 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
VideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
Jan 08, 2026Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal large language models on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.
MobileLLM-Pro Technical Report
Nov 10, 2025Efficient on-device language models around 1 billion parameters are essential for powering low-latency AI applications on mobile and wearable devices. However, achieving strong performance in this model class, while supporting long context windows and practical deployment remains a significant challenge. We introduce MobileLLM-Pro, a 1-billion-parameter language model optimized for on-device deployment. MobileLLM-Pro achieves state-of-the-art results across 11 standard benchmarks, significantly outperforming both Gemma 3-1B and Llama 3.2-1B, while supporting context windows of up to 128,000 tokens and showing only minor performance regressions at 4-bit quantization. These improvements are enabled by four core innovations: (1) implicit positional distillation, a novel technique that effectively instills long-context capabilities through knowledge distillation; (2) a specialist model merging framework that fuses multiple domain experts into a compact model without parameter growth; (3) simulation-driven data mixing using utility estimation; and (4) 4-bit quantization-aware training with self-distillation. We release our model weights and code to support future research in efficient on-device language models.
Self-Vocabularizing Training for Neural Machine Translation
Mar 19, 2025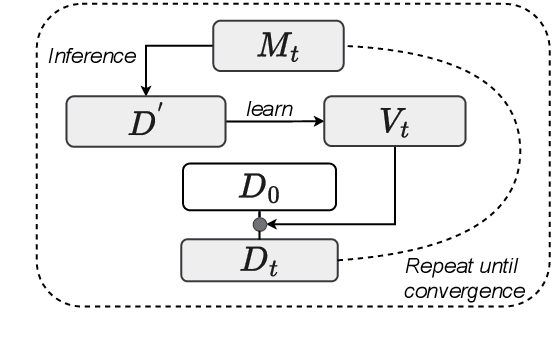

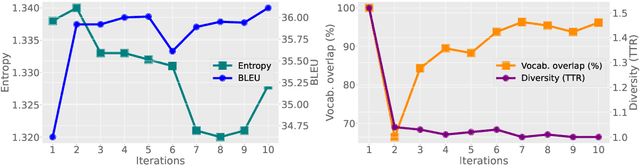

Past vocabulary learning techniques identify relevant vocabulary before training, relying on statistical and entropy-based assumptions that largely neglect the role of model training. Empirically, we observe that trained translation models are induced to use a byte-pair encoding (BPE) vocabulary subset distinct from the original BPE vocabulary, leading to performance improvements when retrained with the induced vocabulary. In this paper, we analyze this discrepancy in neural machine translation by examining vocabulary and entropy shifts during self-training--where each iteration generates a labeled dataset by pairing source sentences with the model's predictions to define a new vocabulary. Building on these insights, we propose self-vocabularizing training, an iterative method that self-selects a smaller, more optimal vocabulary, yielding up to a 1.49 BLEU improvement. Moreover, we find that deeper model architectures lead to both an increase in unique token usage and a 6-8% reduction in vocabulary size.
Agent-as-a-Judge: Evaluate Agents with Agents
Oct 14, 2024



Contemporary evaluation techniques are inadequate for agentic systems. These approaches either focus exclusively on final outcomes -- ignoring the step-by-step nature of agentic systems, or require excessive manual labour. To address this, we introduce the Agent-as-a-Judge framework, wherein agentic systems are used to evaluate agentic systems. This is an organic extension of the LLM-as-a-Judge framework, incorporating agentic features that enable intermediate feedback for the entire task-solving process. We apply the Agent-as-a-Judge to the task of code generation. To overcome issues with existing benchmarks and provide a proof-of-concept testbed for Agent-as-a-Judge, we present DevAI, a new benchmark of 55 realistic automated AI development tasks. It includes rich manual annotations, like a total of 365 hierarchical user requirements. We benchmark three of the popular agentic systems using Agent-as-a-Judge and find it dramatically outperforms LLM-as-a-Judge and is as reliable as our human evaluation baseline. Altogether, we believe that Agent-as-a-Judge marks a concrete step forward for modern agentic systems -- by providing rich and reliable reward signals necessary for dynamic and scalable self-improvement.
Scaling Parameter-Constrained Language Models with Quality Data
Oct 04, 2024



