 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom N-grams to Pre-trained Multilingual Models For Language Identification
Oct 11, 2024



In this paper, we investigate the use of N-gram models and Large Pre-trained Multilingual models for Language Identification (LID) across 11 South African languages. For N-gram models, this study shows that effective data size selection remains crucial for establishing effective frequency distributions of the target languages, that efficiently model each language, thus, improving language ranking. For pre-trained multilingual models, we conduct extensive experiments covering a diverse set of massively pre-trained multilingual (PLM) models -- mBERT, RemBERT, XLM-r, and Afri-centric multilingual models -- AfriBERTa, Afro-XLMr, AfroLM, and Serengeti. We further compare these models with available large-scale Language Identification tools: Compact Language Detector v3 (CLD V3), AfroLID, GlotLID, and OpenLID to highlight the importance of focused-based LID. From these, we show that Serengeti is a superior model across models: N-grams to Transformers on average. Moreover, we propose a lightweight BERT-based LID model (za_BERT_lid) trained with NHCLT + Vukzenzele corpus, which performs on par with our best-performing Afri-centric models.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023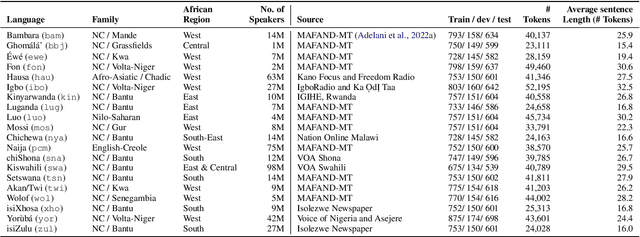
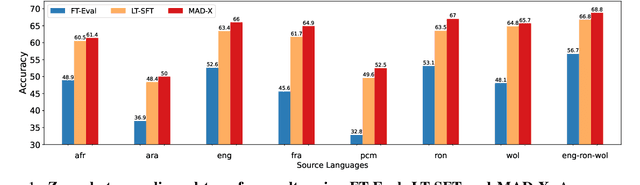
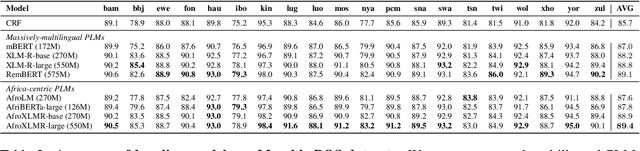
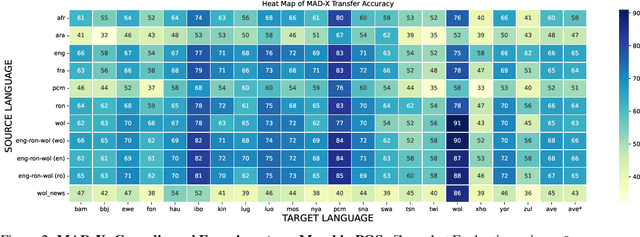
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.