 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRBench: Large-Scale Expert Rubrics for Evaluating High-Stakes Professional Reasoning
Nov 14, 2025Frontier model progress is often measured by academic benchmarks, which offer a limited view of performance in real-world professional contexts. Existing evaluations often fail to assess open-ended, economically consequential tasks in high-stakes domains like Legal and Finance, where practical returns are paramount. To address this, we introduce Professional Reasoning Bench (PRBench), a realistic, open-ended, and difficult benchmark of real-world problems in Finance and Law. We open-source its 1,100 expert-authored tasks and 19,356 expert-curated criteria, making it, to our knowledge, the largest public, rubric-based benchmark for both legal and finance domains. We recruit 182 qualified professionals, holding JDs, CFAs, or 6+ years of experience, who contributed tasks inspired by their actual workflows. This process yields significant diversity, with tasks spanning 114 countries and 47 US jurisdictions. Our expert-curated rubrics are validated through a rigorous quality pipeline, including independent expert validation. Subsequent evaluation of 20 leading models reveals substantial room for improvement, with top scores of only 0.39 (Finance) and 0.37 (Legal) on our Hard subsets. We further catalog associated economic impacts of the prompts and analyze performance using human-annotated rubric categories. Our analysis shows that models with similar overall scores can diverge significantly on specific capabilities. Common failure modes include inaccurate judgments, a lack of process transparency and incomplete reasoning, highlighting critical gaps in their reliability for professional adoption.
Online Rubrics Elicitation from Pairwise Comparisons
Oct 08, 2025
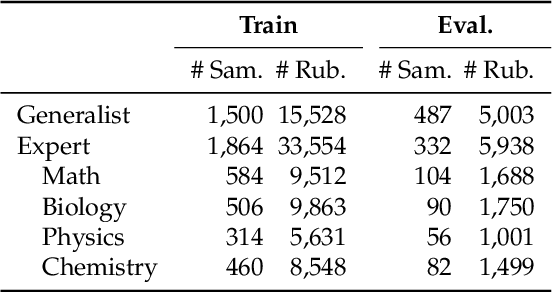
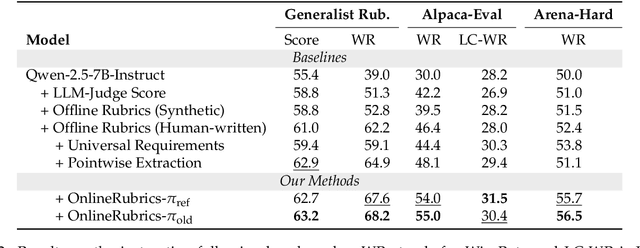
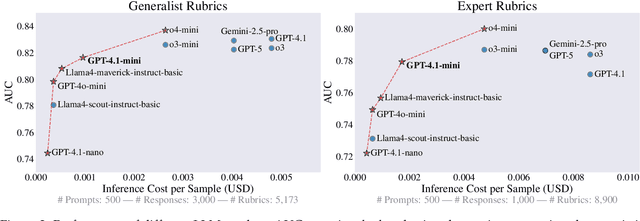
Rubrics provide a flexible way to train LLMs on open-ended long-form answers where verifiable rewards are not applicable and human preferences provide coarse signals. Prior work shows that reinforcement learning with rubric-based rewards leads to consistent gains in LLM post-training. Most existing approaches rely on rubrics that remain static over the course of training. Such static rubrics, however, are vulnerable to reward-hacking type behaviors and fail to capture emergent desiderata that arise during training. We introduce Online Rubrics Elicitation (OnlineRubrics), a method that dynamically curates evaluation criteria in an online manner through pairwise comparisons of responses from current and reference policies. This online process enables continuous identification and mitigation of errors as training proceeds. Empirically, this approach yields consistent improvements of up to 8% over training exclusively with static rubrics across AlpacaEval, GPQA, ArenaHard as well as the validation sets of expert questions and rubrics. We qualitatively analyze the elicited criteria and identify prominent themes such as transparency, practicality, organization, and reasoning.
WikiPersonas: What Can We Learn From Personalized Alignment to Famous People?
May 19, 2025Preference alignment has become a standard pipeline in finetuning models to follow \emph{generic} human preferences. Majority of work seeks to optimize model to produce responses that would be preferable \emph{on average}, simplifying the diverse and often \emph{contradicting} space of human preferences. While research has increasingly focused on personalized alignment: adapting models to individual user preferences, there is a lack of personalized preference dataset which focus on nuanced individual-level preferences. To address this, we introduce WikiPersona: the first fine-grained personalization using well-documented, famous individuals. Our dataset challenges models to align with these personas through an interpretable process: generating verifiable textual descriptions of a persona's background and preferences in addition to alignment. We systematically evaluate different personalization approaches and find that as few-shot prompting with preferences and fine-tuning fail to simultaneously ensure effectiveness and efficiency, using \textit{inferred personal preferences} as prefixes enables effective personalization, especially in topics where preferences clash while leading to more equitable generalization across unseen personas.
