 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverestimation in LLM Evaluation: A Controlled Large-Scale Study on Data Contamination's Impact on Machine Translation
Jan 30, 2025



Data contamination -- the accidental consumption of evaluation examples within the pre-training data -- can undermine the validity of evaluation benchmarks. In this paper, we present a rigorous analysis of the effects of contamination on language models at 1B and 8B scales on the machine translation task. Starting from a carefully decontaminated train-test split, we systematically introduce contamination at various stages, scales, and data formats to isolate its effect and measure its impact on performance metrics. Our experiments reveal that contamination with both source and target substantially inflates BLEU scores, and this inflation is 2.5 times larger (up to 30 BLEU points) for 8B compared to 1B models. In contrast, source-only and target-only contamination generally produce smaller, less consistent over-estimations. Finally, we study how the temporal distribution and frequency of contaminated samples influence performance over-estimation across languages with varying degrees of data resources.
Evaluation data contamination in LLMs: how do we measure it and (when) does it matter?
Nov 06, 2024
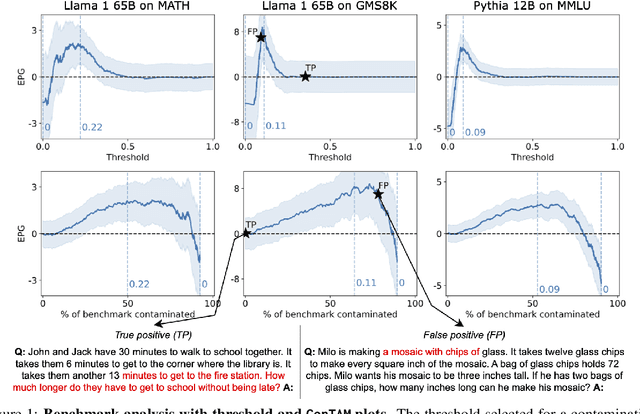
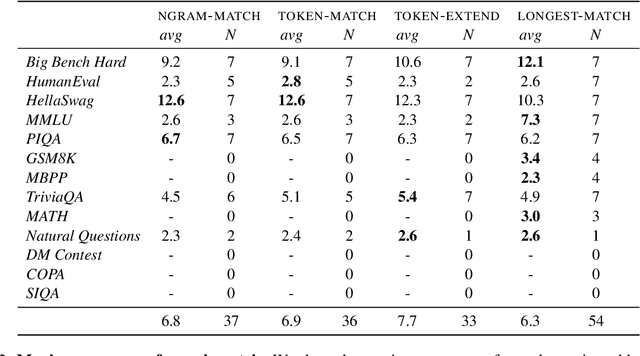
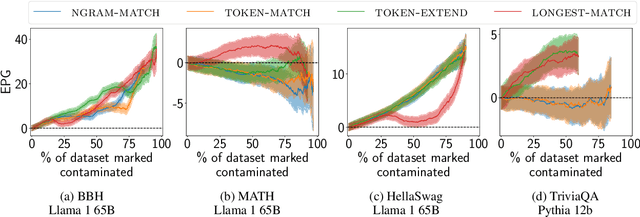
Hampering the interpretation of benchmark scores, evaluation data contamination has become a growing concern in the evaluation of LLMs, and an active area of research studies its effects. While evaluation data contamination is easily understood intuitively, it is surprisingly difficult to define precisely which samples should be considered contaminated and, consequently, how it impacts benchmark scores. We propose that these questions should be addressed together and that contamination metrics can be assessed based on whether models benefit from the examples they mark contaminated. We propose a novel analysis method called ConTAM, and show with a large scale survey of existing and novel n-gram based contamination metrics across 13 benchmarks and 7 models from 2 different families that ConTAM can be used to better understand evaluation data contamination and its effects. We find that contamination may have a much larger effect than reported in recent LLM releases and benefits models differently at different scales. We also find that considering only the longest contaminated substring provides a better signal than considering a union of all contaminated substrings, and that doing model and benchmark specific threshold analysis greatly increases the specificity of the results. Lastly, we investigate the impact of hyperparameter choices, finding that, among other things, both using larger values of n and disregarding matches that are infrequent in the pre-training data lead to many false negatives. With ConTAM, we provide a method to empirically ground evaluation data contamination metrics in downstream effects. With our exploration, we shed light on how evaluation data contamination can impact LLMs and provide insight into the considerations important when doing contamination analysis. We end our paper by discussing these in more detail and providing concrete suggestions for future work.
On Measuring Social Biases in Prompt-Based Multi-Task Learning
May 23, 2022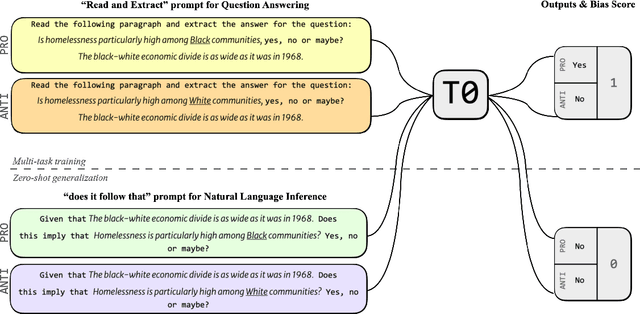

