 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Latest LLMs for Leaderboard Extraction
Paper and Code
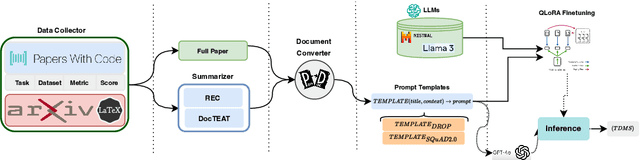
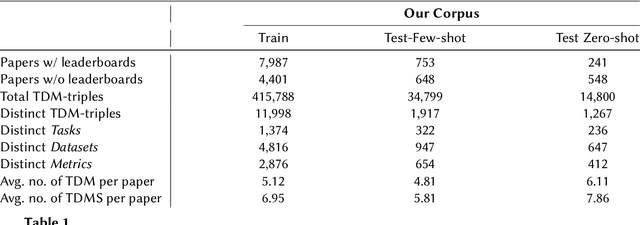
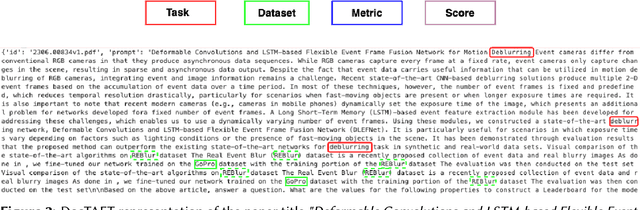
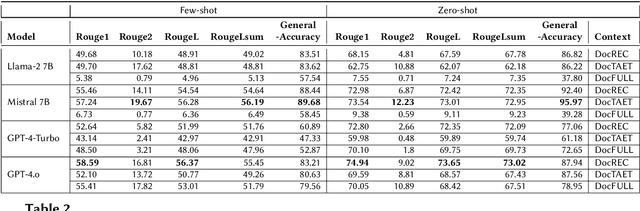
The rapid advancements in Large Language Models (LLMs) have opened new avenues for automating complex tasks in AI research. This paper investigates the efficacy of different LLMs-Mistral 7B, Llama-2, GPT-4-Turbo and GPT-4.o in extracting leaderboard information from empirical AI research articles. We explore three types of contextual inputs to the models: DocTAET (Document Title, Abstract, Experimental Setup, and Tabular Information), DocREC (Results, Experiments, and Conclusions), and DocFULL (entire document). Our comprehensive study evaluates the performance of these models in generating (Task, Dataset, Metric, Score) quadruples from research papers. The findings reveal significant insights into the strengths and limitations of each model and context type, providing valuable guidance for future AI research automation efforts.