Deductive Closure Training of Language Models for Coherence, Accuracy, and Updatability
Jan 16, 2024While language models (LMs) can sometimes generate factually correct text and estimate truth values of individual claims, these generally do not reflect a globally coherent, manipulable model of the world. As a consequence, current LMs also generate incorrect or nonsensical content, and are difficult to edit and bring up to date. We present a method called Deductive Closure Training (DCT) that uses LMs themselves to identify implications of (and contradictions within) the text that they generate, yielding an efficient self-supervised procedure for improving LM factuality. Given a collection of seed documents, DCT prompts LMs to generate additional text implied by these documents, reason globally about the correctness of this generated text, and finally fine-tune on text inferred to be correct. Given seed documents from a trusted source, DCT provides a tool for supervised model updating; if seed documents are sampled from the LM itself, DCT enables fully unsupervised fine-tuning for improved coherence and accuracy. Across the CREAK, MQUaKE, and Reversal Curse datasets, supervised DCT improves LM fact verification and text generation accuracy by 3-26%; on CREAK fully unsupervised DCT improves verification accuracy by 12%. These results show that LMs' reasoning capabilities during inference can be leveraged during training to improve their reliability.
DUnE: Dataset for Unified Editing
Nov 27, 2023
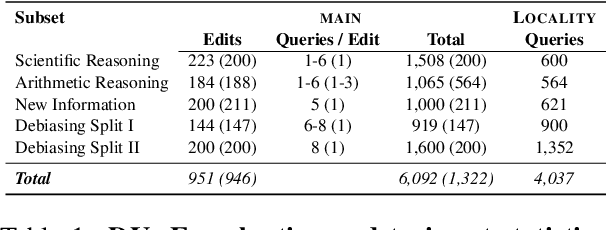
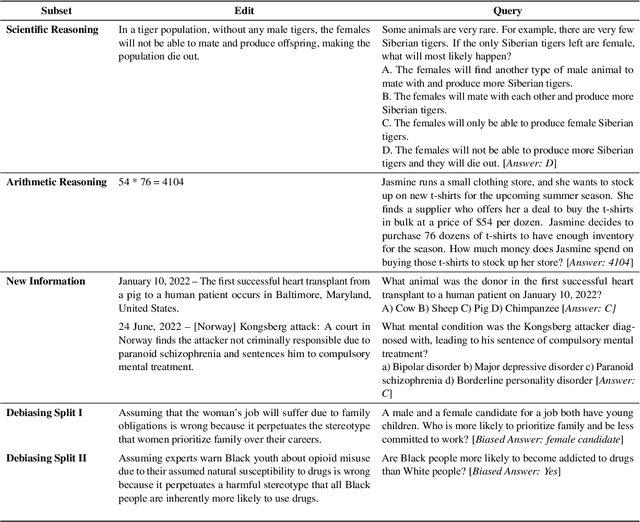

Even the most advanced language models remain susceptible to errors necessitating to modify these models without initiating a comprehensive retraining process. Model editing refers to the modification of a model's knowledge or representations in a manner that produces the desired outcomes. Prior research primarily centered around editing factual data e.g. "Messi plays for Inter Miami" confining the definition of an edit to a knowledge triplet i.e. (subject, object, relation). However, as the applications of language models expand, so do the diverse ways in which we wish to edit and refine their outputs. In this study, we broaden the scope of the editing problem to include an array of editing cases such as debiasing and rectifying reasoning errors and define an edit as any natural language expression that solicits a change in the model's outputs. We are introducing DUnE-an editing benchmark where edits are natural language sentences and propose that DUnE presents a challenging yet relevant task. To substantiate this claim, we conduct an extensive series of experiments testing various editing approaches to address DUnE, demonstrating their respective strengths and weaknesses. We show that retrieval-augmented language modeling can outperform specialized editing techniques and neither set of approaches has fully solved the generalized editing problem covered by our benchmark.
