 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Domain Automatic Short Answer Grading through an Explainable Neuro-Symbolic Pipeline
Mar 04, 2024Grading short answer questions automatically with interpretable reasoning behind the grading decision is a challenging goal for current transformer approaches. Justification cue detection, in combination with logical reasoners, has shown a promising direction for neuro-symbolic architectures in ASAG. But, one of the main challenges is the requirement of annotated justification cues in the students' responses, which only exist for a few ASAG datasets. To overcome this challenge, we contribute (1) a weakly supervised annotation procedure for justification cues in ASAG datasets, and (2) a neuro-symbolic model for explainable ASAG based on justification cues. Our approach improves upon the RMSE by 0.24 to 0.3 compared to the state-of-the-art on the Short Answer Feedback dataset in a bilingual, multi-domain, and multi-question training setup. This result shows that our approach provides a promising direction for generating high-quality grades and accompanying explanations for future research in ASAG and educational NLP.
Bloom Library: Multimodal Datasets in 300+ Languages for a Variety of Downstream Tasks
Oct 26, 2022
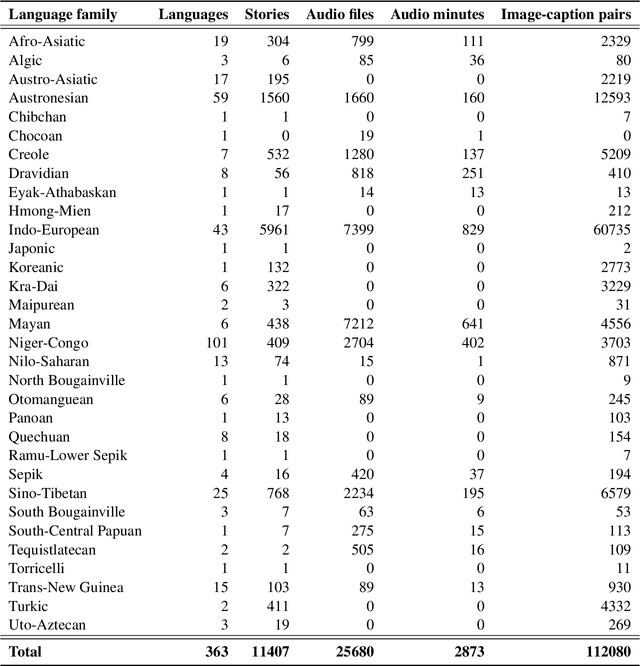
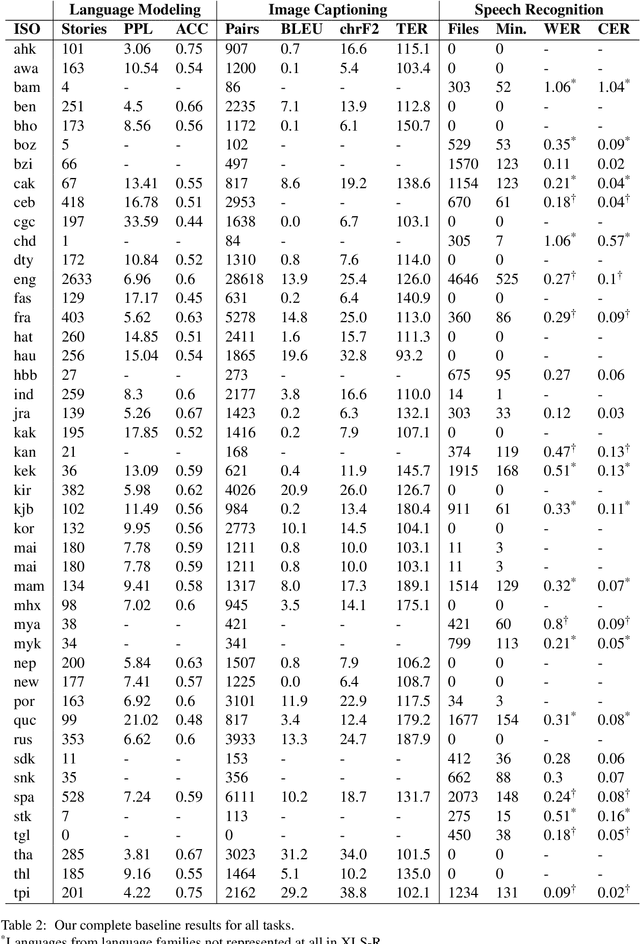
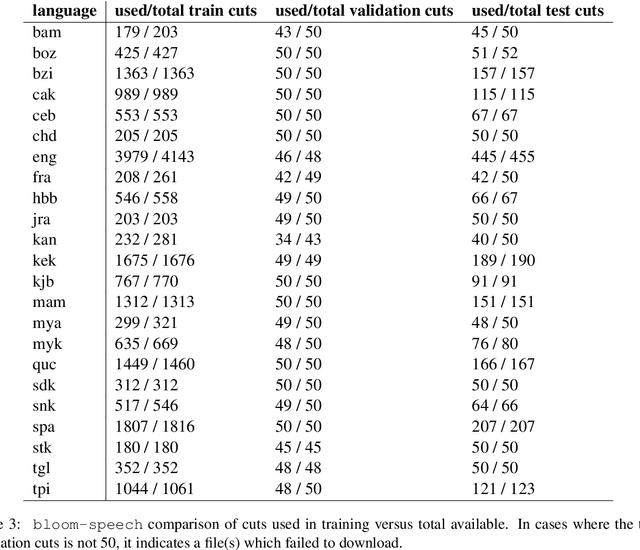
We present Bloom Library, a linguistically diverse set of multimodal and multilingual datasets for language modeling, image captioning, visual storytelling, and speech synthesis/recognition. These datasets represent either the most, or among the most, multilingual datasets for each of the included downstream tasks. In total, the initial release of the Bloom Library datasets covers 363 languages across 32 language families. We train downstream task models for various languages represented in the data, showing the viability of the data for future work in low-resource, multimodal NLP and establishing the first known baselines for these downstream tasks in certain languages (e.g., Bisu [bzi], with an estimated population of 700 users). Some of these first-of-their-kind baselines are comparable to state-of-the-art performance for higher-resourced languages. The Bloom Library datasets are released under Creative Commons licenses on the Hugging Face datasets hub to catalyze more linguistically diverse research in the included downstream tasks.
