 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR3: Robust Rubric-Agnostic Reward Models
May 19, 2025Reward models are essential for aligning language model outputs with human preferences, yet existing approaches often lack both controllability and interpretability. These models are typically optimized for narrow objectives, limiting their generalizability to broader downstream tasks. Moreover, their scalar outputs are difficult to interpret without contextual reasoning. To address these limitations, we introduce R3, a novel reward modeling framework that is rubric-agnostic, generalizable across evaluation dimensions, and provides interpretable, reasoned score assignments. R3 enables more transparent and flexible evaluation of language models, supporting robust alignment with diverse human values and use cases. Our models, data, and code are available as open source at https://github.com/rubricreward/r3
MetaMetrics-MT: Tuning Meta-Metrics for Machine Translation via Human Preference Calibration
Nov 01, 2024We present MetaMetrics-MT, an innovative metric designed to evaluate machine translation (MT) tasks by aligning closely with human preferences through Bayesian optimization with Gaussian Processes. MetaMetrics-MT enhances existing MT metrics by optimizing their correlation with human judgments. Our experiments on the WMT24 metric shared task dataset demonstrate that MetaMetrics-MT outperforms all existing baselines, setting a new benchmark for state-of-the-art performance in the reference-based setting. Furthermore, it achieves comparable results to leading metrics in the reference-free setting, offering greater efficiency.
Linguistics Theory Meets LLM: Code-Switched Text Generation via Equivalence Constrained Large Language Models
Oct 30, 2024Code-switching, the phenomenon of alternating between two or more languages in a single conversation, presents unique challenges for Natural Language Processing (NLP). Most existing research focuses on either syntactic constraints or neural generation, with few efforts to integrate linguistic theory with large language models (LLMs) for generating natural code-switched text. In this paper, we introduce EZSwitch, a novel framework that combines Equivalence Constraint Theory (ECT) with LLMs to produce linguistically valid and fluent code-switched text. We evaluate our method using both human judgments and automatic metrics, demonstrating a significant improvement in the quality of generated code-switching sentences compared to baseline LLMs. To address the lack of suitable evaluation metrics, we conduct a comprehensive correlation study of various automatic metrics against human scores, revealing that current metrics often fail to capture the nuanced fluency of code-switched text. Additionally, we create CSPref, a human preference dataset based on human ratings and analyze model performance across ``hard`` and ``easy`` examples. Our findings indicate that incorporating linguistic constraints into LLMs leads to more robust and human-aligned generation, paving the way for scalable code-switching text generation across diverse language pairs.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
MetaMetrics: Calibrating Metrics For Generation Tasks Using Human Preferences
Oct 03, 2024Understanding the quality of a performance evaluation metric is crucial for ensuring that model outputs align with human preferences. However, it remains unclear how well each metric captures the diverse aspects of these preferences, as metrics often excel in one particular area but not across all dimensions. To address this, it is essential to systematically calibrate metrics to specific aspects of human preference, catering to the unique characteristics of each aspect. We introduce MetaMetrics, a calibrated meta-metric designed to evaluate generation tasks across different modalities in a supervised manner. MetaMetrics optimizes the combination of existing metrics to enhance their alignment with human preferences. Our metric demonstrates flexibility and effectiveness in both language and vision downstream tasks, showing significant benefits across various multilingual and multi-domain scenarios. MetaMetrics aligns closely with human preferences and is highly extendable and easily integrable into any application. This makes MetaMetrics a powerful tool for improving the evaluation of generation tasks, ensuring that metrics are more representative of human judgment across diverse contexts.
Mitigating Translationese in Low-resource Languages: The Storyboard Approach
Jul 14, 2024Low-resource languages often face challenges in acquiring high-quality language data due to the reliance on translation-based methods, which can introduce the translationese effect. This phenomenon results in translated sentences that lack fluency and naturalness in the target language. In this paper, we propose a novel approach for data collection by leveraging storyboards to elicit more fluent and natural sentences. Our method involves presenting native speakers with visual stimuli in the form of storyboards and collecting their descriptions without direct exposure to the source text. We conducted a comprehensive evaluation comparing our storyboard-based approach with traditional text translation-based methods in terms of accuracy and fluency. Human annotators and quantitative metrics were used to assess translation quality. The results indicate a preference for text translation in terms of accuracy, while our method demonstrates worse accuracy but better fluency in the language focused.
