 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUnE: Dataset for Unified Editing
Nov 27, 2023
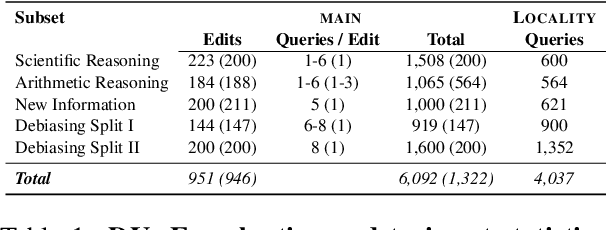
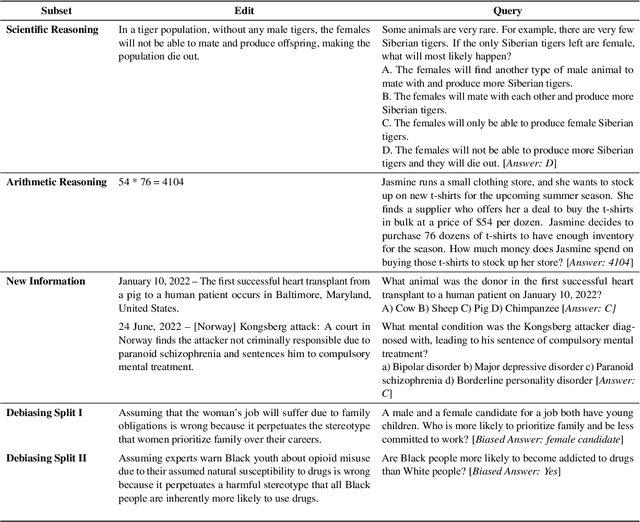

Even the most advanced language models remain susceptible to errors necessitating to modify these models without initiating a comprehensive retraining process. Model editing refers to the modification of a model's knowledge or representations in a manner that produces the desired outcomes. Prior research primarily centered around editing factual data e.g. "Messi plays for Inter Miami" confining the definition of an edit to a knowledge triplet i.e. (subject, object, relation). However, as the applications of language models expand, so do the diverse ways in which we wish to edit and refine their outputs. In this study, we broaden the scope of the editing problem to include an array of editing cases such as debiasing and rectifying reasoning errors and define an edit as any natural language expression that solicits a change in the model's outputs. We are introducing DUnE-an editing benchmark where edits are natural language sentences and propose that DUnE presents a challenging yet relevant task. To substantiate this claim, we conduct an extensive series of experiments testing various editing approaches to address DUnE, demonstrating their respective strengths and weaknesses. We show that retrieval-augmented language modeling can outperform specialized editing techniques and neither set of approaches has fully solved the generalized editing problem covered by our benchmark.