Scaling laws in language modeling traditionally quantify training loss as a function of dataset size and model parameters, providing compute-optimal estimates but often neglecting the impact of data quality on model generalization. In this paper, we extend the conventional understanding of scaling law by offering a microscopic view of data quality within the original formulation -- effective training tokens -- which we posit to be a critical determinant of performance for parameter-constrained language models. Specifically, we formulate the proposed term of effective training tokens to be a combination of two readily-computed indicators of text: (i) text diversity and (ii) syntheticity as measured by a teacher model. We pretrained over $200$ models of 25M to 1.5B parameters on a diverse set of sampled, synthetic data, and estimated the constants that relate text quality, model size, training tokens, and eight reasoning task accuracy scores. We demonstrated the estimated constants yield +0.83 Pearson correlation with true accuracies, and analyzed it in scenarios involving widely-used data techniques such as data sampling and synthesis which aim to improve data quality.
High Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching
Jul 04, 2024



We introduce a simple and efficient text-controllable high-fidelity music generation and editing model. It operates on sequences of continuous latent representations from a low frame rate 48 kHz stereo variational auto encoder codec that eliminates the information loss drawback of discrete representations. Based on a diffusion transformer architecture trained on a flow-matching objective the model can generate and edit diverse high quality stereo samples of variable duration, with simple text descriptions. We also explore a new regularized latent inversion method for zero-shot test-time text-guided editing and demonstrate its superior performance over naive denoising diffusion implicit model (DDIM) inversion for variety of music editing prompts. Evaluations are conducted on both objective and subjective metrics and demonstrate that the proposed model is not only competitive to the evaluated baselines on a standard text-to-music benchmark - quality and efficiency-wise - but also outperforms previous state of the art for music editing when combined with our proposed latent inversion. Samples are available at https://melodyflow.github.io.
Basis Selection: Low-Rank Decomposition of Pretrained Large Language Models for Target Applications
May 24, 2024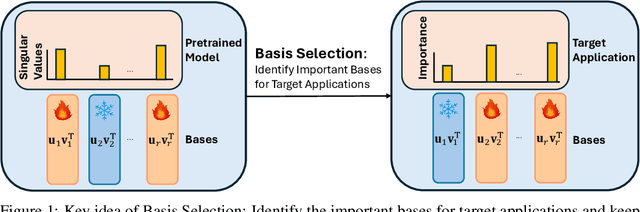
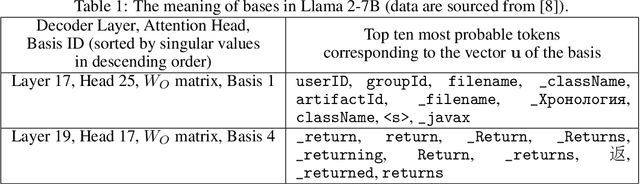
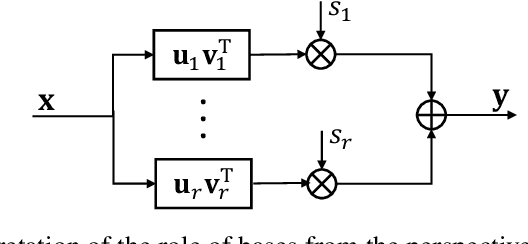
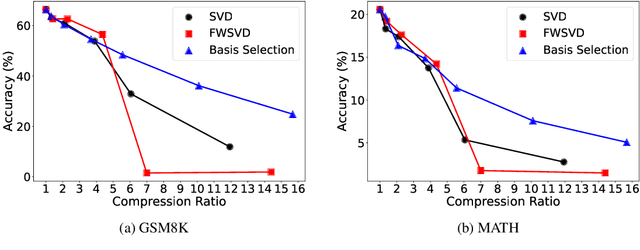
Large language models (LLMs) significantly enhance the performance of various applications, but they are computationally intensive and energy-demanding. This makes it challenging to deploy them on devices with limited resources, such as personal computers and mobile/wearable devices, and results in substantial inference costs in resource-rich environments like cloud servers. To extend the use of LLMs, we introduce a low-rank decomposition approach to effectively compress these models, tailored to the requirements of specific applications. We observe that LLMs pretrained on general datasets contain many