 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI4D -- African Language Program
Paper and Code
Apr 06, 2021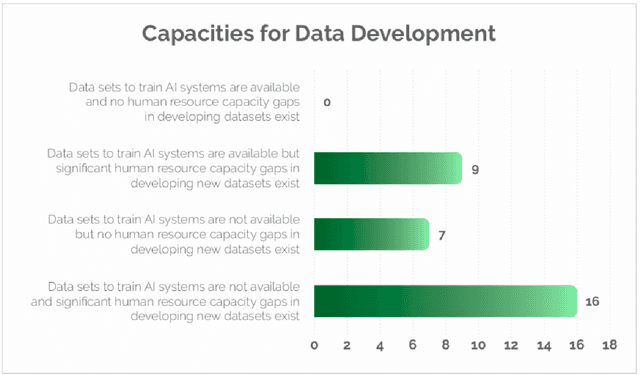
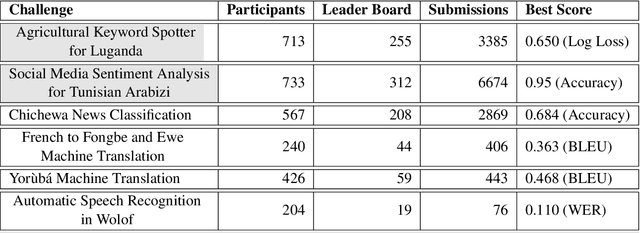
Advances in speech and language technologies enable tools such as voice-search, text-to-speech, speech recognition and machine translation. These are however only available for high resource languages like English, French or Chinese. Without foundational digital resources for African languages, which are considered low-resource in the digital context, these advanced tools remain out of reach. This work details the AI4D - African Language Program, a 3-part project that 1) incentivised the crowd-sourcing, collection and curation of language datasets through an online quantitative and qualitative challenge, 2) supported research fellows for a period of 3-4 months to create datasets annotated for NLP tasks, and 3) hosted competitive Machine Learning challenges on the basis of these datasets. Key outcomes of the work so far include 1) the creation of 9+ open source, African language datasets annotated for a variety of ML tasks, and 2) the creation of baseline models for these datasets through hosting of competitive ML challenges.