 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBloom Library: Multimodal Datasets in 300+ Languages for a Variety of Downstream Tasks
Oct 26, 2022
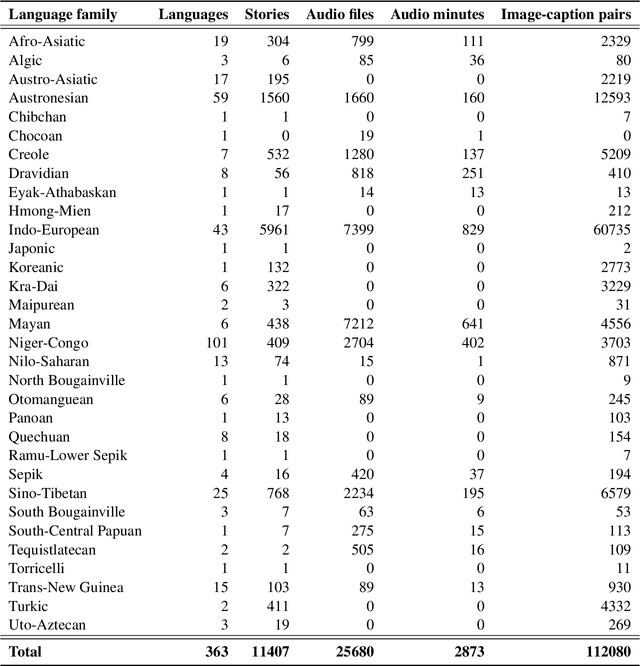
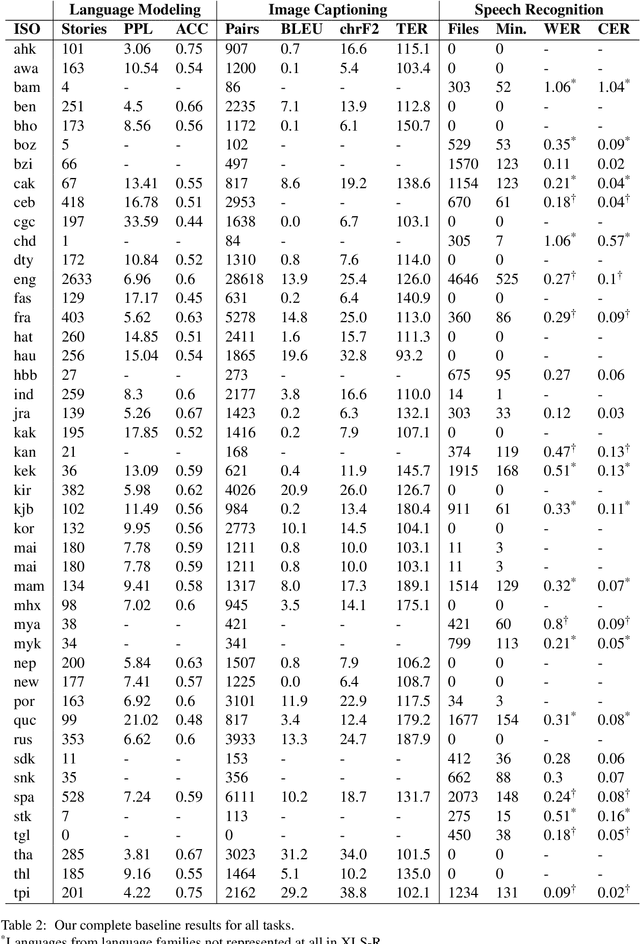
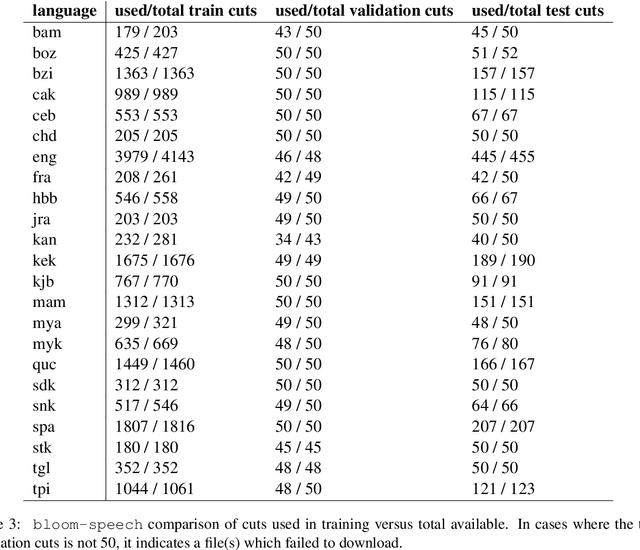
We present Bloom Library, a linguistically diverse set of multimodal and multilingual datasets for language modeling, image captioning, visual storytelling, and speech synthesis/recognition. These datasets represent either the most, or among the most, multilingual datasets for each of the included downstream tasks. In total, the initial release of the Bloom Library datasets covers 363 languages across 32 language families. We train downstream task models for various languages represented in the data, showing the viability of the data for future work in low-resource, multimodal NLP and establishing the first known baselines for these downstream tasks in certain languages (e.g., Bisu [bzi], with an estimated population of 700 users). Some of these first-of-their-kind baselines are comparable to state-of-the-art performance for higher-resourced languages. The Bloom Library datasets are released under Creative Commons licenses on the Hugging Face datasets hub to catalyze more linguistically diverse research in the included downstream tasks.