* published at LREC-COLING 2024
DUnE: Dataset for Unified Editing
Nov 27, 2023
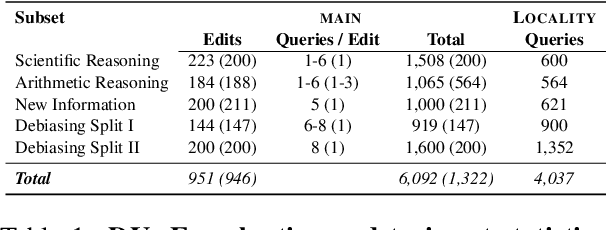
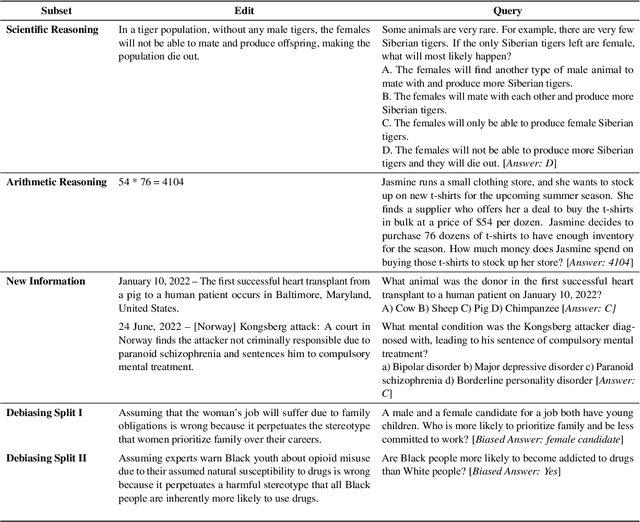

Even the most advanced language models remain susceptible to errors necessitating to modify these models without initiating a comprehensive retraining process. Model editing refers to the modification of a model's knowledge or representations in a manner that produces the desired outcomes. Prior research primarily centered around editing factual data e.g. "Messi plays for Inter Miami" confining the definition of an edit to a knowledge triplet i.e. (subject, object, relation). However, as the applications of language models expand, so do the diverse ways in which we wish to edit and refine their outputs. In this study, we broaden the scope of the editing problem to include an array of editing cases such as debiasing and rectifying reasoning errors and define an edit as any natural language expression that solicits a change in the model's outputs. We are introducing DUnE-an editing benchmark where edits are natural language sentences and propose that DUnE presents a challenging yet relevant task. To substantiate this claim, we conduct an extensive series of experiments testing various editing approaches to address DUnE, demonstrating their respective strengths and weaknesses. We show that retrieval-augmented language modeling can outperform specialized editing techniques and neither set of approaches has fully solved the generalized editing problem covered by our benchmark.
Low-Resource Machine Translation for Low-Resource Languages: Leveraging Comparable Data, Code-Switching and Compute Resources
Mar 24, 2021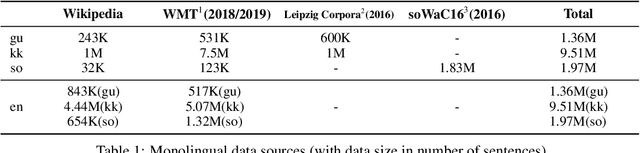


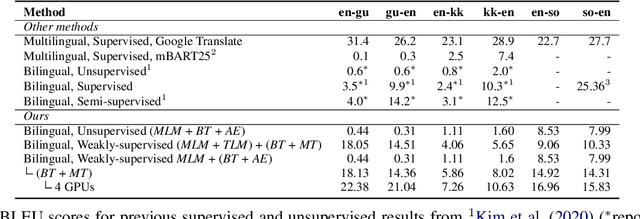
We conduct an empirical study of unsupervised neural machine translation (NMT) for truly low resource languages, exploring the case when both parallel training data and compute resource are lacking, reflecting the reality of most of the world's languages and the researchers working on these languages. We propose a simple and scalable method to improve unsupervised NMT, showing how adding comparable data mined using a bilingual dictionary along with modest additional compute resource to train the model can significantly improve its performance. We also demonstrate how the use of the dictionary to code-switch monolingual data to create more comparable data can further improve performance. With this weak supervision, our best method achieves BLEU scores that improve over supervised results for English$\rightarrow$Gujarati (+18.88), English$\rightarrow$Kazakh (+5.84), and English$\rightarrow$Somali (+1.16), showing the promise of weakly-supervised NMT for many low resource languages with modest compute resource in the world. To the best of our knowledge, our work is the first to quantitatively showcase the impact of different modest compute resource in low resource NMT.