redundant components not needed for particular applications. Our method focuses on identifying and removing these redundant parts, retaining only the necessary elements for the target applications. Specifically, we represent the weight matrices of LLMs as a linear combination of base components. We then prune the irrelevant bases and enhance the model with new bases beneficial for specific applications. Deep compression results on the Llama 2-7b and -13B models, conducted on target applications including mathematical reasoning and code generation, show that our method significantly reduces model size while maintaining comparable accuracy to state-of-the-art low-rank compression techniques.
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
Feb 22, 2024This paper addresses the growing need for efficient large language models (LLMs) on mobile devices, driven by increasing cloud costs and latency concerns. We focus on designing top-quality LLMs with fewer than a billion parameters, a practical choice for mobile deployment. Contrary to prevailing belief emphasizing the pivotal role of data and parameter quantity in determining model quality, our investigation underscores the significance of model architecture for sub-billion scale LLMs. Leveraging deep and thin architectures, coupled with embedding sharing and grouped-query attention mechanisms, we establish a strong baseline network denoted as MobileLLM, which attains a remarkable 2.7%/4.3% accuracy boost over preceding 125M/350M state-of-the-art models. Additionally, we propose an immediate block-wise weight sharing approach with no increase in model size and only marginal latency overhead. The resultant models, denoted as MobileLLM-LS, demonstrate a further accuracy enhancement of 0.7%/0.8% than MobileLLM 125M/350M. Moreover, MobileLLM model family shows significant improvements compared to previous sub-billion models on chat benchmarks, and demonstrates close correctness to LLaMA-v2 7B in API calling tasks, highlighting the capability of small models for common on-device use cases.
Not All Weights Are Created Equal: Enhancing Energy Efficiency in On-Device Streaming Speech Recognition
Feb 20, 2024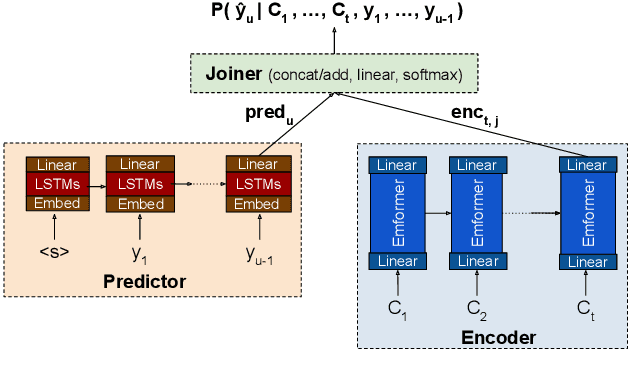
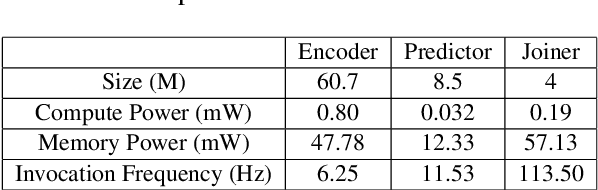
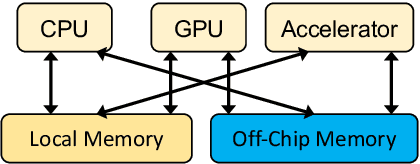
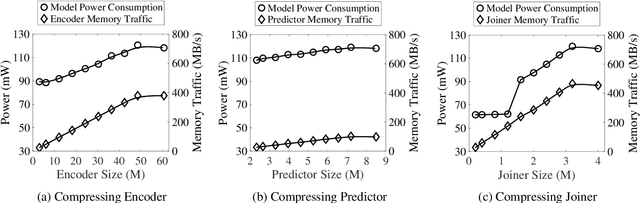
Power consumption plays an important role in on-device streaming speech recognition, as it has a direct impact on the user experience. This study delves into how weight parameters in speech recognition models influence the overall power consumption of these models. We discovered that the impact of weight parameters on power consumption varies, influenced by factors including how often they are invoked and their placement in memory. Armed with this insight, we developed design guidelines aimed at optimizing on-device speech recognition models. These guidelines focus on minimizing power use without substantially affecting accuracy. Our method, which employs targeted compression based on the varying sensitivities of weight parameters, demonstrates superior performance compared to state-of-the-art compression methods. It achieves a reduction in energy usage of up to 47% while maintaining similar model accuracy and improving the real-time factor.