 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Esethu Framework: Reimagining Sustainable Dataset Governance and Curation for Low-Resource Languages
Feb 21, 2025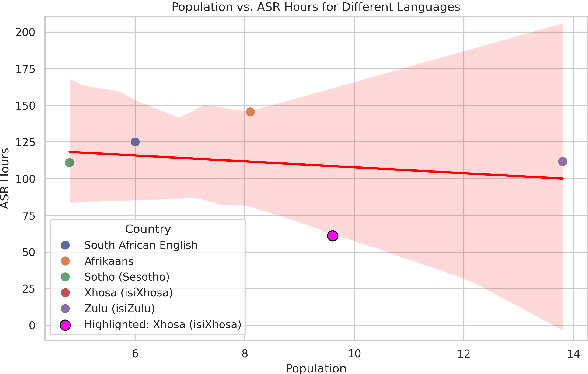


This paper presents the Esethu Framework, a sustainable data curation framework specifically designed to empower local communities and ensure equitable benefit-sharing from their linguistic resources. This framework is supported by the Esethu license, a novel community-centric data license. As a proof of concept, we introduce the Vuk'uzenzele isiXhosa Speech Dataset (ViXSD), an open-source corpus developed under the Esethu Framework and License. The dataset, containing read speech from native isiXhosa speakers enriched with demographic and linguistic metadata, demonstrates how community-driven licensing and curation principles can bridge resource gaps in automatic speech recognition (ASR) for African languages while safeguarding the interests of data creators. We describe the framework guiding dataset development, outline the Esethu license provisions, present the methodology for ViXSD, and present ASR experiments validating ViXSD's usability in building and refining voice-driven applications for isiXhosa.
InkubaLM: A small language model for low-resource African languages
Sep 03, 2024
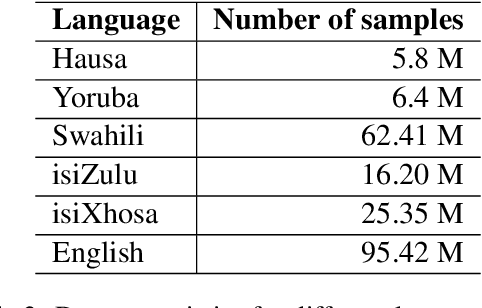
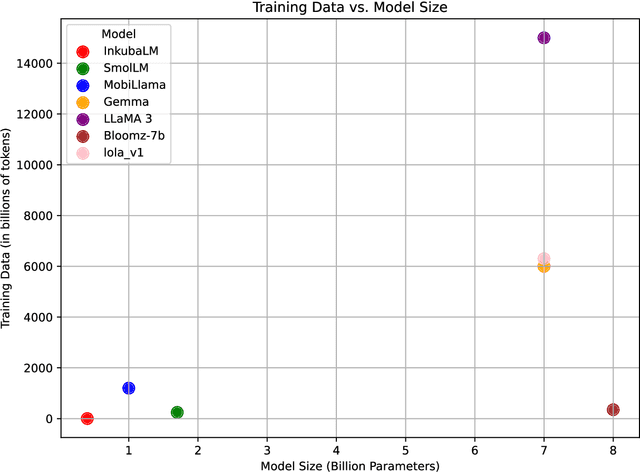
High-resource language models often fall short in the African context, where there is a critical need for models that are efficient, accessible, and locally relevant, even amidst significant computing and data constraints. This paper introduces InkubaLM, a small language model with 0.4 billion parameters, which achieves performance comparable to models with significantly larger parameter counts and more extensive training data on tasks such as machine translation, question-answering, AfriMMLU, and the AfriXnli task. Notably, InkubaLM outperforms many larger models in sentiment