate for a proactive approach in the "tug-of-war" between deepfake creators and detectors, emphasizing the need for continuous research collaboration, standardization of evaluation metrics, and the creation of comprehensive benchmarks.
DistilDIRE: A Small, Fast, Cheap and Lightweight Diffusion Synthesized Deepfake Detection
Jun 02, 2024A dramatic influx of diffusion-generated images has marked recent years, posing unique challenges to current detection technologies. While the task of identifying these images falls under binary classification, a seemingly straightforward category, the computational load is significant when employing the "reconstruction then compare" technique. This approach, known as DIRE (Diffusion Reconstruction Error), not only identifies diffusion-generated images but also detects those produced by GANs, highlighting the technique's broad applicability. To address the computational challenges and improve efficiency, we propose distilling the knowledge embedded in diffusion models to develop rapid deepfake detection models. Our approach, aimed at creating a small, fast, cheap, and lightweight diffusion synthesized deepfake detector, maintains robust performance while significantly reducing operational demands. Maintaining performance, our experimental results indicate an inference speed 3.2 times faster than the existing DIRE framework. This advance not only enhances the practicality of deploying these systems in real-world settings but also paves the way for future research endeavors that seek to leverage diffusion model knowledge.
Let's Go Shopping -- Web-Scale Image-Text Dataset for Visual Concept Understanding
Jan 09, 2024Vision and vision-language applications of neural networks, such as image classification and captioning, rely on large-scale annotated datasets that require non-trivial data-collecting processes. This time-consuming endeavor hinders the emergence of large-scale datasets, limiting researchers and practitioners to a small number of choices. Therefore, we seek more efficient ways to collect and annotate images. Previous initiatives have gathered captions from HTML alt-texts and crawled social media postings, but these data sources suffer from noise, sparsity, or subjectivity. For this reason, we turn to commercial shopping websites whose data meet three criteria: cleanliness, informativeness, and fluency. We introduce the Let's Go Shopping (LGS) dataset, a large-scale public dataset with 15 million image-caption pairs from publicly available e-commerce websites. When compared with existing general-domain datasets, the LGS images focus on the foreground object and have less complex backgrounds. Our experiments on LGS show that the classifiers trained on existing benchmark datasets do not readily generalize to e-commerce data, while specific self-supervised visual feature extractors can better generalize. Furthermore, LGS's high-quality e-commerce-focused images and bimodal nature make it advantageous for vision-language bi-modal tasks: LGS enables image-captioning models to generate richer captions and helps text-to-image generation models achieve e-commerce style transfer.
Improving the Accuracy-Robustness Trade-off of Classifiers via Adaptive Smoothing
Jan 29, 2023



While it is shown in the literature that simultaneously accurate and robust classifiers exist for common datasets, previous methods that improve the adversarial robustness of classifiers often manifest an accuracy-robustness trade-off. We build upon recent advancements in data-driven ``locally biased smoothing'' to develop classifiers that treat benign and adversarial test data differently. Specifically, we tailor the smoothing operation to the usage of a robust neural network as the source of robustness. We then extend the smoothing procedure to the multi-class setting and adapt an adversarial input detector into a policy network. The policy adaptively adjusts the mixture of the robust base classifier and a standard network, where the standard network is optimized for clean accuracy and is not robust in general. We provide theoretical analyses to motivate the use of the adaptive smoothing procedure, certify the robustness of the smoothed classifier under realistic assumptions, and justify the introduction of the policy network. We use various attack methods, including AutoAttack and adaptive attack, to empirically verify that the smoothed model noticeably improves the accuracy-robustness trade-off. On the CIFAR-100 dataset, our method simultaneously achieves an 80.09\% clean accuracy and a 32.94\% AutoAttacked accuracy. The code that implements adaptive smoothing is available at https://github.com/Bai-YT/AdaptiveSmoothing.
GlideNet: Global, Local and Intrinsic based Dense Embedding NETwork for Multi-category Attributes Prediction
Mar 14, 2022