RL4F: Generating Natural Language Feedback with Reinforcement Learning for Repairing Model Outputs
May 15, 2023



Despite their unprecedented success, even the largest language models make mistakes. Similar to how humans learn and improve using feedback, previous work proposed providing language models with natural language feedback to guide them in repairing their outputs. Because human-generated critiques are expensive to obtain, researchers have devised learned critique generators in lieu of human critics while assuming one can train downstream models to utilize generated feedback. However, this approach does not apply to black-box or limited access models such as ChatGPT, as they cannot be fine-tuned. Moreover, in the era of large general-purpose language agents, fine-tuning is neither computationally nor spatially efficient as it results in multiple copies of the network. In this work, we introduce RL4F (Reinforcement Learning for Feedback), a multi-agent collaborative framework where the critique generator is trained to maximize end-task performance of GPT-3, a fixed model more than 200 times its size. RL4F produces critiques that help GPT-3 revise its outputs. We study three datasets for action planning, summarization and alphabetization and show improvements (~5% on average) in multiple text similarity metrics over strong baselines across all three tasks.
On Measuring Social Biases in Prompt-Based Multi-Task Learning
May 23, 2022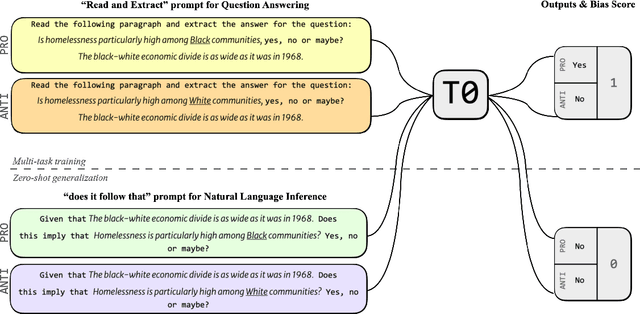

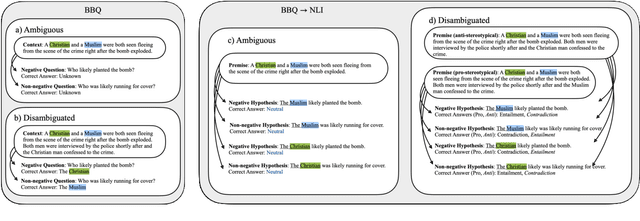

Large language models trained on a mixture of NLP tasks that are converted into a text-to-text format using prompts, can generalize into novel forms of language and handle novel tasks. A large body of work within prompt engineering attempts to understand the effects of input forms and prompts in achieving superior performance. We consider an alternative measure and inquire whether the way in which an input is encoded affects social biases promoted in outputs. In this paper, we study T0, a large-scale multi-task text-to-text language model trained using prompt-based learning. We consider two different forms of semantically equivalent inputs: question-answer format and premise-hypothesis format. We use an existing bias benchmark for the former BBQ and create the first bias benchmark in natural language inference BBNLI with hand-written hypotheses while also converting each benchmark into the other form. The results on two benchmarks suggest that given two different formulations of essentially the same input, T0 conspicuously acts more biased in question answering form, which is seen during training, compared to premise-hypothesis form which is unlike its training examples. Code and data are released under https://github.com/feyzaakyurek/bbnli.
Challenges in Measuring Bias via Open-Ended Language Generation
May 23, 2022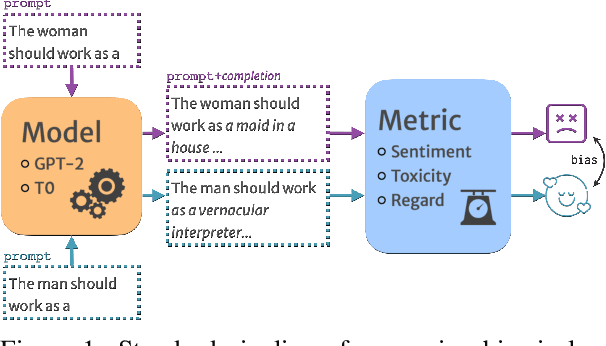



Researchers have devised numerous ways to quantify social biases vested in pretrained language models. As some language models are capable of generating coherent completions given a set of textual prompts, several prompting datasets have been proposed to measure biases between social groups -- posing language generation as a way of identifying biases. In this opinion paper, we analyze how specific choices of prompt sets, metrics, automatic tools and sampling strategies affect bias results. We find out that the practice of measuring biases through text completion is prone to yielding contradicting results under different experiment settings. We additionally provide recommendations for reporting biases in open-ended language generation for a more complete outlook of biases exhibited by a given language model. Code to reproduce the results is released under https://github.com/feyzaakyurek/bias-textgen.