analysis and demonstrates remarkable consistency across multiple languages. This work represents a pivotal advancement in challenging the conventional paradigm that effective language models must rely on substantial resources. Our model and datasets are publicly available at https://huggingface.co/lelapa to encourage research and development on low-resource languages.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022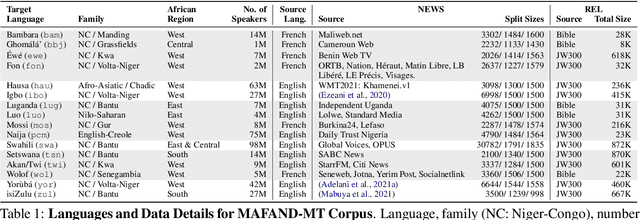
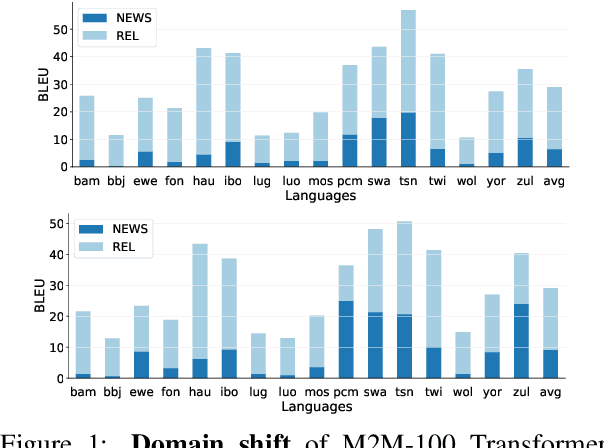

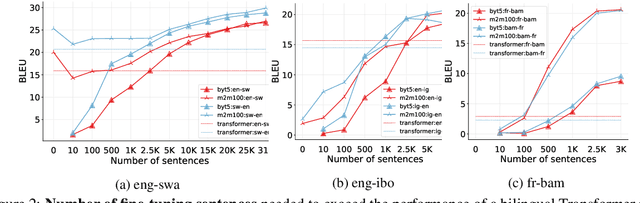
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
AI4D -- African Language Program
Apr 06, 2021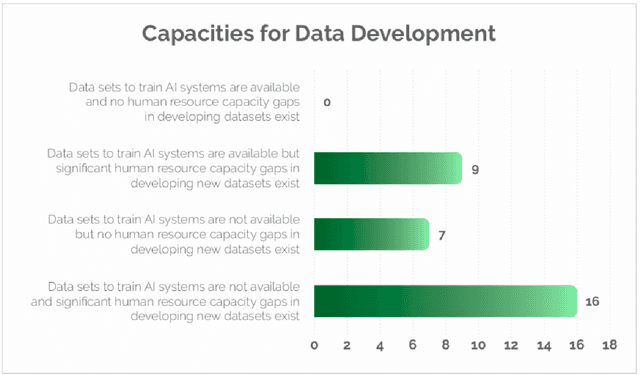
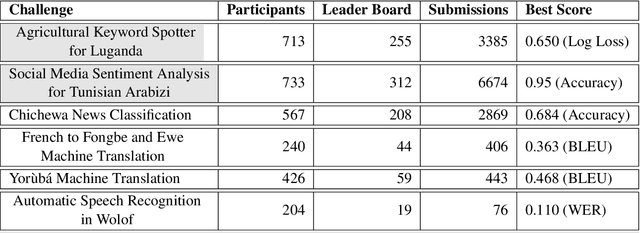
Advances in speech and language technologies enable tools such as voice-search, text-to-speech, speech recognition and machine translation. These are however only available for high resource languages like English, French or Chinese. Without foundational digital resources for African languages, which are considered low-resource in the digital context, these advanced tools remain out of reach. This work details the AI4D - African Language Program, a 3-part project that 1) incentivised the crowd-sourcing, collection and curation of language datasets through an online quantitative and qualitative challenge, 2) supported research fellows for a period of 3-4 months to create datasets annotated for NLP tasks, and 3) hosted competitive Machine Learning challenges on the basis of these datasets. Key outcomes of the work so far include 1) the creation of 9+ open source, African language datasets annotated for a variety of ML tasks, and 2) the creation of baseline models for these datasets through hosting of competitive ML challenges.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021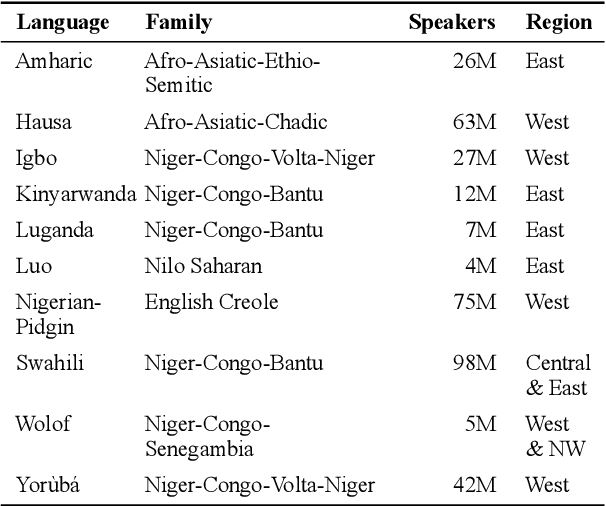

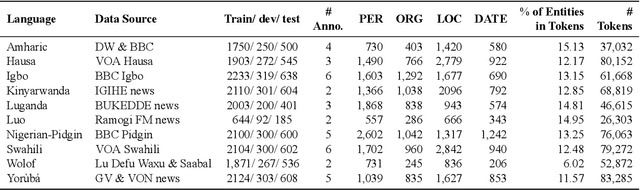
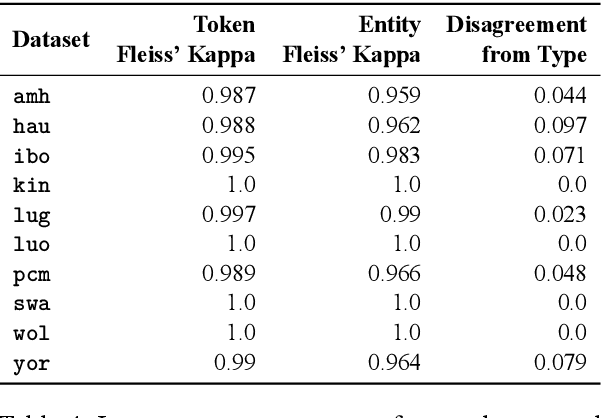
