 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Measuring Social Biases in Prompt-Based Multi-Task Learning
May 23, 2022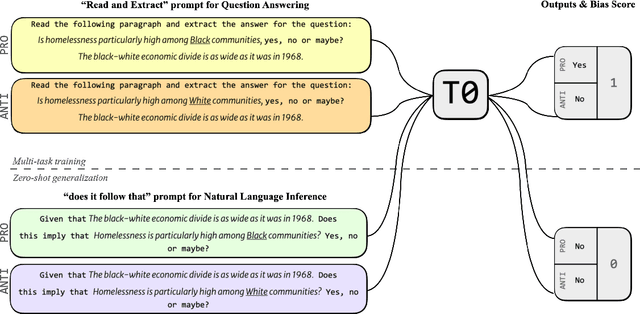

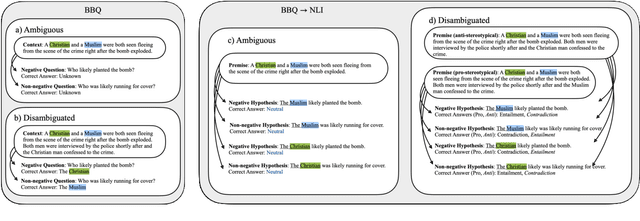

Large language models trained on a mixture of NLP tasks that are converted into a text-to-text format using prompts, can generalize into novel forms of language and handle novel tasks. A large body of work within prompt engineering attempts to understand the effects of input forms and prompts in achieving superior performance. We consider an alternative measure and inquire whether the way in which an input is encoded affects social biases promoted in outputs. In this paper, we study T0, a large-scale multi-task text-to-text language model trained using prompt-based learning. We consider two different forms of semantically equivalent inputs: question-answer format and premise-hypothesis format. We use an existing bias benchmark for the former BBQ and create the first bias benchmark in natural language inference BBNLI with hand-written hypotheses while also converting each benchmark into the other form. The results on two benchmarks suggest that given two different formulations of essentially the same input, T0 conspicuously acts more biased in question answering form, which is seen during training, compared to premise-hypothesis form which is unlike its training examples. Code and data are released under https://github.com/feyzaakyurek/bbnli.