Attaching attributes (such as color, shape, state, action) to object categories is an important computer vision problem. Attribute prediction has seen exciting recent progress and is often formulated as a multi-label classification problem. Yet significant challenges remain in: 1) predicting diverse attributes over multiple categories, 2) modeling attributes-category dependency, 3) capturing both global and local scene context, and 4) predicting attributes of objects with low pixel-count. To address these issues, we propose a novel multi-category attribute prediction deep architecture named GlideNet, which contains three distinct feature extractors. A global feature extractor recognizes what objects are present in a scene, whereas a local one focuses on the area surrounding the object of interest. Meanwhile, an intrinsic feature extractor uses an extension of standard convolution dubbed Informed Convolution to retrieve features of objects with low pixel-count. GlideNet uses gating mechanisms with binary masks and its self-learned category embedding to combine the dense embeddings. Collectively, the Global-Local-Intrinsic blocks comprehend the scene's global context while attending to the characteristics of the local object of interest. Finally, using the combined features, an interpreter predicts the attributes, and the length of the output is determined by the category, thereby removing unnecessary attributes. GlideNet can achieve compelling results on two recent and challenging datasets -- VAW and CAR -- for large-scale attribute prediction. For instance, it obtains more than 5\% gain over state of the art in the mean recall (mR) metric. GlideNet's advantages are especially apparent when predicting attributes of objects with low pixel counts as well as attributes that demand global context understanding. Finally, we show that GlideNet excels in training starved real-world scenarios.
CAR -- Cityscapes Attributes Recognition A Multi-category Attributes Dataset for Autonomous Vehicles
Nov 16, 2021



Self-driving vehicles are the future of transportation. With current advancements in this field, the world is getting closer to safe roads with almost zero probability of having accidents and eliminating human errors. However, there is still plenty of research and development necessary to reach a level of robustness. One important aspect is to understand a scene fully including all details. As some characteristics (attributes) of objects in a scene (drivers' behavior for instance) could be imperative for correct decision making. However, current algorithms suffer from low-quality datasets with such rich attributes. Therefore, in this paper, we present a new dataset for attributes recognition -- Cityscapes Attributes Recognition (CAR). The new dataset extends the well-known dataset Cityscapes by adding an additional yet important annotation layer of attributes of objects in each image. Currently, we have annotated more than 32k instances of various categories (Vehicles, Pedestrians, etc.). The dataset has a structured and tailored taxonomy where each category has its own set of possible attributes. The tailored taxonomy focuses on attributes that is of most beneficent for developing better self-driving algorithms that depend on accurate computer vision and scene comprehension. We have also created an API for the dataset to ease the usage of CAR. The API can be accessed through https://github.com/kareem-metwaly/CAR-API.
Natural Adversarial Objects
Nov 07, 2021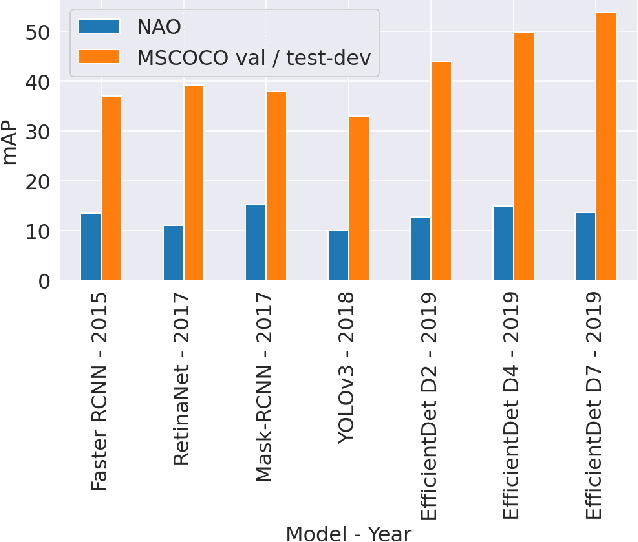


