 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction Finetuning for Leaderboard Generation from Empirical AI Research
Aug 19, 2024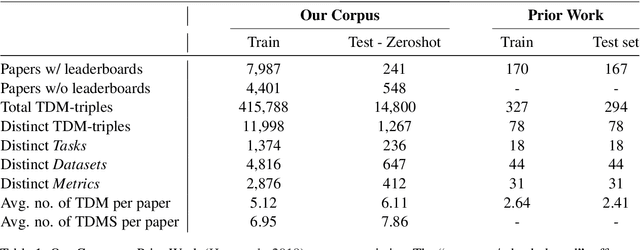
This study demonstrates the application of instruction finetuning of pretrained Large Language Models (LLMs) to automate the generation of AI research leaderboards, extracting (Task, Dataset, Metric, Score) quadruples from articles. It aims to streamline the dissemination of advancements in AI research by transitioning from traditional, manual community curation, or otherwise taxonomy-constrained natural language inference (NLI) models, to an automated, generative LLM-based approach. Utilizing the FLAN-T5 model, this research enhances LLMs' adaptability and reliability in information extraction, offering a novel method for structured knowledge representation.
Exploring the Latest LLMs for Leaderboard Extraction
Jun 06, 2024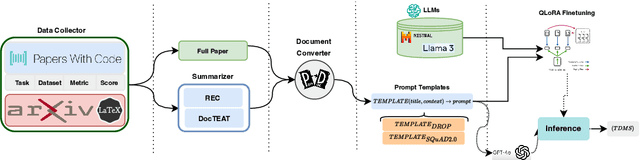
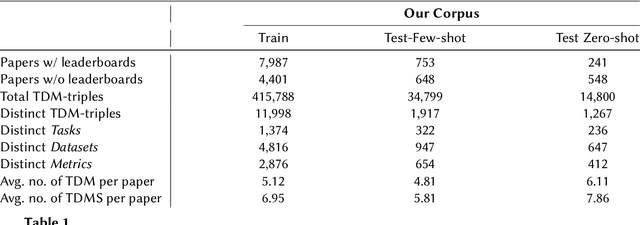
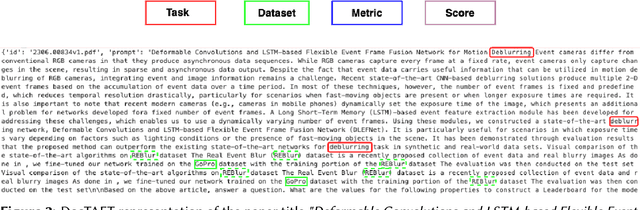
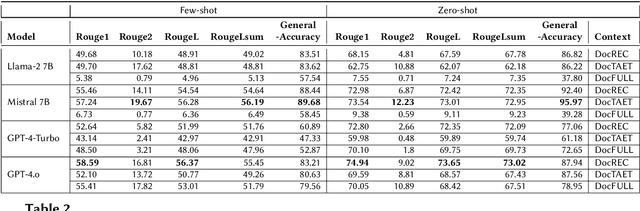
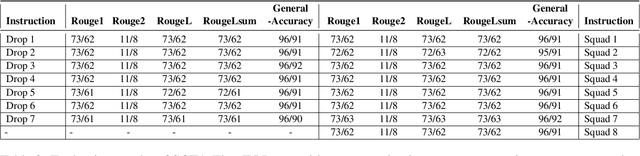
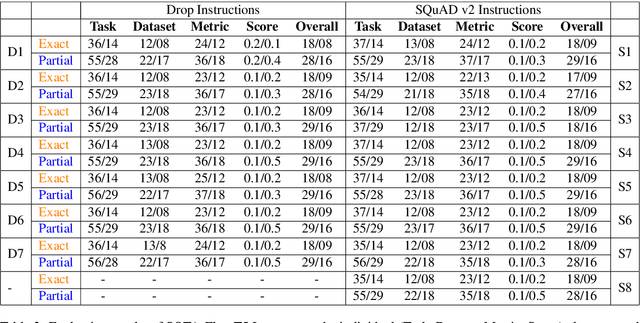
The rapid advancements in Large Language Models (LLMs) have opened new avenues for automating complex tasks in AI research. This paper investigates the efficacy of different LLMs-Mistral 7B, Llama-2, GPT-4-Turbo and GPT-4.o in extracting leaderboard information from empirical AI research articles. We explore three types of contextual inputs to the models: DocTAET (Document Title, Abstract, Experimental Setup, and Tabular Information), DocREC (Results, Experiments, and Conclusions), and DocFULL (entire document). Our comprehensive study evaluates the performance of these models in generating (Task, Dataset, Metric, Score) quadruples from research papers. The findings reveal significant insights into the strengths and limitations of each model and context type, providing valuable guidance for future AI research automation efforts.
