 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Mitigating Translationese in Low-resource Languages: The Storyboard Approach
Jul 14, 2024Low-resource languages often face challenges in acquiring high-quality language data due to the reliance on translation-based methods, which can introduce the translationese effect. This phenomenon results in translated sentences that lack fluency and naturalness in the target language. In this paper, we propose a novel approach for data collection by leveraging storyboards to elicit more fluent and natural sentences. Our method involves presenting native speakers with visual stimuli in the form of storyboards and collecting their descriptions without direct exposure to the source text. We conducted a comprehensive evaluation comparing our storyboard-based approach with traditional text translation-based methods in terms of accuracy and fluency. Human annotators and quantitative metrics were used to assess translation quality. The results indicate a preference for text translation in terms of accuracy, while our method demonstrates worse accuracy but better fluency in the language focused.
* published at LREC-COLING 2024
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023



African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021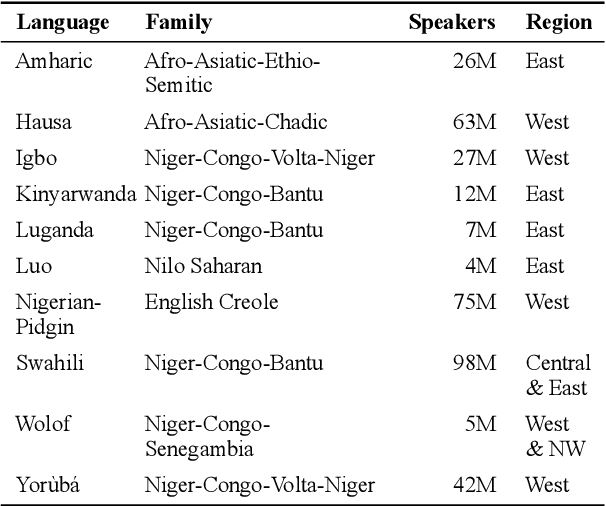

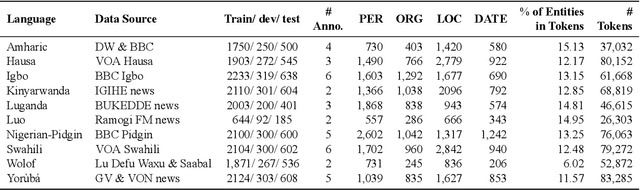
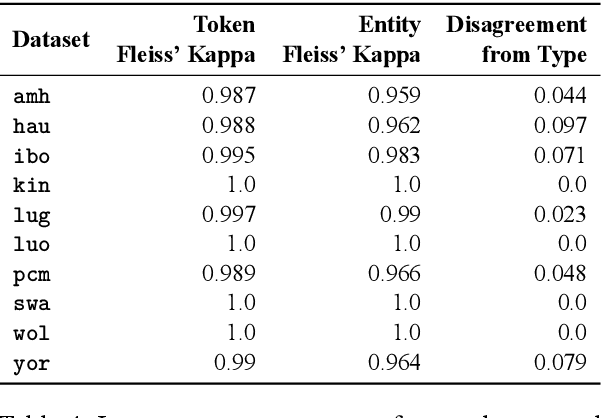
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.