 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Synthetic Text Generation with Diffusion Models
Paper and Code
Oct 30, 2024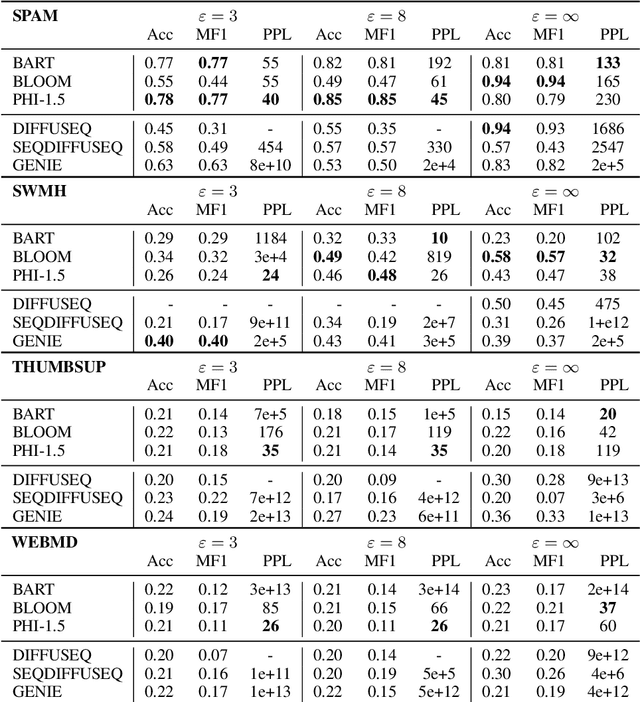

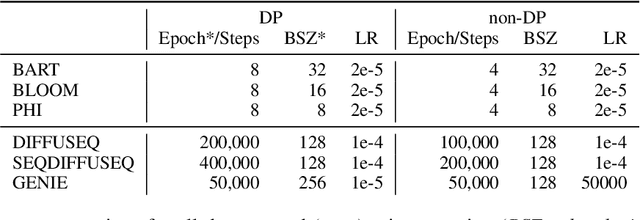
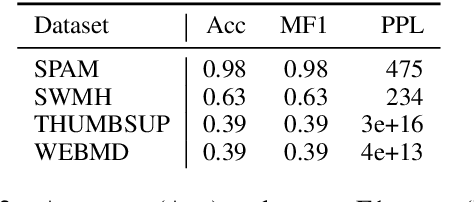
How capable are diffusion models of generating synthetics texts? Recent research shows their strengths, with performance reaching that of auto-regressive LLMs. But are they also good in generating synthetic data if the training was under differential privacy? Here the evidence is missing, yet the promises from private image generation look strong. In this paper we address this open question by extensive experiments. At the same time, we critically assess (and reimplement) previous works on synthetic private text generation with LLMs and reveal some unmet assumptions that might have led to violating the differential privacy guarantees. Our results partly contradict previous non-private findings and show that fully open-source LLMs outperform diffusion models in the privacy regime. Our complete source codes, datasets, and experimental setup is publicly available to foster future research.