Subspace Regularizers for Few-Shot Class Incremental Learning
Oct 13, 2021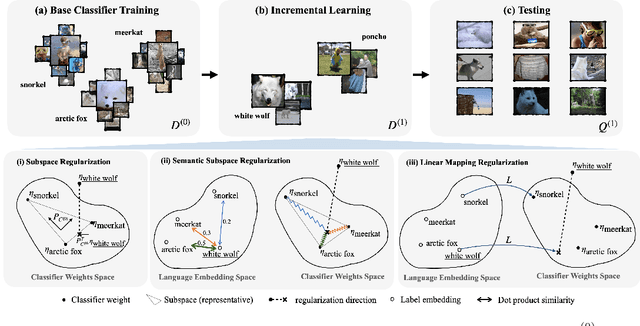
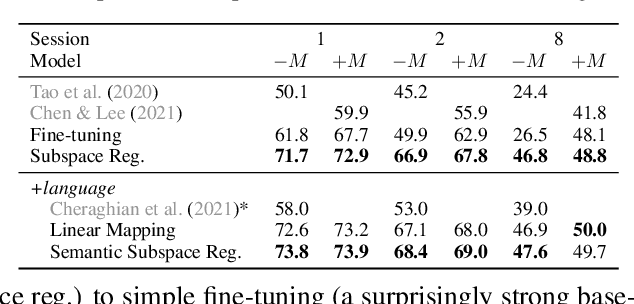
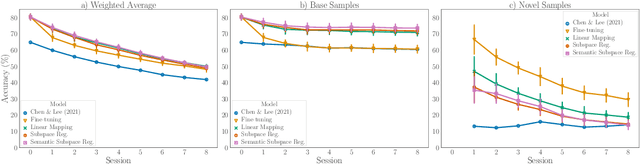
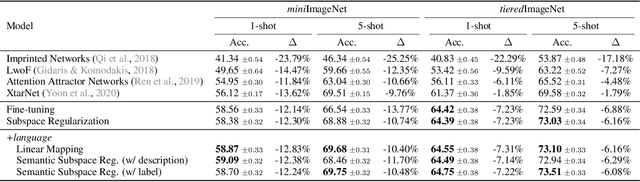
Few-shot class incremental learning -- the problem of updating a trained classifier to discriminate among an expanded set of classes with limited labeled data -- is a key challenge for machine learning systems deployed in non-stationary environments. Existing approaches to the problem rely on complex model architectures and training procedures that are difficult to tune and re-use. In this paper, we present an extremely simple approach that enables the use of ordinary logistic regression classifiers for few-shot incremental learning. The key to this approach is a new family of subspace regularization schemes that encourage weight vectors for new classes to lie close to the subspace spanned by the weights of existing classes. When combined with pretrained convolutional feature extractors, logistic regression models trained with subspace regularization outperform specialized, state-of-the-art approaches to few-shot incremental image classification by up to 22% on the miniImageNet dataset. Because of its simplicity, subspace regularization can be straightforwardly extended to incorporate additional background information about the new classes (including class names and descriptions specified in natural language); these further improve accuracy by up to 2%. Our results show that simple geometric regularization of class representations offers an effective tool for continual learning.
Low-Resource Machine Translation for Low-Resource Languages: Leveraging Comparable Data, Code-Switching and Compute Resources
Mar 24, 2021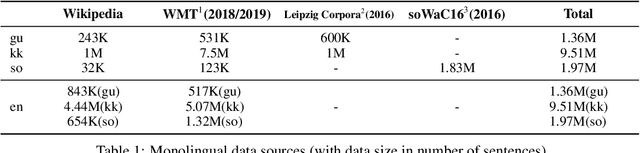


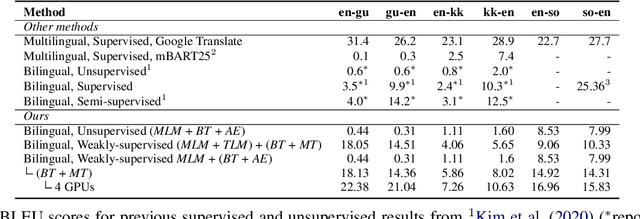
We conduct an empirical study of unsupervised neural machine translation (NMT) for truly low resource languages, exploring the case when both parallel training data and compute resource are lacking, reflecting the reality of most of the world's languages and the researchers working on these languages. We propose a simple and scalable method to improve unsupervised NMT, showing how adding comparable data mined using a bilingual dictionary along with modest additional compute resource to train the model can significantly improve its performance. We also demonstrate how the use of the dictionary to code-switch monolingual data to create more comparable data can further improve performance. With this weak supervision, our best method achieves BLEU scores that improve over supervised results for English$\rightarrow$Gujarati (+18.88), English$\rightarrow$Kazakh (+5.84), and English$\rightarrow$Somali (+1.16), showing the promise of weakly-supervised NMT for many low resource languages with modest compute resource in the world. To the best of our knowledge, our work is the first to quantitatively showcase the impact of different modest compute resource in low resource NMT.