 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemwBTFreddy: A Dataset for Flash Flood Damage Assessment in Urban Malawi
May 02, 2025



This paper describes the mwBTFreddy dataset, a resource developed to support flash flood damage assessment in urban Malawi, specifically focusing on the impacts of Cyclone Freddy in 2023. The dataset comprises paired pre- and post-disaster satellite images sourced from Google Earth Pro, accompanied by JSON files containing labelled building annotations with geographic coordinates and damage levels (no damage, minor, major, or destroyed). Developed by the Kuyesera AI Lab at the Malawi University of Business and Applied Sciences, this dataset is intended to facilitate the development of machine learning models tailored to building detection and damage classification in African urban contexts. It also supports flood damage visualisation and spatial analysis to inform decisions on relocation, infrastructure planning, and emergency response in climate-vulnerable regions.
Using Machine Learning to Detect Fraudulent SMSs in Chichewa
Feb 24, 2025



SMS enabled fraud is of great concern globally. Building classifiers based on machine learning for SMS fraud requires the use of suitable datasets for model training and validation. Most research has centred on the use of datasets of SMSs in English. This paper introduces a first dataset for SMS fraud detection in Chichewa, a major language in Africa, and reports on experiments with machine learning algorithms for classifying SMSs in Chichewa as fraud or non-fraud. We answer the broader research question of how feasible it is to develop machine learning classification models for Chichewa SMSs. To do that, we created three datasets. A small dataset of SMS in Chichewa was collected through primary research from a segment of the young population. We applied a label-preserving text transformations to increase its size. The enlarged dataset was translated into English using two approaches: human translation and machine translation. The Chichewa and the translated datasets were subjected to machine classification using random forest and logistic regression. Our findings indicate that both models achieved a promising accuracy of over 96% on the Chichewa dataset. There was a drop in performance when moving from the Chichewa to the translated dataset. This highlights the importance of data preprocessing, especially in multilingual or cross-lingual NLP tasks, and shows the challenges of relying on machine-translated text for training machine learning models. Our results underscore the importance of developing language specific models for SMS fraud detection to optimise accuracy and performance. Since most machine learning models require data preprocessing, it is essential to investigate the impact of the reliance on English-specific tools for data preprocessing.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023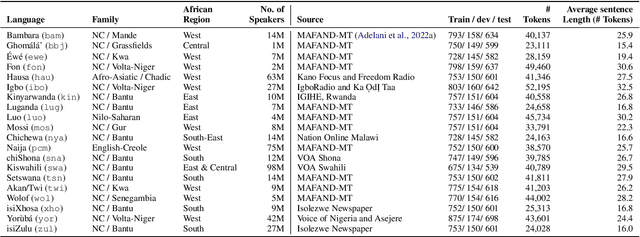
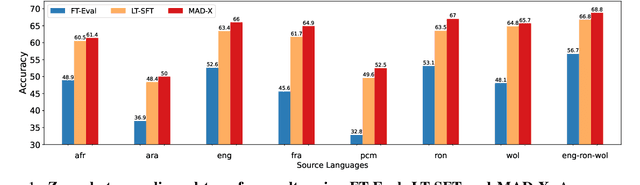
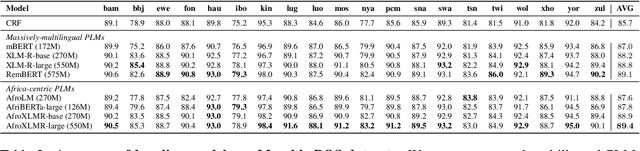
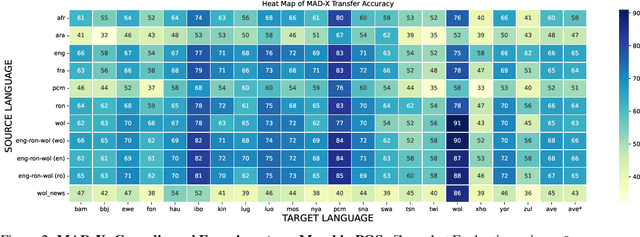
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
AI4D -- African Language Program
Apr 06, 2021
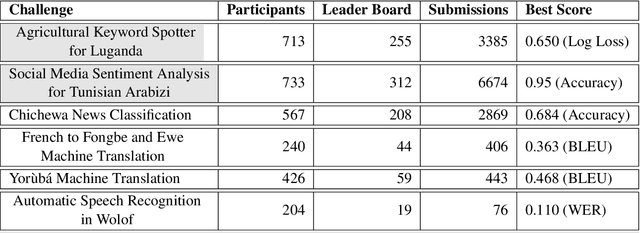
Advances in speech and language technologies enable tools such as voice-search, text-to-speech, speech recognition and machine translation. These are however only available for high resource languages like English, French or Chinese. Without foundational digital resources for African languages, which are considered low-resource in the digital context, these advanced tools remain out of reach. This work details the AI4D - African Language Program, a 3-part project that 1) incentivised the crowd-sourcing, collection and curation of language datasets through an online quantitative and qualitative challenge, 2) supported research fellows for a period of 3-4 months to create datasets annotated for NLP tasks, and 3) hosted competitive Machine Learning challenges on the basis of these datasets. Key outcomes of the work so far include 1) the creation of 9+ open source, African language datasets annotated for a variety of ML tasks, and 2) the creation of baseline models for these datasets through hosting of competitive ML challenges.