 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1st AfricaNLP Workshop Proceedings, 2020
Nov 20, 2020Proceedings of the 1st AfricaNLP Workshop held on 26th April alongside ICLR 2020, Virtual Conference, Formerly Addis Ababa Ethiopia.
Neural Machine Translation for South Africa's Official Languages
May 08, 2020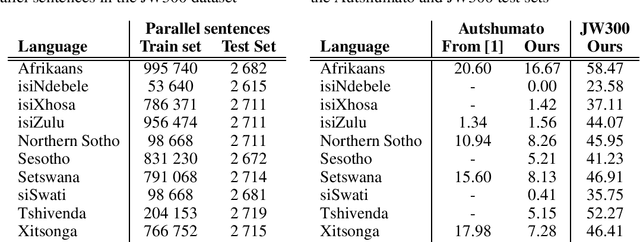
Recent advances in neural machine translation (NMT) have led to state-of-the-art results for many European-based translation tasks. However, despite these advances, there is has been little focus in applying these methods to African languages. In this paper, we seek to address this gap by creating an NMT benchmark BLEU score between English and the ten remaining official languages in South Africa.
Masakhane -- Machine Translation For Africa
Mar 13, 2020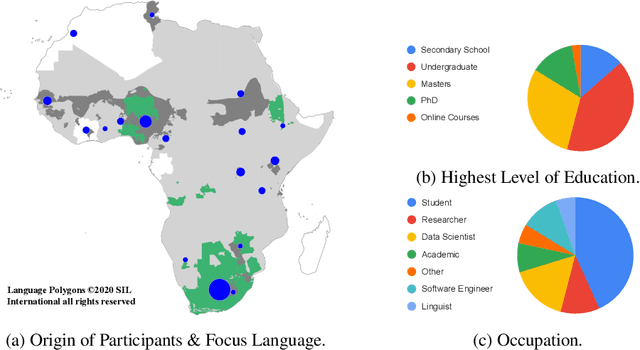
Africa has over 2000 languages. Despite this, African languages account for a small portion of available resources and publications in Natural Language Processing (NLP). This is due to multiple factors, including: a lack of focus from government and funding, discoverability, a lack of community, sheer language complexity, difficulty in reproducing papers and no benchmarks to compare techniques. To begin to address the identified problems, MASAKHANE, an open-source, continent-wide, distributed, online research effort for machine translation for African languages, was founded. In this paper, we discuss our methodology for building the community and spurring research from the African continent, as well as outline the success of the community in terms of addressing the identified problems affecting African NLP.
Benchmarking Neural Machine Translation for Southern African Languages
Jun 17, 2019



Unlike major Western languages, most African languages are very low-resourced. Furthermore, the resources that do exist are often scattered and difficult to obtain and discover. As a result, the data and code for existing research has rarely been shared. This has lead a struggle to reproduce reported results, and few publicly available benchmarks for African machine translation models exist. To start to address these problems, we trained neural machine translation models for 5 Southern African languages on publicly-available datasets. Code is provided for training the models and evaluate the models on a newly released evaluation set, with the aim of spur future research in the field for Southern African languages.
A Focus on Neural Machine Translation for African Languages
Jun 14, 2019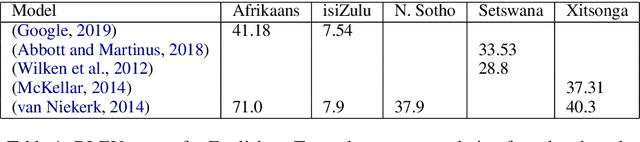
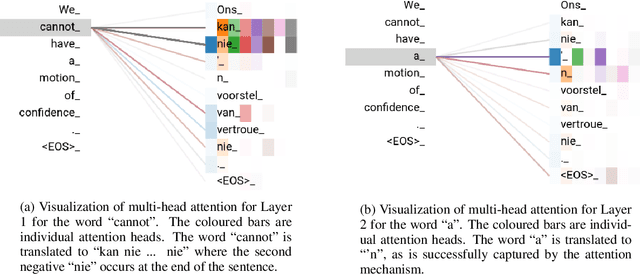
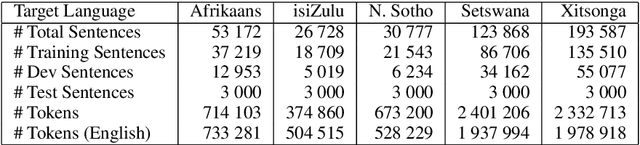

African languages are numerous, complex and low-resourced. The datasets required for machine translation are difficult to discover, and existing research is hard to reproduce. Minimal attention has been given to machine translation for African languages so there is scant research regarding the problems that arise when using machine translation techniques. To begin addressing these problems, we trained models to translate English to five of the official South African languages (Afrikaans, isiZulu, Northern Sotho, Setswana, Xitsonga), making use of modern neural machine translation techniques. The results obtained show the promise of using neural machine translation techniques for African languages. By providing reproducible publicly-available data, code and results, this research aims to provide a starting point for other researchers in African machine translation to compare to and build upon.
Towards Neural Machine Translation for African Languages
Nov 13, 2018
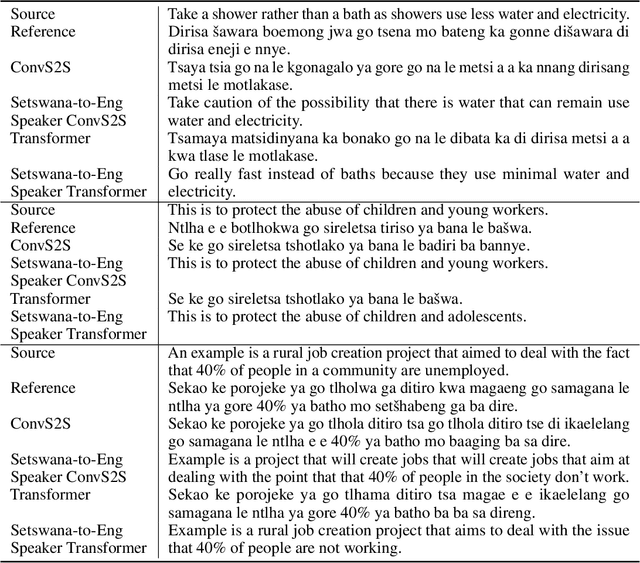
Given that South African education is in crisis, strategies for improvement and sustainability of high-quality, up-to-date education must be explored. In the migration of education online, inclusion of machine translation for low-resourced local languages becomes necessary. This paper aims to spur the use of current neural machine translation (NMT) techniques for low-resourced local languages. The paper demonstrates state-of-the-art performance on English-to-Setswana translation using the Autshumato dataset. The use of the Transformer architecture beat previous techniques by 5.33 BLEU points. This demonstrates the promise of using current NMT techniques for African languages.