 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation data contamination in LLMs: how do we measure it and (when) does it matter?
Paper and Code
Nov 06, 2024
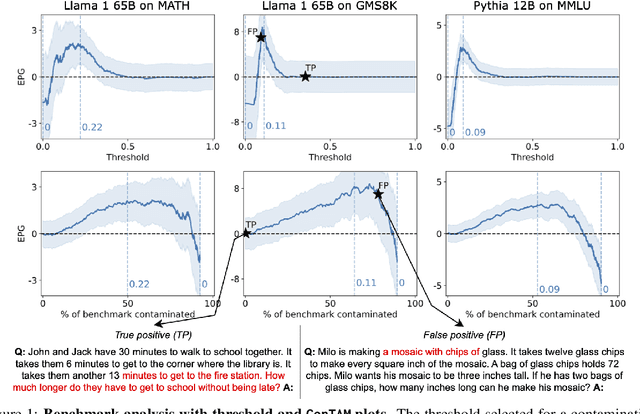
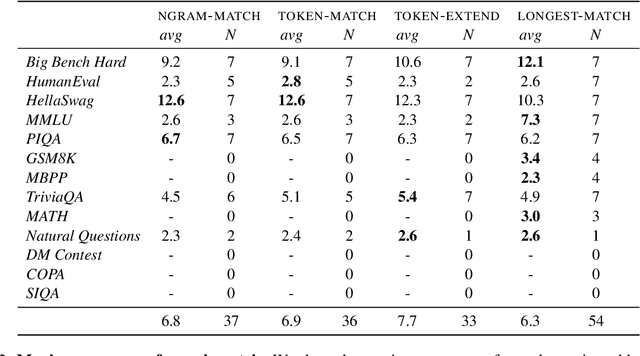
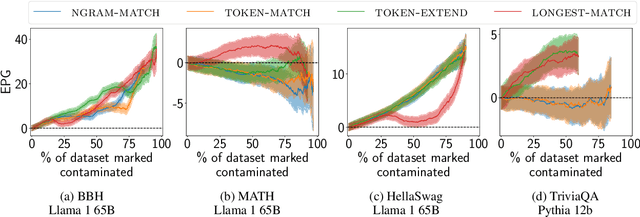
Hampering the interpretation of benchmark scores, evaluation data contamination has become a growing concern in the evaluation of LLMs, and an active area of research studies its effects. While evaluation data contamination is easily understood intuitively, it is surprisingly difficult to define precisely which samples should be considered contaminated and, consequently, how it impacts benchmark scores. We propose that these questions should be addressed together and that contamination metrics can be assessed based on whether models benefit from the examples they mark contaminated. We propose a novel analysis method called ConTAM, and show with a large scale survey of existing and novel n-gram based contamination metrics across 13 benchmarks and 7 models from 2 different families that ConTAM can be used to better understand evaluation data contamination and its effects. We find that contamination may have a much larger effect than reported in recent LLM releases and benefits models differently at different scales. We also find that considering only the longest contaminated substring provides a better signal than considering a union of all contaminated substrings, and that doing model and benchmark specific threshold analysis greatly increases the specificity of the results. Lastly, we investigate the impact of hyperparameter choices, finding that, among other things, both using larger values of n and disregarding matches that are infrequent in the pre-training data lead to many false negatives. With ConTAM, we provide a method to empirically ground evaluation data contamination metrics in downstream effects. With our exploration, we shed light on how evaluation data contamination can impact LLMs and provide insight into the considerations important when doing contamination analysis. We end our paper by discussing these in more detail and providing concrete suggestions for future work.