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
Jun 05, 2024

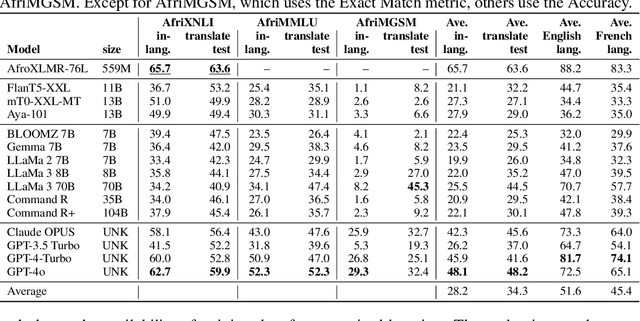
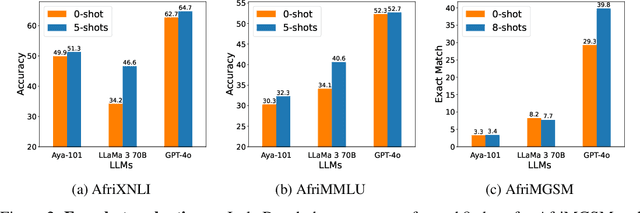
Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58\% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.
ORKG-Leaderboards: A Systematic Workflow for Mining Leaderboards as a Knowledge Graph
May 10, 2023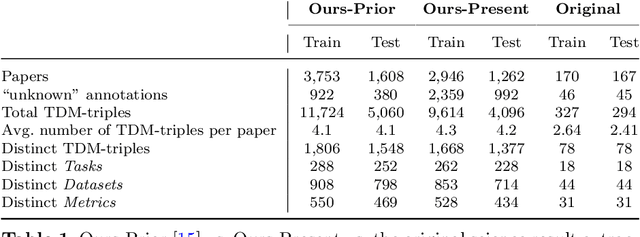
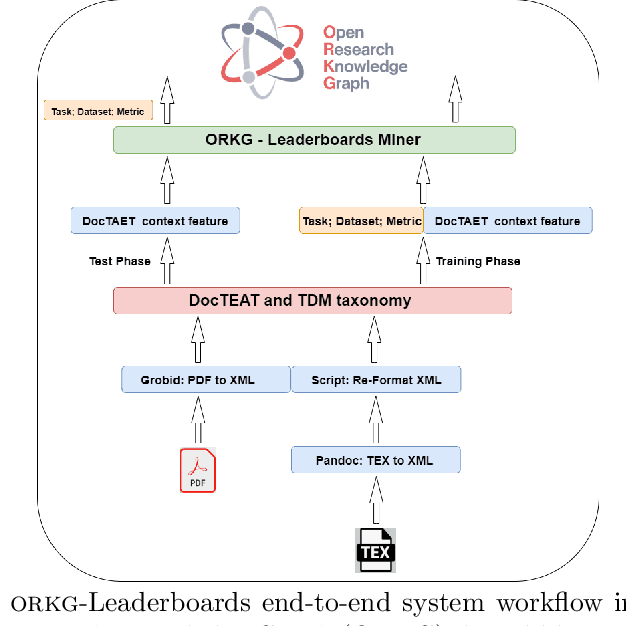
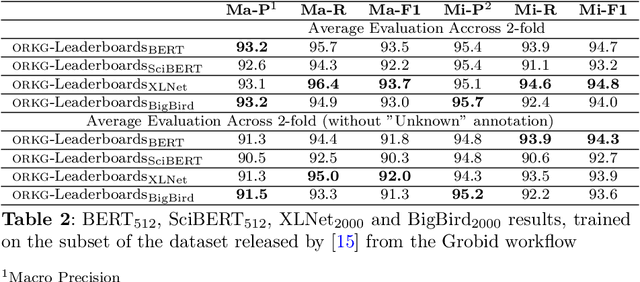
The purpose of this work is to describe the Orkg-Leaderboard software designed to extract leaderboards defined as Task-Dataset-Metric tuples automatically from large collections of empirical research papers in Artificial Intelligence (AI). The software can support both the main workflows of scholarly publishing, viz. as LaTeX files or as PDF files. Furthermore, the system is integrated with the Open Research Knowledge Graph (ORKG) platform, which fosters the machine-actionable publishing of scholarly findings. Thus the system output, when integrated within the ORKG's supported Semantic Web infrastructure of representing machine-actionable 'resources' on the Web, enables: 1) broadly, the integration of empirical results of researchers across the world, thus enabling transparency in empirical research with the potential to also being complete contingent on the underlying data source(s) of publications; and 2) specifically, enables researchers to track the progress in AI with an overview of the state-of-the-art (SOTA) across the most common AI tasks and their corresponding datasets via dynamic