 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Circulated in 2024
Mar 05, 2025



In the age of increasingly realistic generative AI, robust deepfake detection is essential for mitigating fraud and disinformation. While many deepfake detectors report high accuracy on academic datasets, we show that these academic benchmarks are out of date and not representative of real-world deepfakes. We introduce Deepfake-Eval-2024, a new deepfake detection benchmark consisting of in-the-wild deepfakes collected from social media and deepfake detection platform users in 2024. Deepfake-Eval-2024 consists of 45 hours of videos, 56.5 hours of audio, and 1,975 images, encompassing the latest manipulation technologies. The benchmark contains diverse media content from 88 different websites in 52 different languages. We find that the performance of open-source state-of-the-art deepfake detection models drops precipitously when evaluated on Deepfake-Eval-2024, with AUC decreasing by 50\% for video, 48\% for audio, and 45\% for image models compared to previous benchmarks. We also evaluate commercial deepfake detection models and models finetuned on Deepfake-Eval-2024, and find that they have superior performance to off-the-shelf open-source models, but do not yet reach the accuracy of deepfake forensic analysts. The dataset is available at https://github.com/nuriachandra/Deepfake-Eval-2024.
Pose Invariant Person Re-Identification using Robust Pose-transformation GAN
Apr 11, 2021
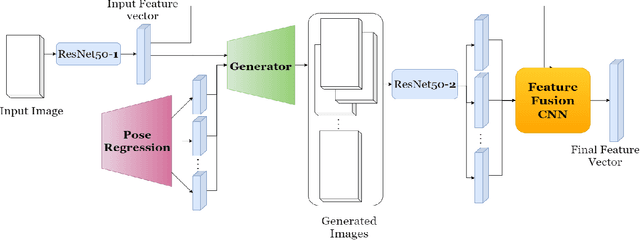


Person re-identification (re-ID) aims to retrieve a person's images from an image gallery, given a single instance of the person of interest. Despite several advancements, learning discriminative identity-sensitive and viewpoint invariant features for robust Person Re-identification is a major challenge owing to large pose variation of humans. This paper proposes a re-ID pipeline that utilizes the image generation capability of Generative Adversarial Networks combined with pose regression and feature fusion to achieve pose invariant feature learning. The objective is to model a given person under different viewpoints and large pose changes and extract the most discriminative features from all the appearances. The pose transformational GAN (pt-GAN) module is trained to generate a person's image in any given pose. In order to identify the most significant poses for discriminative feature extraction, a Pose Regression module is proposed. The given instance of the person is modelled in varying poses and these features are effectively combined through the Feature Fusion Network. The final re-ID model consisting of these 3 sub-blocks, alleviates the pose dependence in person re-ID and outperforms the state-of-the-art GAN based models for re-ID in 4 benchmark datasets. The proposed model is robust to occlusion, scale and illumination, thereby outperforms the state-of-the-art models in terms of improvement over baseline.
Domain Adaptive Egocentric Person Re-identification
Mar 08, 2021



Person re-identification (re-ID) in first-person (egocentric) vision is a fairly new and unexplored problem. With the increase of wearable video recording devices, egocentric data becomes readily available, and person re-identification has the potential to benefit greatly from this. However, there is a significant lack of large scale structured egocentric datasets for person re-identification, due to the poor video quality and lack of individuals in most of the recorded content. Although a lot of research has been done in person re-identification based on fixed surveillance cameras, these do not directly benefit egocentric re-ID. Machine learning models trained on the publicly available large scale re-ID datasets cannot be applied to egocentric re-ID due to the dataset bias problem. The proposed algorithm makes use of neural style transfer (NST) that incorporates a variant of Convolutional Neural Network (CNN) to utilize the benefits of both fixed camera vision and first-person vision. NST generates images having features from both egocentric datasets and fixed camera datasets, that are fed through a VGG-16 network trained on a fixed-camera dataset for feature extraction. These extracted features are then used to re-identify individuals. The fixed camera dataset Market-1501 and the first-person dataset EGO Re-ID are applied for this work and the results are on par with the present re-identification models in the egocentric domain.
A Robust Pose Transformational GAN for Pose Guided Person Image Synthesis
Jan 05, 2020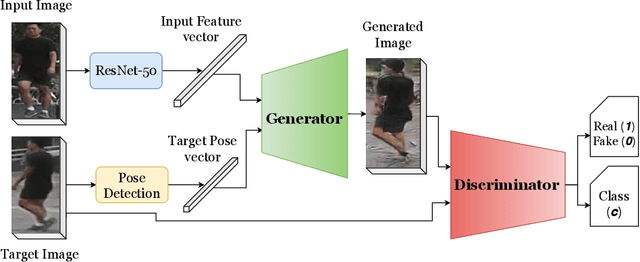
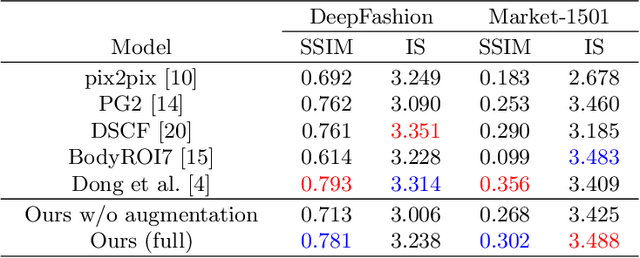

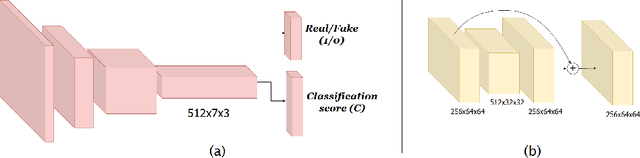
Generating photorealistic images of human subjects in any unseen pose have crucial applications in generating a complete appearance model of the subject. However, from a computer vision perspective, this task becomes significantly challenging due to the inability of modelling the data distribution conditioned on pose. Existing works use a complicated pose transformation model with various additional features such as foreground segmentation, human body parsing etc. to achieve robustness that leads to computational overhead. In this work, we propose a simple yet effective pose transformation GAN by utilizing the Residual Learning method without any additional feature learning to generate a given human image in any arbitrary pose. Using effective data augmentation techniques and cleverly tuning the model, we achieve robustness in terms of illumination, occlusion, distortion and scale. We present a detailed study, both qualitative and quantitative, to demonstrate the superiority of our model over the existing methods on two large datasets.
Stellar Cluster Detection using GMM with Deep Variational Autoencoder
Sep 05, 2018


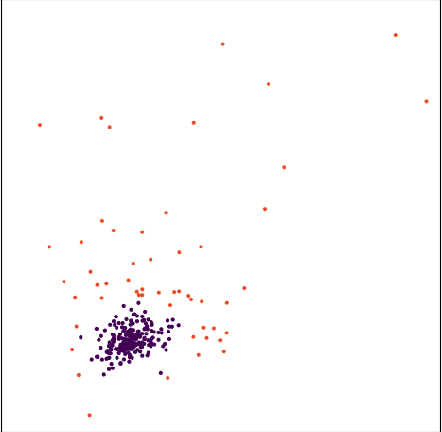
Detecting stellar clusters have always been an important research problem in Astronomy. Although images do not convey very detailed information in detecting stellar density enhancements, we attempt to understand if new machine learning techniques can reveal patterns that would assist in drawing better inferences from the available image data. This paper describes an unsupervised approach in detecting star clusters using Deep Variational Autoencoder combined with a Gaussian Mixture Model. We show that our method works significantly well in comparison with state-of-the-art detection algorithm in recognizing a variety of star clusters even in the presence of noise and distortion.