* 14 pages, 1 figure, 3 tables, accepted to and presented at EMNLP 2022
Dyn-ASR: Compact, Multilingual Speech Recognition via Spoken Language and Accent Identification
Aug 04, 2021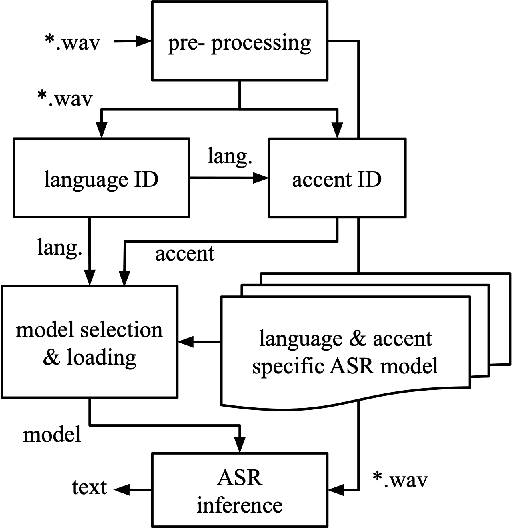
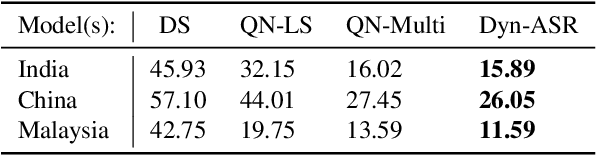

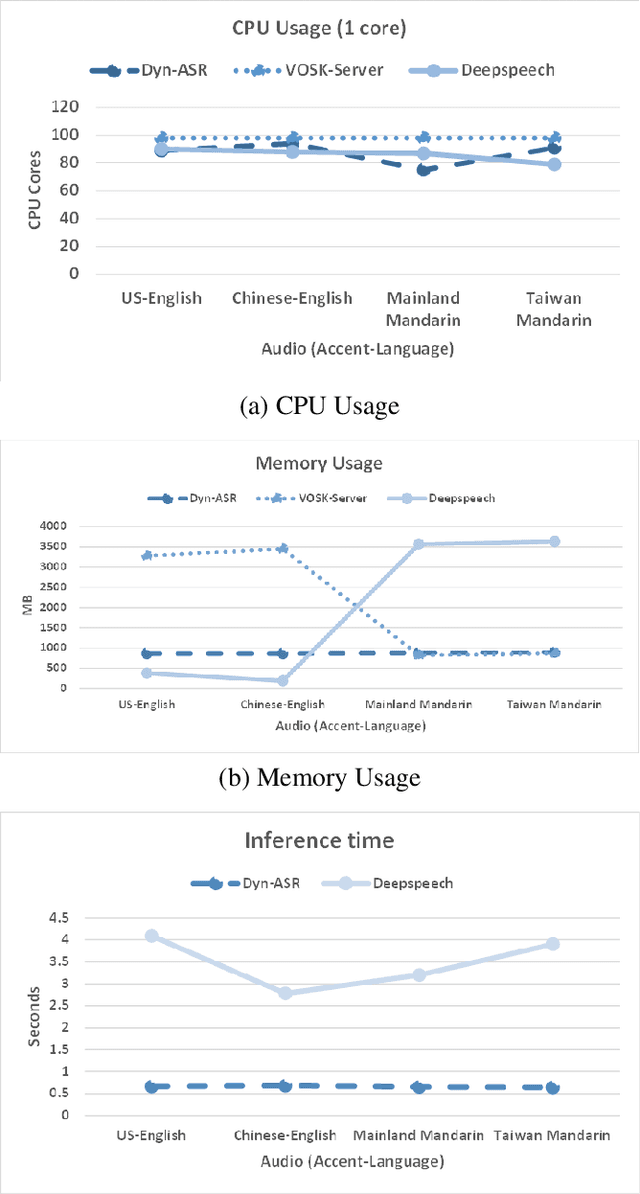
Running automatic speech recognition (ASR) on edge devices is non-trivial due to resource constraints, especially in scenarios that require supporting multiple languages. We propose a new approach to enable multilingual speech recognition on edge devices. This approach uses both language identification and accent identification to select one of multiple monolingual ASR models on-the-fly, each fine-tuned for a particular accent. Initial results for both recognition performance and resource usage are promising with our approach using less than 1/12th of the memory consumed by other solutions.