ORKG frontend views leveraging tables and visualization charts over the machine-actionable data. Our best model achieves performances above 90% F1 on the \textit{leaderboard} extraction task, thus proving Orkg-Leaderboards a practically viable tool for real-world usage. Going forward, in a sense, Orkg-Leaderboards transforms the leaderboard extraction task to an automated digitalization task, which has been, for a long time in the community, a crowdsourced endeavor.
Zero-shot Entailment of Leaderboards for Empirical AI Research
Mar 29, 2023


We present a large-scale empirical investigation of the zero-shot learning phenomena in a specific recognizing textual entailment (RTE) task category, i.e. the automated mining of leaderboards for Empirical AI Research. The prior reported state-of-the-art models for leaderboards extraction formulated as an RTE task, in a non-zero-shot setting, are promising with above 90% reported performances. However, a central research question remains unexamined: did the models actually learn entailment? Thus, for the experiments in this paper, two prior reported state-of-the-art models are tested out-of-the-box for their ability to generalize or their capacity for entailment, given leaderboard labels that were unseen during training. We hypothesize that if the models learned entailment, their zero-shot performances can be expected to be moderately high as well--perhaps, concretely, better than chance. As a result of this work, a zero-shot labeled dataset is created via distant labeling formulating the leaderboard extraction RTE task.