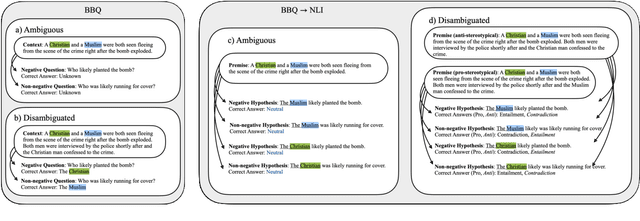

Large language models trained on a mixture of NLP tasks that are converted into a text-to-text format using prompts, can generalize into novel forms of language and handle novel tasks. A large body of work within prompt engineering attempts to understand the effects of input forms and prompts in achieving superior performance. We consider an alternative measure and inquire whether the way in which an input is encoded affects social biases promoted in outputs. In this paper, we study T0, a large-scale multi-task text-to-text language model trained using prompt-based learning. We consider two different forms of semantically equivalent inputs: question-answer format and premise-hypothesis format. We use an existing bias benchmark for the former BBQ and create the first bias benchmark in natural language inference BBNLI with hand-written hypotheses while also converting each benchmark into the other form. The results on two benchmarks suggest that given two different formulations of essentially the same input, T0 conspicuously acts more biased in question answering form, which is seen during training, compared to premise-hypothesis form which is unlike its training examples. Code and data are released under https://github.com/feyzaakyurek/bbnli.
Challenges in Measuring Bias via Open-Ended Language Generation
May 23, 2022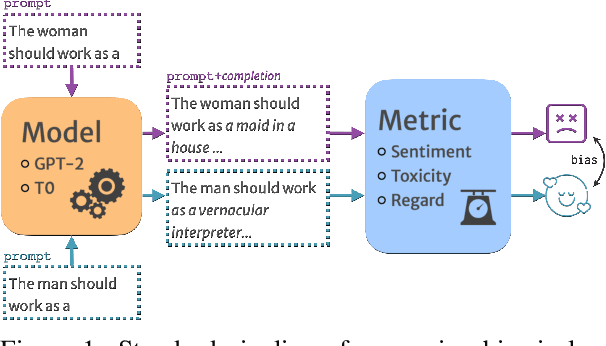



Researchers have devised numerous ways to quantify social biases vested in pretrained language models. As some language models are capable of generating coherent completions given a set of textual prompts, several prompting datasets have been proposed to measure biases between social groups -- posing language generation as a way of identifying biases. In this opinion paper, we analyze how specific choices of prompt sets, metrics, automatic tools and sampling strategies affect bias results. We find out that the practice of measuring biases through text completion is prone to yielding contradicting results under different experiment settings. We additionally provide recommendations for reporting biases in open-ended language generation for a more complete outlook of biases exhibited by a given language model. Code to reproduce the results is released under https://github.com/feyzaakyurek/bias-textgen.
Better Quality Estimation for Low Resource Corpus Mining
Mar 15, 2022


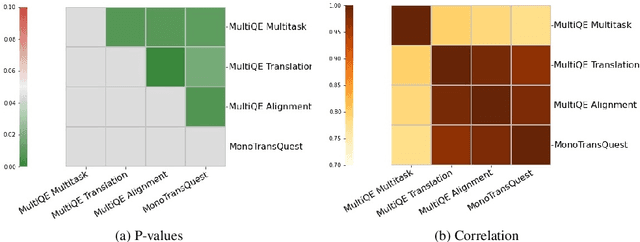
Quality Estimation (QE) models have the potential to change how we evaluate and maybe even train machine translation models. However, these models still lack the robustness to achieve general adoption. We show that State-of-the-art QE models, when tested in a Parallel Corpus Mining (PCM) setting, perform unexpectedly bad due to a lack of robustness to out-of-domain examples. We propose a combination of multitask training, data augmentation and contrastive learning to achieve better and more robust QE performance. We show that our method improves QE performance significantly in the MLQE challenge and the robustness of QE models when tested in the Parallel Corpus Mining setup. We increase the accuracy in PCM by more than 0.80, making it on par with state-of-the-art PCM methods that use millions of sentence pairs to train their models. In comparison, we use a thousand times less data, 7K parallel sentences in total, and propose a novel low resource PCM method.
NUBIA: NeUral Based Interchangeability Assessor for Text Generation
May 01, 2020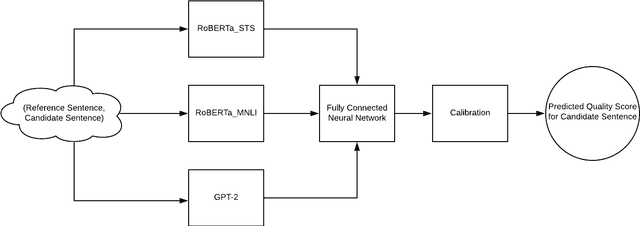


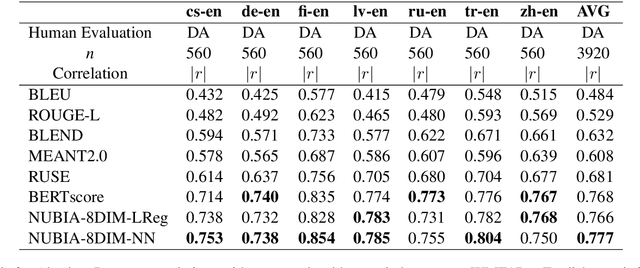
We present NUBIA, a methodology to build automatic evaluation metrics for text generation using only machine learning models as core components. A typical NUBIA model is composed of three modules: a neural feature extractor, an aggregator and a calibrator. We demonstrate an implementation of NUBIA which outperforms metrics currently used to evaluate machine translation, summaries and slightly exceeds/matches state of the art metrics on correlation with human judgement on the WMT segment-level Direct Assessment task, sentence-level ranking and image captioning evaluation. The model implemented is modular, explainable and set to continuously improve over time.