Participatory Research for Low-resourced Machine Translation: A Case Study in African Languages
Oct 05, 2020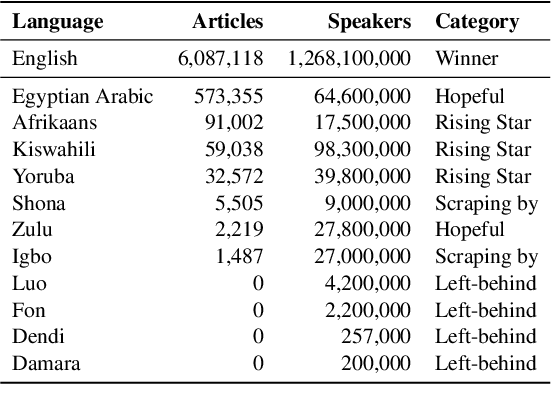
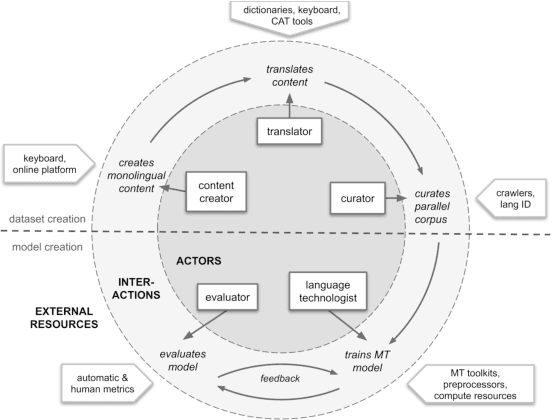
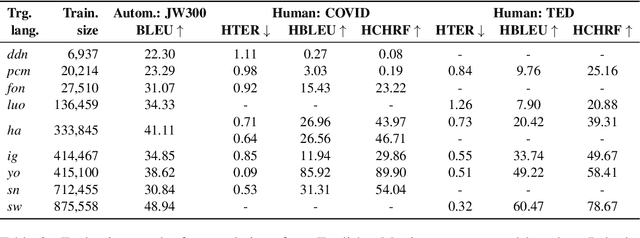
Research in NLP lacks geographic diversity, and the question of how NLP can be scaled to low-resourced languages has not yet been adequately solved. "Low-resourced"-ness is a complex problem going beyond data availability and reflects systemic problems in society. In this paper, we focus on the task of Machine Translation (MT), that plays a crucial role for information accessibility and communication worldwide. Despite immense improvements in MT over the past decade, MT is centered around a few high-resourced languages. As MT researchers cannot solve the problem of low-resourcedness alone, we propose participatory research as a means to involve all necessary agents required in the MT development process. We demonstrate the feasibility and scalability of participatory research with a case study on MT for African languages. Its implementation leads to a collection of novel translation datasets, MT benchmarks for over 30 languages, with human evaluations for a third of them, and enables participants without formal training to make a unique scientific contribution. Benchmarks, models, data, code, and evaluation results are released under https://github.com/masakhane-io/masakhane-mt.
