Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyn-ASR: Compact, Multilingual Speech Recognition via Spoken Language and Accent Identification
Paper and Code
Aug 04, 2021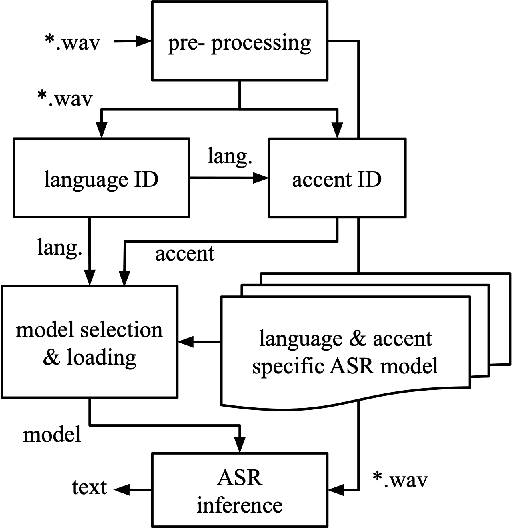
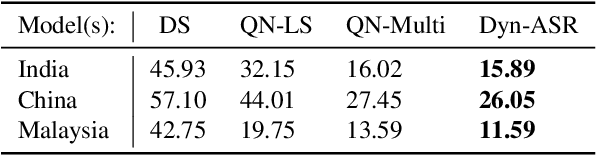

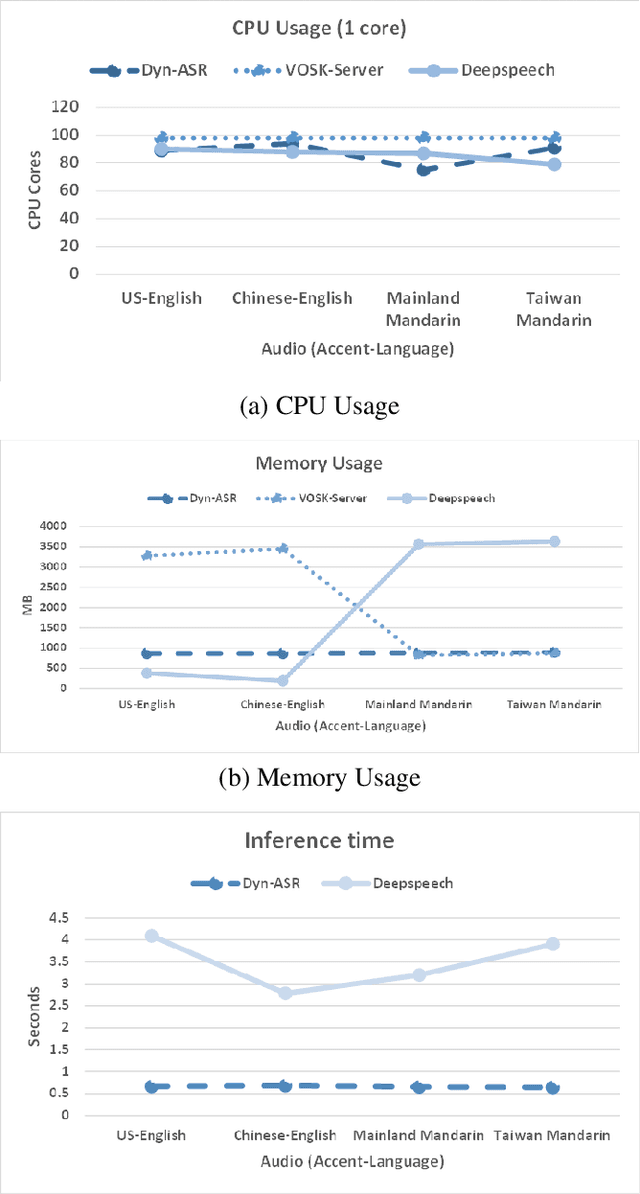
Running automatic speech recognition (ASR) on edge devices is non-trivial due to resource constraints, especially in scenarios that require supporting multiple languages. We propose a new approach to enable multilingual speech recognition on edge devices. This approach uses both language identification and accent identification to select one of multiple monolingual ASR models on-the-fly, each fine-tuned for a particular accent. Initial results for both recognition performance and resource usage are promising with our approach using less than 1/12th of the memory consumed by other solutions.
* Accepted to IEEE WF-IOT 2021
View paper on