 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Synthetic Text Generation with Diffusion Models
Oct 30, 2024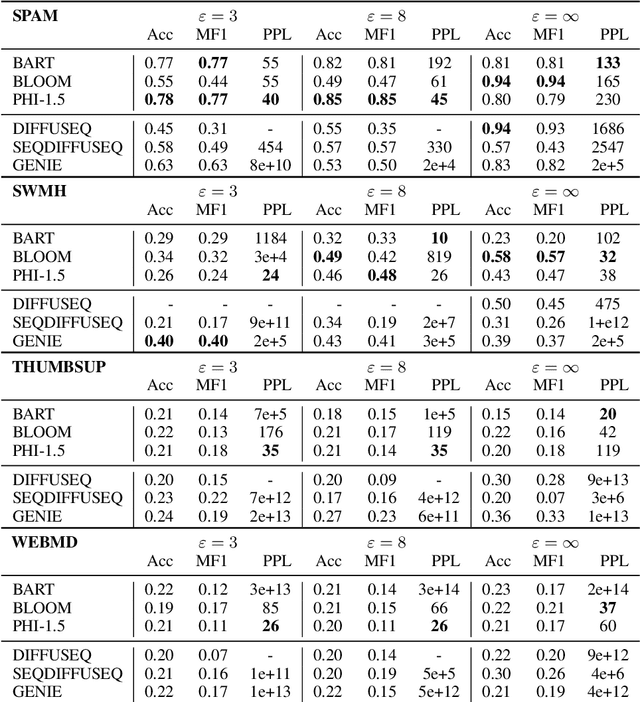

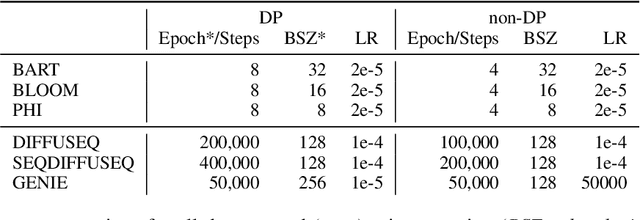
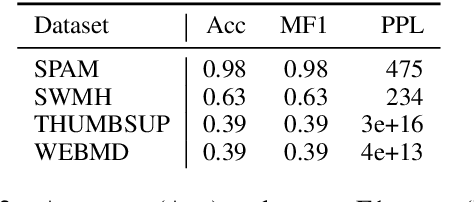
How capable are diffusion models of generating synthetics texts? Recent research shows their strengths, with performance reaching that of auto-regressive LLMs. But are they also good in generating synthetic data if the training was under differential privacy? Here the evidence is missing, yet the promises from private image generation look strong. In this paper we address this open question by extensive experiments. At the same time, we critically assess (and reimplement) previous works on synthetic private text generation with LLMs and reveal some unmet assumptions that might have led to violating the differential privacy guarantees. Our results partly contradict previous non-private findings and show that fully open-source LLMs outperform diffusion models in the privacy regime. Our complete source codes, datasets, and experimental setup is publicly available to foster future research.
Cheating Automatic Short Answer Grading: On the Adversarial Usage of Adjectives and Adverbs
Jan 20, 2022Automatic grading models are valued for the time and effort saved during the instruction of large student bodies. Especially with the increasing digitization of education and interest in large-scale standardized testing, the popularity of automatic grading has risen to the point where commercial solutions are widely available and used. However, for short answer formats, automatic grading is challenging due to natural language ambiguity and versatility. While automatic short answer grading models are beginning to compare to human performance on some datasets, their robustness, especially to adversarially manipulated data, is questionable. Exploitable vulnerabilities in grading models can have far-reaching consequences ranging from cheating students receiving undeserved credit to undermining automatic grading altogether - even when most predictions are valid. In this paper, we devise a black-box adversarial attack tailored to the educational short answer grading scenario to investigate the grading models' robustness. In our attack, we insert adjectives and adverbs into natural places of incorrect student answers, fooling the model into predicting them as correct. We observed a loss of prediction accuracy between 10 and 22 percentage points using the state-of-the-art models BERT and T5. While our attack made answers appear less natural to humans in our experiments, it did not significantly increase the graders' suspicions of cheating. Based on our experiments, we provide recommendations for utilizing automatic grading systems more safely in practice.