Masakhane -- Machine Translation For Africa
Mar 13, 2020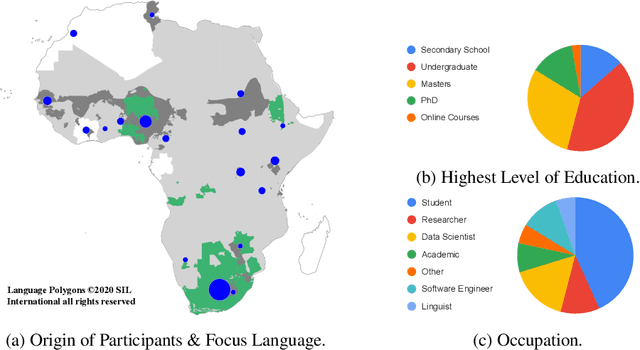
Africa has over 2000 languages. Despite this, African languages account for a small portion of available resources and publications in Natural Language Processing (NLP). This is due to multiple factors, including: a lack of focus from government and funding, discoverability, a lack of community, sheer language complexity, difficulty in reproducing papers and no benchmarks to compare techniques. To begin to address the identified problems, MASAKHANE, an open-source, continent-wide, distributed, online research effort for machine translation for African languages, was founded. In this paper, we discuss our methodology for building the community and spurring research from the African continent, as well as outline the success of the community in terms of addressing the identified problems affecting African NLP.
Katecheo: A Portable and Modular System for Multi-Topic Question Answering
Jul 01, 2019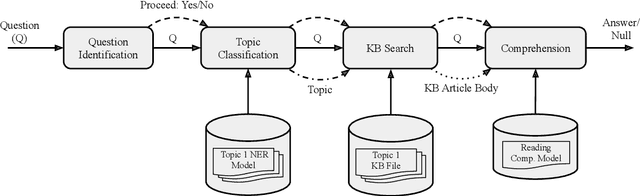
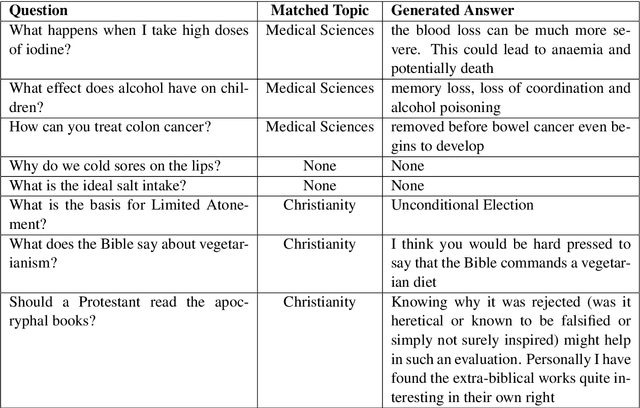
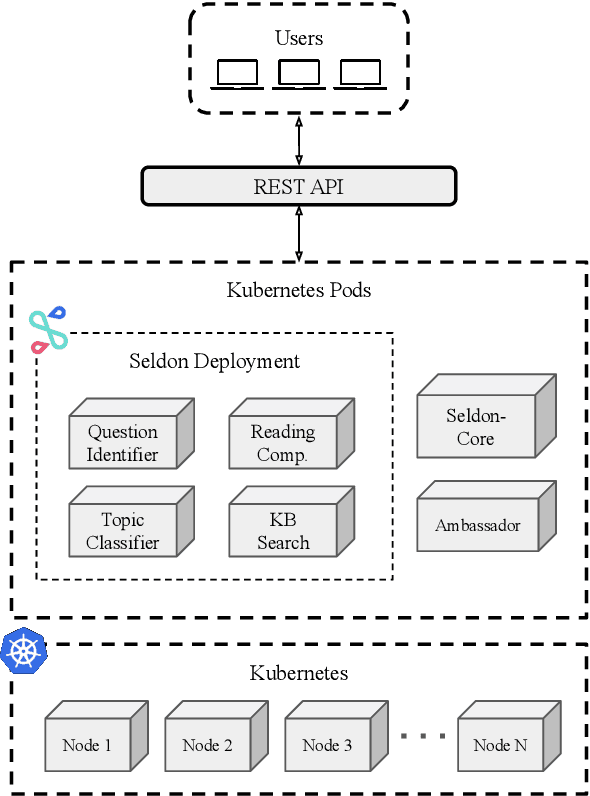
We introduce a modular system that can be deployed on any Kubernetes cluster for question answering via REST API. This system, called Katecheo, includes four configurable modules that collectively enable identification of questions, classification of those questions into topics, a search of knowledge base articles, and reading comprehension. We demonstrate the system using publicly available, pre-trained models and knowledge base articles extracted from Stack Exchange sites. However, users can extend the system to any number of topics, or domains, without the need to modify any of the model serving code. All components of the system are open source and available under a permissive Apache 2 License.