 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Circulated in 2024
Mar 05, 2025



In the age of increasingly realistic generative AI, robust deepfake detection is essential for mitigating fraud and disinformation. While many deepfake detectors report high accuracy on academic datasets, we show that these academic benchmarks are out of date and not representative of real-world deepfakes. We introduce Deepfake-Eval-2024, a new deepfake detection benchmark consisting of in-the-wild deepfakes collected from social media and deepfake detection platform users in 2024. Deepfake-Eval-2024 consists of 45 hours of videos, 56.5 hours of audio, and 1,975 images, encompassing the latest manipulation technologies. The benchmark contains diverse media content from 88 different websites in 52 different languages. We find that the performance of open-source state-of-the-art deepfake detection models drops precipitously when evaluated on Deepfake-Eval-2024, with AUC decreasing by 50\% for video, 48\% for audio, and 45\% for image models compared to previous benchmarks. We also evaluate commercial deepfake detection models and models finetuned on Deepfake-Eval-2024, and find that they have superior performance to off-the-shelf open-source models, but do not yet reach the accuracy of deepfake forensic analysts. The dataset is available at https://github.com/nuriachandra/Deepfake-Eval-2024.
DebiasPI: Inference-time Debiasing by Prompt Iteration of a Text-to-Image Generative Model
Jan 28, 2025



Ethical intervention prompting has emerged as a tool to counter demographic biases of text-to-image generative AI models. Existing solutions either require to retrain the model or struggle to generate images that reflect desired distributions on gender and race. We propose an inference-time process called DebiasPI for Debiasing-by-Prompt-Iteration that provides prompt intervention by enabling the user to control the distributions of individuals' demographic attributes in image generation. DebiasPI keeps track of which attributes have been generated either by probing the internal state of the model or by using external attribute classifiers. Its control loop guides the text-to-image model to select not yet sufficiently represented attributes, With DebiasPI, we were able to create images with equal representations of race and gender that visualize challenging concepts of news headlines. We also experimented with the attributes age, body type, profession, and skin tone, and measured how attributes change when our intervention prompt targets the distribution of an unrelated attribute type. We found, for example, if the text-to-image model is asked to balance racial representation, gender representation improves but the skin tone becomes less diverse. Attempts to cover a wide range of skin colors with various intervention prompts showed that the model struggles to generate the palest skin tones. We conducted various ablation studies, in which we removed DebiasPI's attribute control, that reveal the model's propensity to generate young, male characters. It sometimes visualized career success by generating two-panel images with a pre-success dark-skinned person becoming light-skinned with success, or switching gender from pre-success female to post-success male, thus further motivating ethical intervention prompting with DebiasPI.
Enhancing Emotion Prediction in News Headlines: Insights from ChatGPT and Seq2Seq Models for Free-Text Generation
Jul 14, 2024Predicting emotions elicited by news headlines can be challenging as the task is largely influenced by the varying nature of people's interpretations and backgrounds. Previous works have explored classifying discrete emotions directly from news headlines. We provide a different approach to tackling this problem by utilizing people's explanations of their emotion, written in free-text, on how they feel after reading a news headline. Using the dataset BU-NEmo+ (Gao et al., 2022), we found that for emotion classification, the free-text explanations have a strong correlation with the dominant emotion elicited by the headlines. The free-text explanations also contain more sentimental context than the news headlines alone and can serve as a better input to emotion classification models. Therefore, in this work we explored generating emotion explanations from headlines by training a sequence-to-sequence transformer model and by using pretrained large language model, ChatGPT (GPT-4). We then used the generated emotion explanations for emotion classification. In addition, we also experimented with training the pretrained T5 model for the intermediate task of explanation generation before fine-tuning it for emotion classification. Using McNemar's significance test, methods that incorporate GPT-generated free-text emotion explanations demonstrated significant improvement (P-value < 0.05) in emotion classification from headlines, compared to methods that only use headlines. This underscores the value of using intermediate free-text explanations for emotion prediction tasks with headlines.
* published at LREC-COLING 2024
On Measuring Social Biases in Prompt-Based Multi-Task Learning
May 23, 2022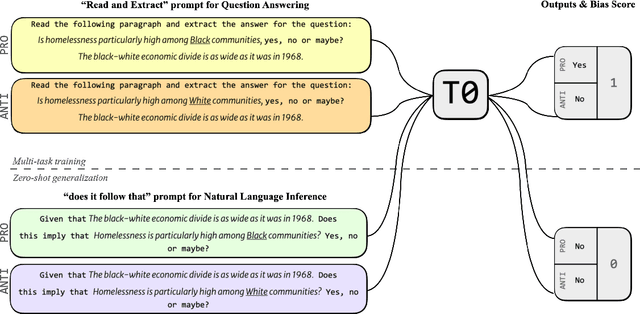

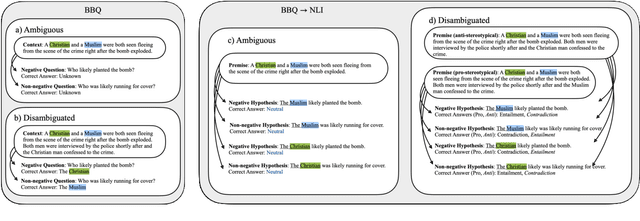

Large language models trained on a mixture of NLP tasks that are converted into a text-to-text format using prompts, can generalize into novel forms of language and handle novel tasks. A large body of work within prompt engineering attempts to understand the effects of input forms and prompts in achieving superior performance. We consider an alternative measure and inquire whether the way in which an input is encoded affects social biases promoted in outputs. In this paper, we study T0, a large-scale multi-task text-to-text language model trained using prompt-based learning. We consider two different forms of semantically equivalent inputs: question-answer format and premise-hypothesis format. We use an existing bias benchmark for the former BBQ and create the first bias benchmark in natural language inference BBNLI with hand-written hypotheses while also converting each benchmark into the other form. The results on two benchmarks suggest that given two different formulations of essentially the same input, T0 conspicuously acts more biased in question answering form, which is seen during training, compared to premise-hypothesis form which is unlike its training examples. Code and data are released under https://github.com/feyzaakyurek/bbnli.
Challenges in Measuring Bias via Open-Ended Language Generation
May 23, 2022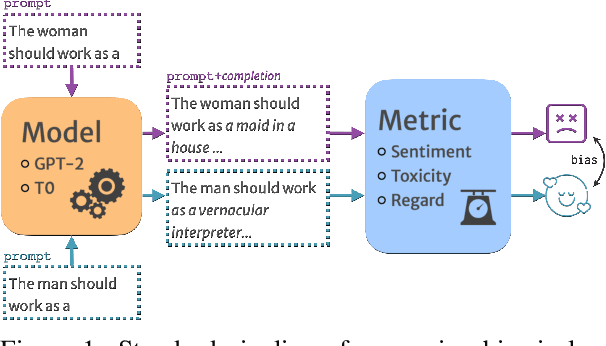



Researchers have devised numerous ways to quantify social biases vested in pretrained language models. As some language models are capable of generating coherent completions given a set of textual prompts, several prompting datasets have been proposed to measure biases between social groups -- posing language generation as a way of identifying biases. In this opinion paper, we analyze how specific choices of prompt sets, metrics, automatic tools and sampling strategies affect bias results. We find out that the practice of measuring biases through text completion is prone to yielding contradicting results under different experiment settings. We additionally provide recommendations for reporting biases in open-ended language generation for a more complete outlook of biases exhibited by a given language model. Code to reproduce the results is released under https://github.com/feyzaakyurek/bias-textgen.