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022
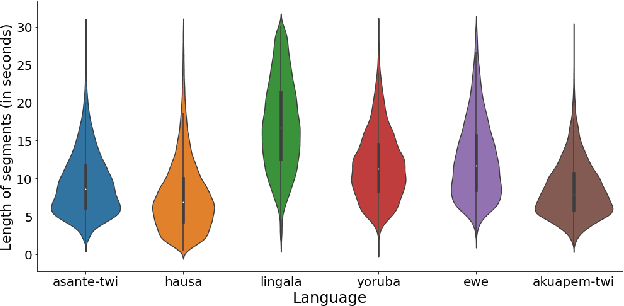

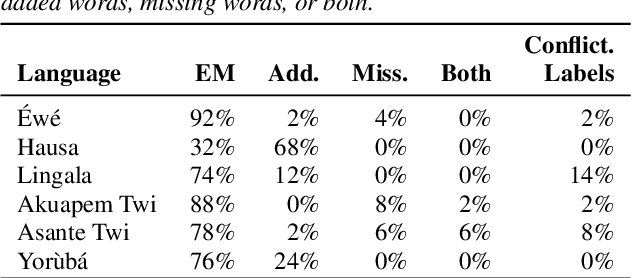
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
Oct 05, 2020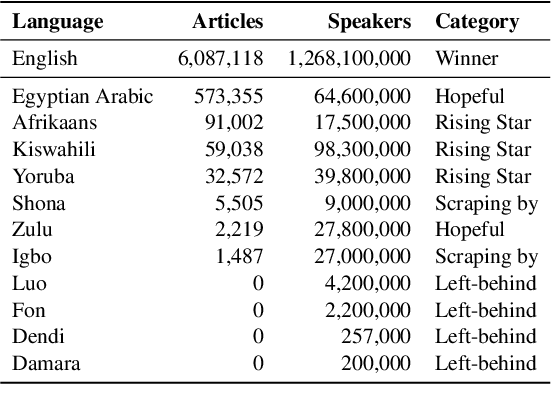
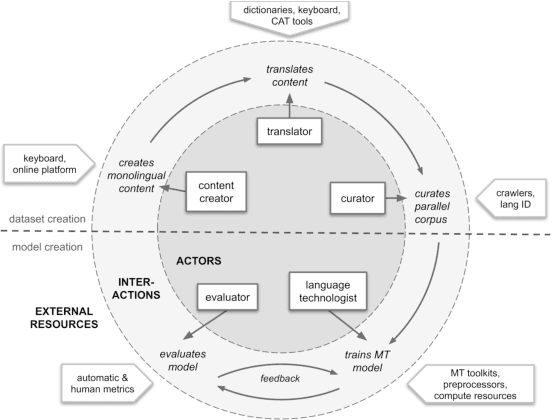
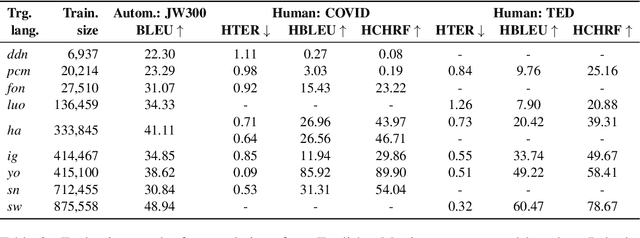
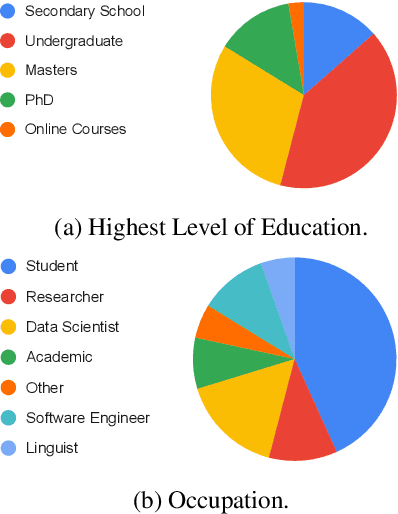
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. "Low-resourced"-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages. Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. Benchmarks, models, data, code, and evaluation results are released under https://github.com/masakhane-io/masakhane-mt.
Masakhane -- Machine Translation For Africa
Mar 13, 2020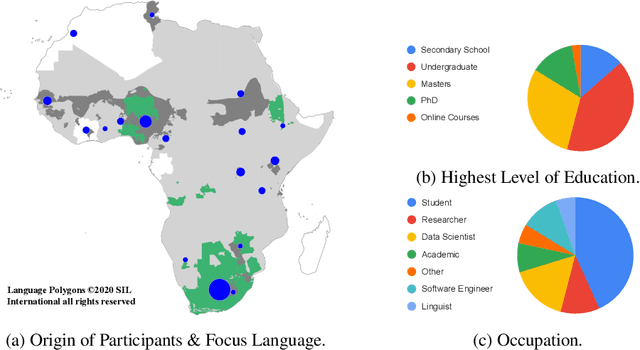
Africa has over 2000 languages. Despite this, African languages account for a small portion of available resources and publications in Natural Language Processing (NLP). This is due to multiple factors, including: a lack of focus from government and funding, discoverability, a lack of community, sheer language complexity, difficulty in reproducing papers and no benchmarks to compare techniques. To begin to address the identified problems, MASAKHANE, an open-source, continent-wide, distributed, online research effort for machine translation for African languages, was founded. In this paper, we discuss our methodology for building the community and spurring research from the African continent, as well as outline the success of the community in terms of addressing the identified problems affecting African NLP.