 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
Jun 05, 2024

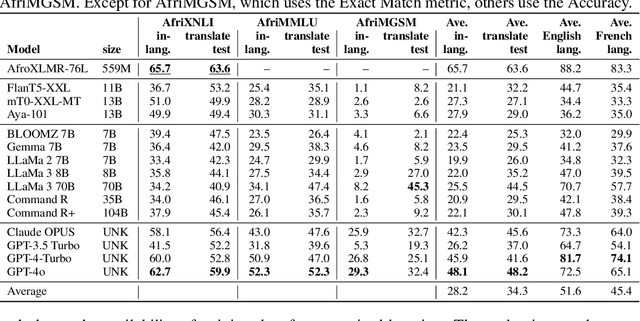
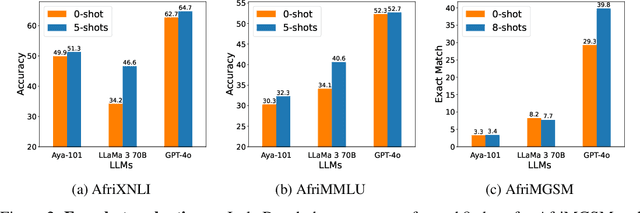
Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58\% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023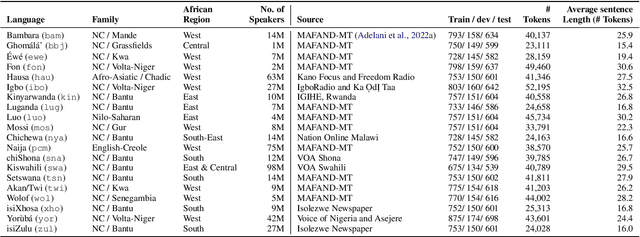
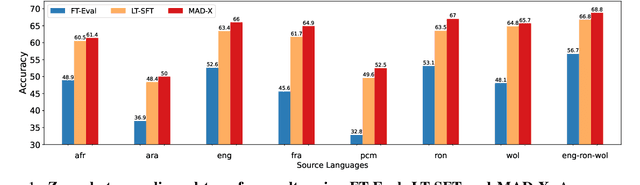
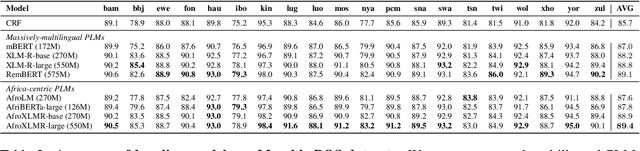
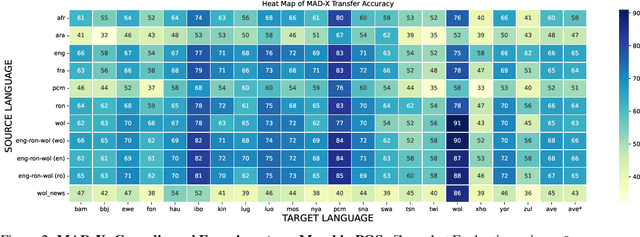
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
AI4D -- African Language Program
Apr 06, 2021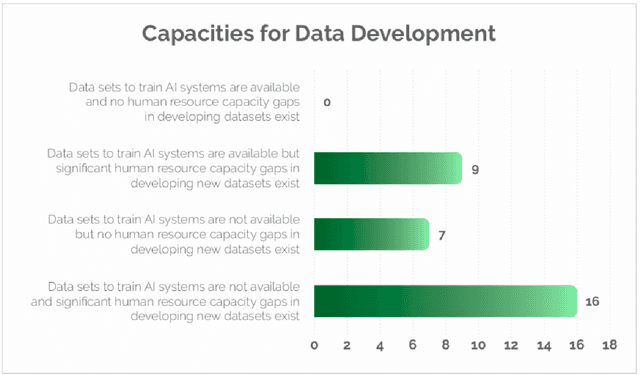
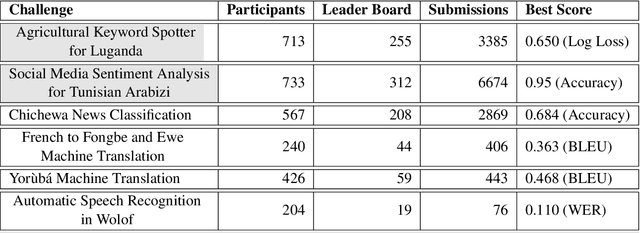
Advances in speech and language technologies enable tools such as voice-search, text-to-speech, speech recognition and machine translation. These are however only available for high resource languages like English, French or Chinese. Without foundational digital resources for African languages, which are considered low-resource in the digital context, these advanced tools remain out of reach. This work details the AI4D - African Language Program, a 3-part project that 1) incentivised the crowd-sourcing, collection and curation of language datasets through an online quantitative and qualitative challenge, 2) supported research fellows for a period of 3-4 months to create datasets annotated for NLP tasks, and 3) hosted competitive Machine Learning challenges on the basis of these datasets. Key outcomes of the work so far include 1) the creation of 9+ open source, African language datasets annotated for a variety of ML tasks, and 2) the creation of baseline models for these datasets through hosting of competitive ML challenges.