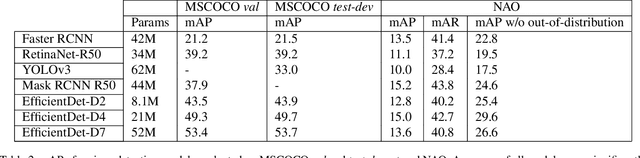
Although state-of-the-art object detection methods have shown compelling performance, models often are not robust to adversarial attacks and out-of-distribution data. We introduce a new dataset, Natural Adversarial Objects (NAO), to evaluate the robustness of object detection models. NAO contains 7,934 images and 9,943 objects that are unmodified and representative of real-world scenarios, but cause state-of-the-art detection models to misclassify with high confidence. The mean average precision (mAP) of EfficientDet-D7 drops 74.5% when evaluated on NAO compared to the standard MSCOCO validation set. Moreover, by comparing a variety of object detection architectures, we find that better performance on MSCOCO validation set does not necessarily translate to better performance on NAO, suggesting that robustness cannot be simply achieved by training a more accurate model. We further investigate why examples in NAO are difficult to detect and classify. Experiments of shuffling image patches reveal that models are overly sensitive to local texture. Additionally, using integrated gradients and background replacement, we find that the detection model is reliant on pixel information within the bounding box, and insensitive to the background context when predicting class labels. NAO can be downloaded at https://drive.google.com/drive/folders/15P8sOWoJku6SSEiHLEts86ORfytGezi8.
On The State of Data In Computer Vision: Human Annotations Remain Indispensable for Developing Deep Learning Models
Jul 31, 2021High-quality labeled datasets play a crucial role in fueling the development of machine learning (ML), and in particular the development of deep learning (DL). However, since the emergence of the ImageNet dataset and the AlexNet model in 2012, the size of new open-source labeled vision datasets has remained roughly constant. Consequently, only a minority of publications in the computer vision community tackle supervised learning on datasets that are orders of magnitude larger than Imagenet. In this paper, we survey computer vision research domains that study the effects of such large datasets on model performance across different vision tasks. We summarize the community's current understanding of those effects, and highlight some open questions related to training with massive datasets. In particular, we tackle: (a) The largest datasets currently used in computer vision research and the interesting takeaways from training on such datasets; (b) The effectiveness of pre-training on large datasets; (c) Recent advancements and hurdles facing synthetic datasets; (d) An overview of double descent and sample non-monotonicity phenomena; and finally, (e) A brief discussion of lifelong/continual learning and how it fares compared to learning from huge labeled datasets in an offline setting. Overall, our findings are that research on optimization for deep learning focuses on perfecting the training routine and thus making DL models less data hungry, while research on synthetic datasets aims to offset the cost of data labeling. However, for the time being, acquiring non-synthetic labeled data remains indispensable to boost performance.
Evaluating Deep Neural Networks Trained on Clinical Images in Dermatology with the Fitzpatrick 17k Dataset
Apr 20, 2021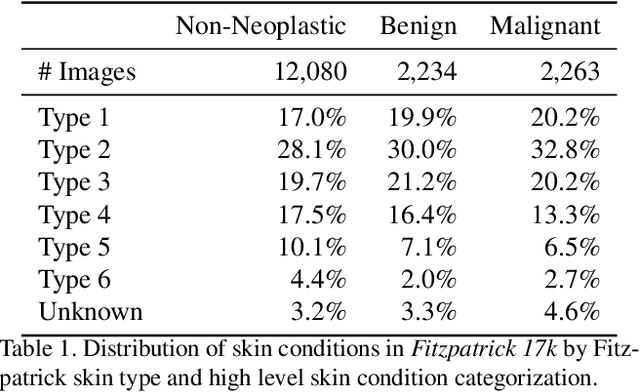
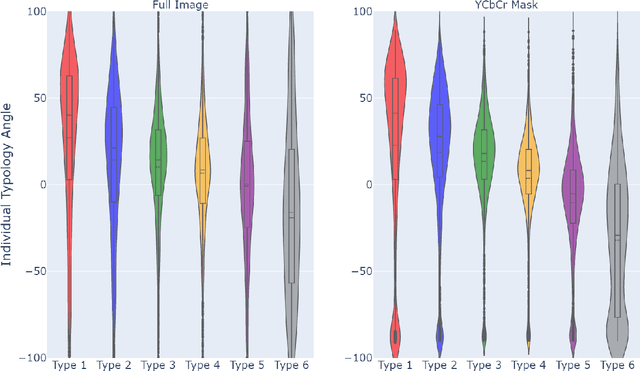

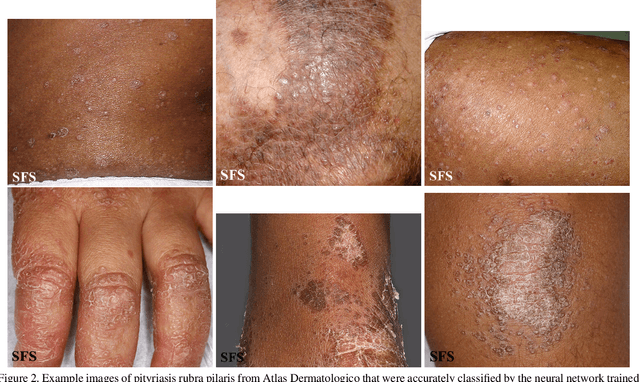
How does the accuracy of deep neural network models trained to classify clinical images of skin conditions vary across skin color? While recent studies demonstrate computer vision models can serve as a useful decision support tool in healthcare and provide dermatologist-level classification on a number of specific tasks, darker skin is underrepresented in the data. Most publicly available data sets do not include Fitzpatrick skin type labels. We annotate 16,577 clinical images sourced from two dermatology atlases with Fitzpatrick skin type labels and open-source these annotations. Based on these labels, we find that there are significantly more images of light skin types than dark skin types in this dataset. We train a deep neural network model to classify 114 skin conditions and find that the model is most accurate on skin types similar to those it was trained on. In addition, we evaluate how an algorithmic approach to identifying skin tones, individual typology angle, compares with Fitzpatrick skin type labels annotated by a team of human labelers.