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
Oct 05, 2020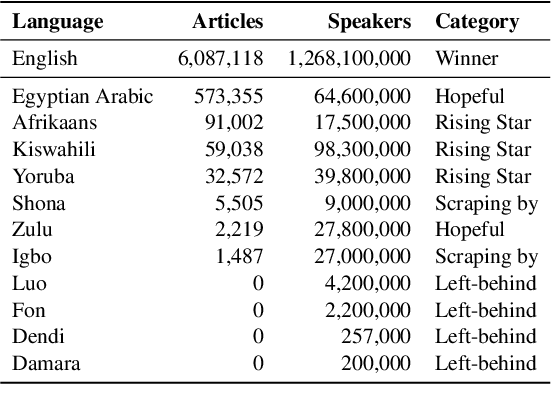
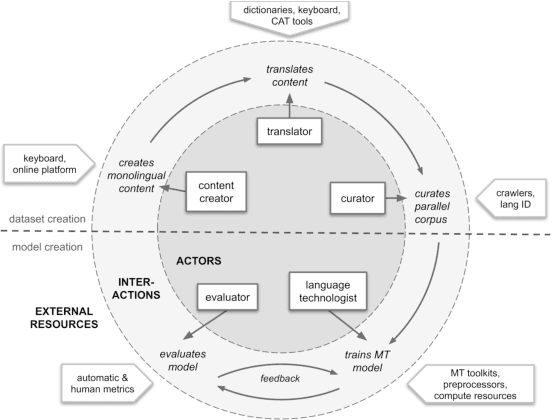
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. "Low-resourced"-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages. Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. Benchmarks, models, data, code, and evaluation results are released under https://github.com/masakhane-io/masakhane-mt.
AI4D -- African Language Dataset Challenge
Jul 23, 2020
As language and speech technologies become more advanced, the lack of fundamental digital resources for African languages, such as data, spell checkers and Part of Speech taggers, means that the digital divide between these languages and others keeps growing. This work details the organisation of the AI4D - African Language Dataset Challenge, an effort to incentivize the creation, organization and discovery of African language datasets through a competitive challenge. We particularly encouraged the submission of annotated datasets which can be used for training task-specific supervised machine learning models.
Masakhane -- Machine Translation For Africa
Mar 13, 2020
Africa has over 2000 languages. Despite this, African languages account for a small portion of available resources and publications in Natural Language Processing (NLP). This is due to multiple factors, including: a lack of focus from government and funding, discoverability, a lack of community, sheer language complexity, difficulty in reproducing papers and no benchmarks to compare techniques. To begin to address the identified problems, MASAKHANE, an open-source, continent-wide, distributed, online research effort for machine translation for African languages, was founded. In this paper, we discuss our methodology for building the community and spurring research from the African continent, as well as outline the success of the community in terms of addressing the identified problems affecting African NLP.