* 14 pages, 1 figure, 3 tables, accepted to and presented at EMNLP 2022
Cheating Automatic Short Answer Grading: On the Adversarial Usage of Adjectives and Adverbs
Jan 20, 2022Automatic grading models are valued for the time and effort saved during the instruction of large student bodies. Especially with the increasing digitization of education and interest in large-scale standardized testing, the popularity of automatic grading has risen to the point where commercial solutions are widely available and used. However, for short answer formats, automatic grading is challenging due to natural language ambiguity and versatility. While automatic short answer grading models are beginning to compare to human performance on some datasets, their robustness, especially to adversarially manipulated data, is questionable. Exploitable vulnerabilities in grading models can have far-reaching consequences ranging from cheating students receiving undeserved credit to undermining automatic grading altogether - even when most predictions are valid. In this paper, we devise a black-box adversarial attack tailored to the educational short answer grading scenario to investigate the grading models' robustness. In our attack, we insert adjectives and adverbs into natural places of incorrect student answers, fooling the model into predicting them as correct. We observed a loss of prediction accuracy between 10 and 22 percentage points using the state-of-the-art models BERT and T5. While our attack made answers appear less natural to humans in our experiments, it did not significantly increase the graders' suspicions of cheating. Based on our experiments, we provide recommendations for utilizing automatic grading systems more safely in practice.
I Do Not Understand What I Cannot Define: Automatic Question Generation With Pedagogically-Driven Content Selection
Oct 08, 2021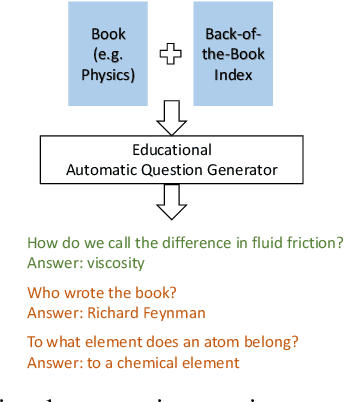
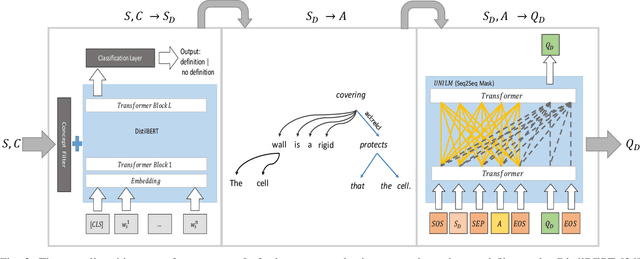
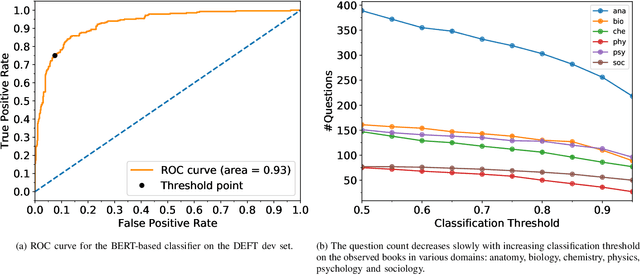
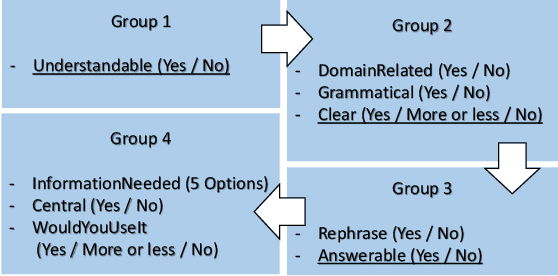
Most learners fail to develop deep text comprehension when reading textbooks passively. Posing questions about what learners have read is a well-established way of fostering their text comprehension. However, many textbooks lack self-assessment questions because authoring them is timeconsuming and expensive. Automatic question generators may alleviate this scarcity by generating sound pedagogical questions. However, generating questions automatically poses linguistic and pedagogical challenges. What should we ask? And, how do we phrase the question automatically? We address those challenges with an automatic question generator grounded in learning theory. The paper introduces a novel pedagogically meaningful content selection mechanism to find question-worthy sentences and answers in arbitrary textbook contents. We conducted an empirical evaluation study with educational experts, annotating 150 generated questions in six different domains. Results indicate a high linguistic quality of the generated questions. Furthermore, the evaluation results imply that the majority of the generated questions inquire central information related to the given text and may foster text comprehension in specific learning scenarios.